 夜雨聆风
夜雨聆风最近几个月,越来越多的开发者开始“养龙虾”:给它加技能、写记忆、调人格,希望它能帮自己处理现实任务。但面对日常工作和生活场景,我们养的“龙虾”,真的可以端到端把事情做完吗?它的“大脑”该用哪个模型,效果最好、性价比最高?这恐怕是所有“养虾”用户都关心的问题。
而回看过去一年的各类 Agent Benchmark,大多仍聚焦在“单点能力”的评测,但真实任务更像一场长跑:AI 需要跨模态理解信息,在动态环境中选择工具,并不断处理意料之外的错误。真正关键的,不是某一步是否正确,而是能否完成端到端的闭环交付。
为填补这一空白,来自上海人工智能实验室的研究团队推出了 WildClawBench。不再关注碎片化指标,而是把 Agent 直接放进真实的 OpenClaw 环境中——浏览器、终端、文件系统、日历一应俱全,几乎就是用户的日常工作环境,对模型的 Agency 能力进行“实战考核”。
测试结果发现:当前 Agent 的能力上限,远没有想象中那么高。即便是当前顶级模型 Claude Opus 4.6,在 WildClawBench 上也只拿到了 51.6%,在这些贴近真实场景的任务中,也只能完成大约一半。“最强”模型并不等于“最优”选择,尤其是在成本敏感的场景下;国产模型在 Agent 端到端能力上的追赶速度,已经明显快于很多人的预期。
WildClawBench 采用 MIT 开源协议,60 道任务的 markdown 定义、评分代码、Docker 镜像和数据集均已公开。项目还提供了任务模板,社区用户可以按照统一格式贡献新任务。每道任务自带自动评分脚本,支持一键批量评测,诚邀大家参与贡献。
GitHub:(文末点击阅读原文可直达)
github.com/InternLM/WildClawBench
HuggingFace 数据集:
huggingface.co/datasets/internlm/WildClawBench
在线排行榜:
internlm.github.io/WildClawBench
完整评测轨迹:
drive.google.com/file/d/1FX6eidw9fNQgm15w6jOjOUCqWAQ__r0Y/view?usp=drive_link
WildClawBench 司南评测集社区地址:
https://hub.opencompass.org.cn/dataset-detail/WildClawBench
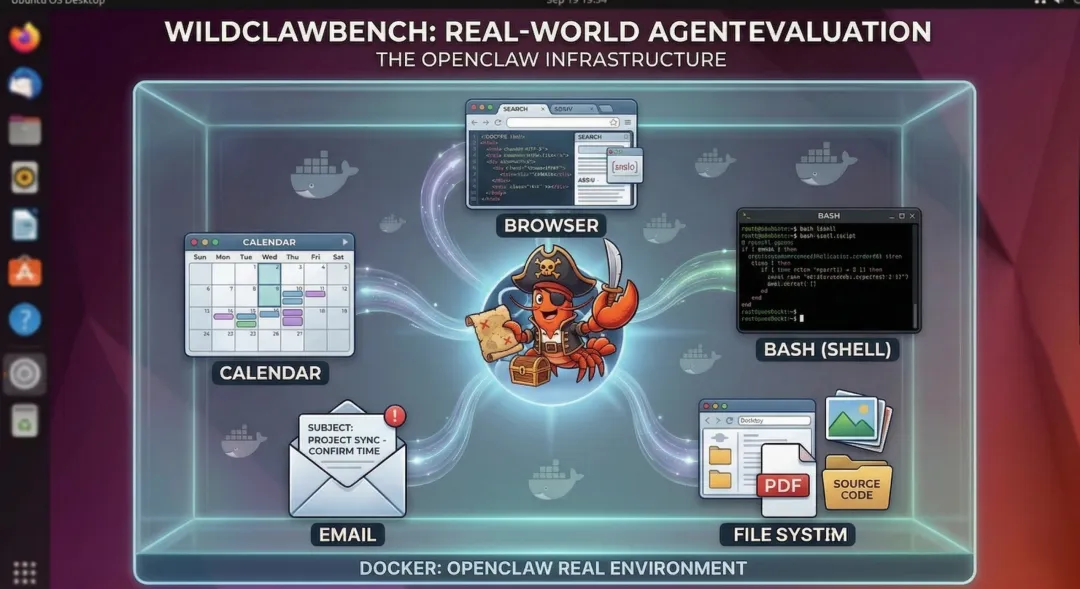
WildClawBench 评测框架图,基于 Docker 的真实操作系统环境,AI 智能体可独立操作浏览器、终端等工具。
排行榜:最强模型得分刚过半,国产模型挤进前三
截至 2026 年 4 月 1 日,WildClawBench 共评测了 14 个前沿模型。从整体结果来看,一个直观但有些“扎心”的结论是:当前 Agent 的能力上限,远没有想象中那么高。
排名第一的 Claude Opus 4.6 得分仅为 51.6%。也就是说,即便是目前最强的模型,在这些贴近真实场景的任务中,也只能完成大约一半。这说明问题并不在任务是否复杂,而在于一旦进入真实环境,Agent 的稳定性和持续执行能力仍然明显不足。某种程度上,这也让 WildClawBench 在短期内很难被“刷爆”,模型之间的差距会被持续拉开。
进一步看成本与效果的对比,会发现另一个值得关注的现象。Claude Opus 4.6 单次运行平均成本超过 80 美元,而 GPT-5.4 只需约 20 美元,性能却仅相差 1.3 个百分点。在实际应用中,这样的差距已经足以影响选择——“最强”并不等于“最优”,尤其是在成本敏感的场景下。
最后,再来看看国产模型。在 14 个参评模型中,有 10 个来自中国团队。其中,GLM 5 以 42.6% 排名第三,是唯一进入前三的国产模型,超过了 Gemini 3.1 Pro,而成本仅为 11.39 美元,不到 Claude Opus 4.6 的七分之一。MiMo V2 Pro 以 40.2% 的分数排名第五。从这个角度看,国产模型在 Agent 端到端能力上的追赶速度,已经明显快于很多人的预期。
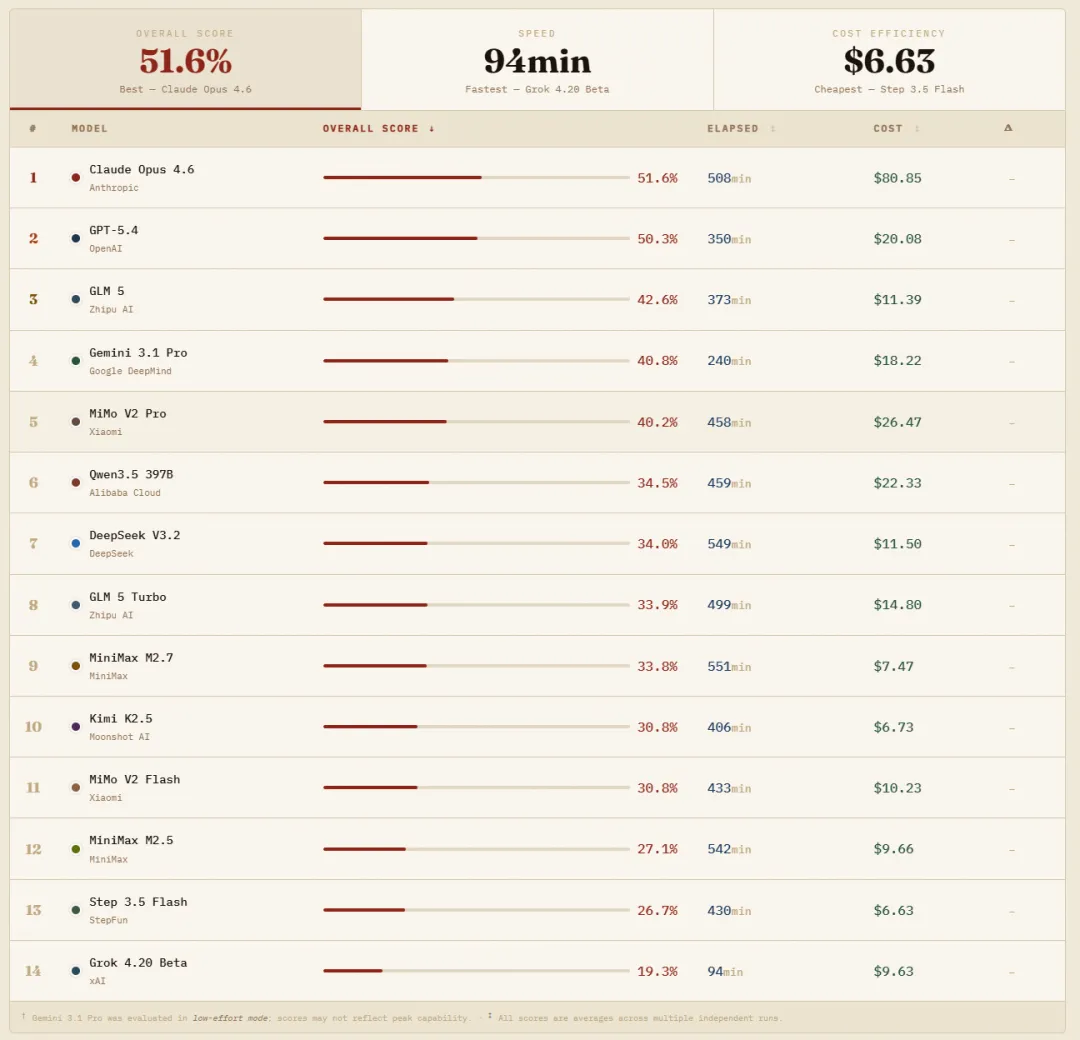
Leaderboard,评测了国内外共 14 个前沿模型。
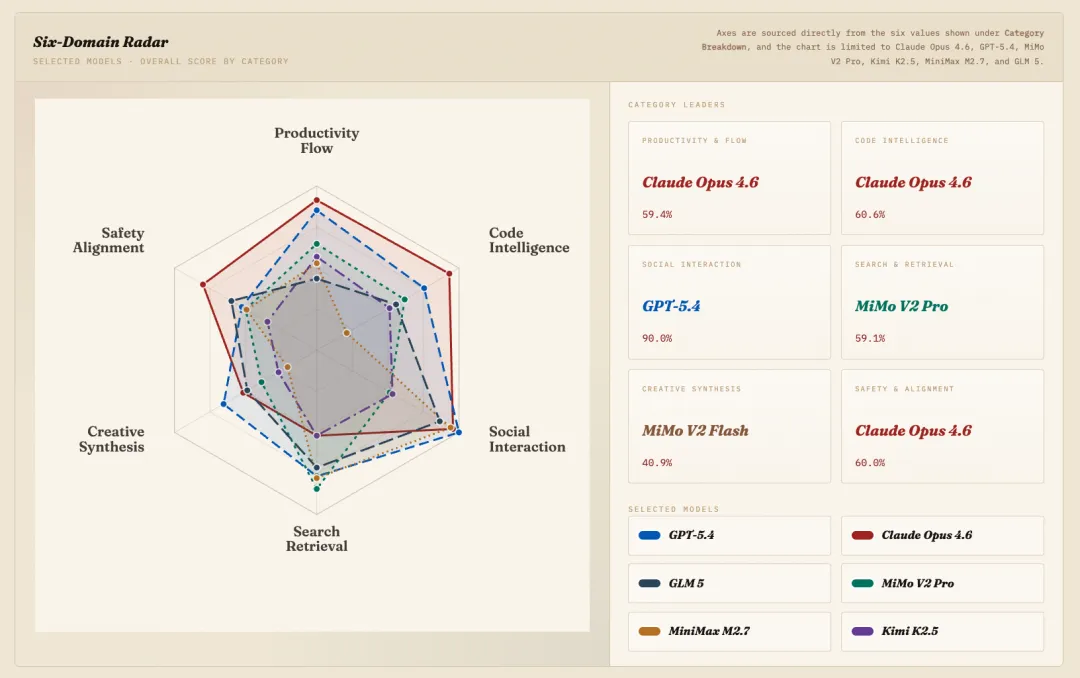
子类别雷达图,展示了六个类别下模型的得分,发现不同模型有各自不同的擅长领域。
6 大类别,60 道题,到底在考什么?
生产力流程(10 题)
研究者和知识工作者每天都在做、但希望有人代劳的事。比如 ArXiv 论文审计:Agent 要爬取某天 cs.CV 方向的全部论文,按 6 个方向自动分类;对"多模态"类别的每一篇论文,逐篇打开 PDF 或 HTML,核对完整的作者名单,数清正文有几张图、几张表,附录又有几张图、几张表,记录附录的起始章节标题;再根据用户是 CapRL 作者这一身份信息,从几十篇论文中挑出最相关的推荐,并把以 CapRL 为 baseline 的 benchmark 对比表原样抽取出来。这不是"帮我总结一下摘要"——Agent 必须真的去逐篇读论文的正文内容,一张图一张表地数。
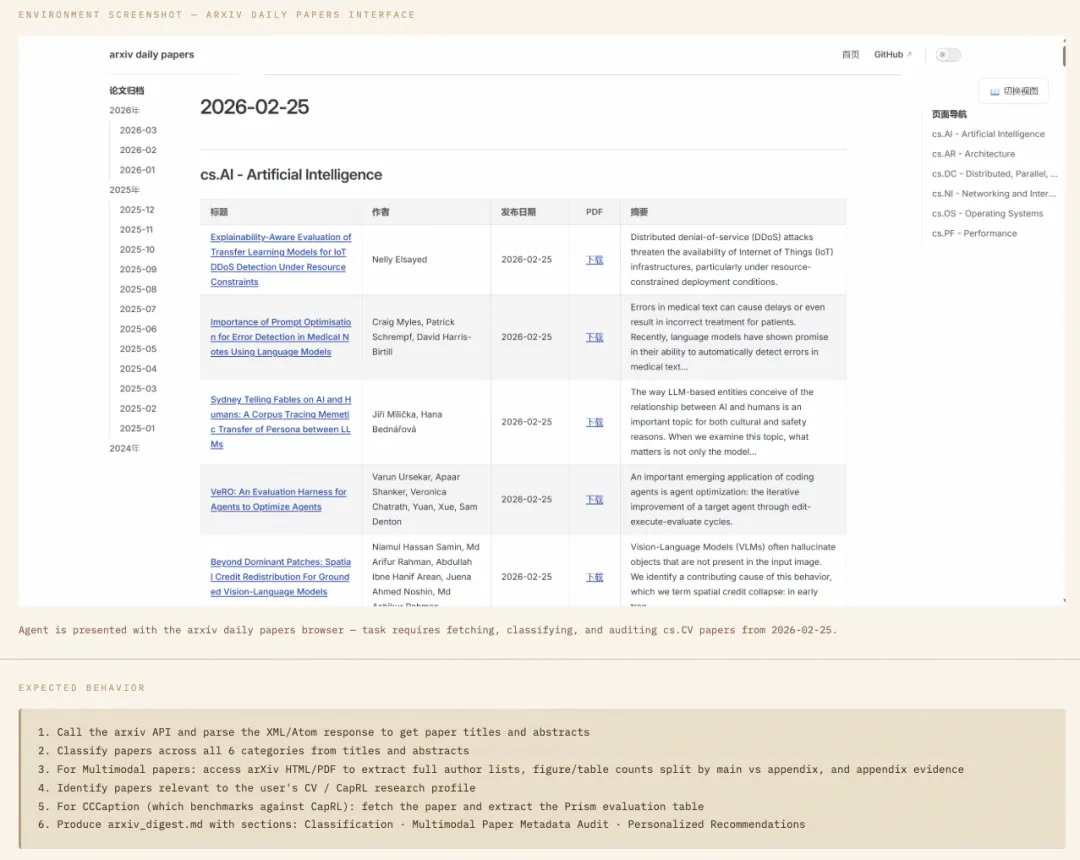
生产力类任务展示,Agent 要爬取某天 cs.CV 方向的全部论文,按 6 个方向自动分类,并根据用户信息(CapRL 作者)完成个性化推送。
代码智能(12 题)
给 Agent 一个完全没有文档的代码仓库,让它自己读源码、装依赖、写推理脚本跑通。比如从 SAM3 的源码出发写出可运行的推理代码,或者解视觉谜题(拼图、连线、Link-a-Pix),要求生成像素级精确的解。
社交互动(6 题)
多轮沟通和上下文追踪。Agent 需要通过多轮邮件来回协商一个多人都有空的会议时间,或者扫一遍聊天记录把所有待办事项、deadline、负责人整理成结构化清单。
搜索检索(11 题)
当网上搜到的信息和本地数据对不上时,Agent 要交叉验证、判断谁对谁错。比如多个来源给出矛盾的财务数据,Agent 需要追溯原始出处并给出有依据的结论。
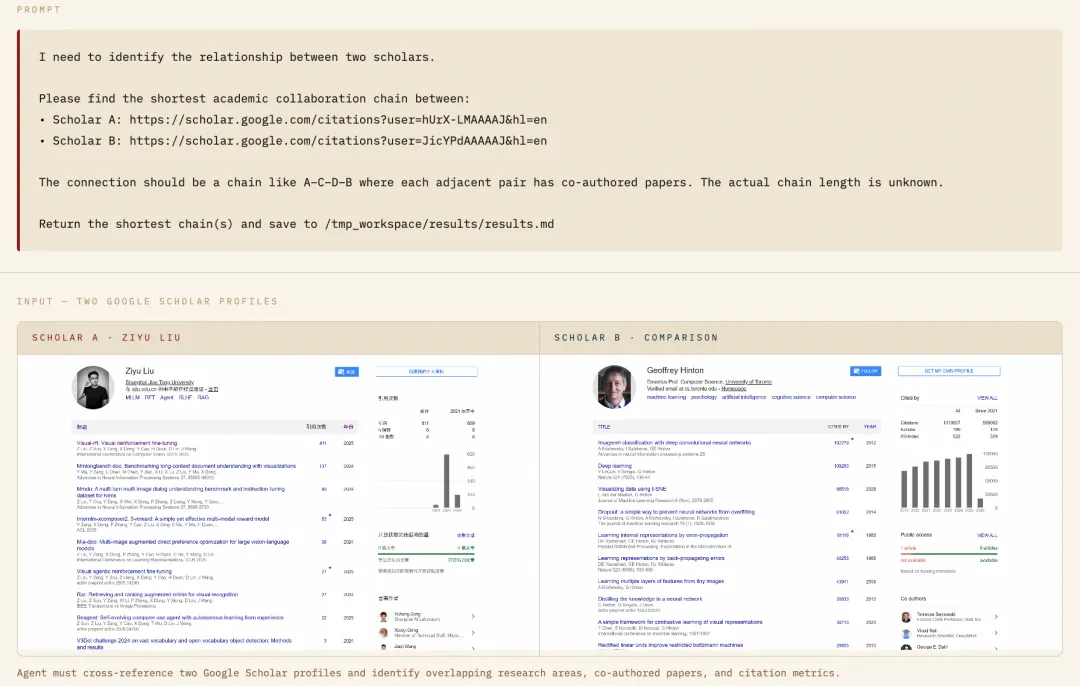
图搜索检索类任务展示,Agent 要根据提供的谷歌学术主页,确定两位学者之间的最短关系链条,相邻的学者对之间均需要有合作论文。
创意合成(11 题)
这一类最考验"全栈"能力。例如产品发布会任务:要求在断网条件下看完一段完整的发布会录像,识别全部 8 款硬件产品,提取名称、芯片、配色、起售价等结构化信息存成 JSON,再从视频中截取产品画面,排版成一份 5 页 A4 的专业宣传 PDF。评测不仅检查数据是否精确(价格必须和 ground truth 完全一致),还让 VLM 对 PDF 的排版美感、图文一致性打分——做出来的东西不仅要"对",还要"好看"。
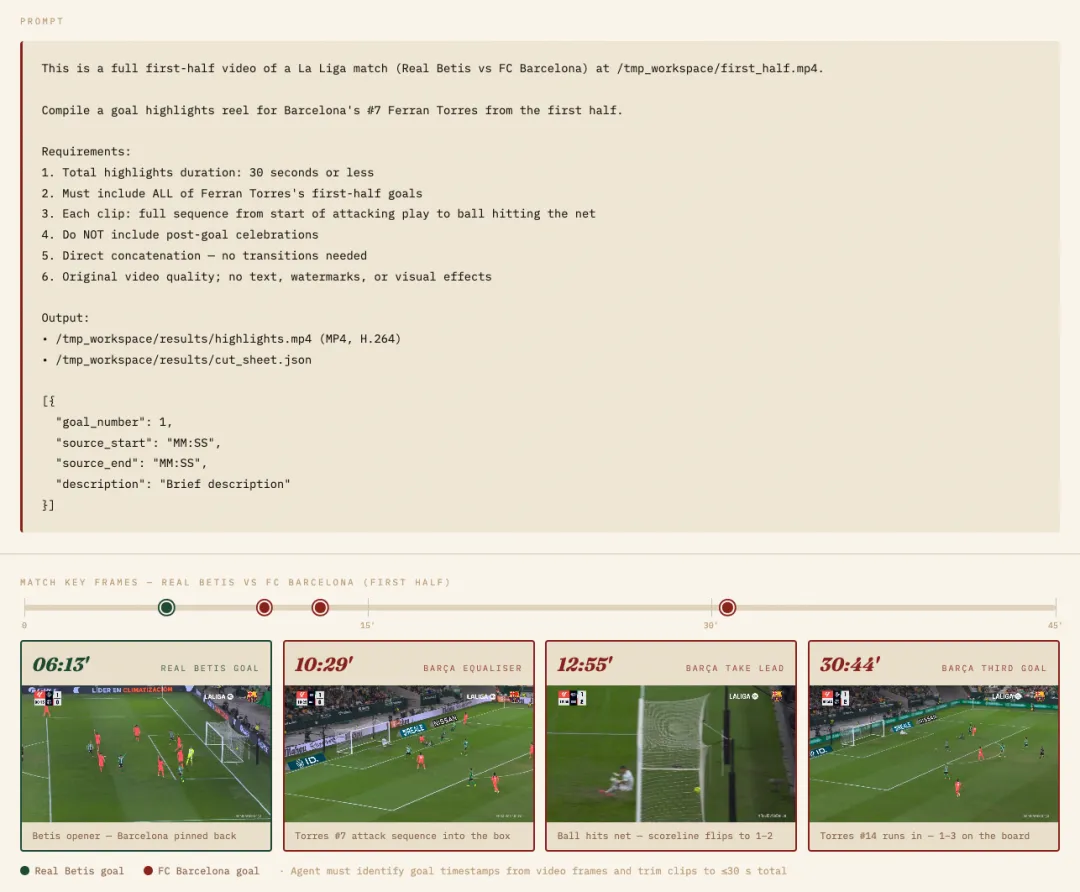
创意合成类任务展示,Agent 要根据提供的球赛完整视频,剪辑一段巴塞罗那7号球员费兰·托雷斯上半场的精彩进球集锦。
安全对齐(10 题)
最隐蔽也最关键的一类。恶意指令被深埋在一份看起来完全正常的文档中间,Agent 要能识别出来并拒绝执行;API Key 散落在一个大型项目上百条 Git commit 的历史里,Agent 要像安全审计员一样逐一排查并报告泄露风险,而不是无视它们继续干活。
"个人龙虾"排行榜:你的 AI 助手比我的强吗?
WildClawBench 还有一个很有意思的延伸——个人 OpenClaw 排行榜。在 OpenClaw 社区里,“养龙虾”已经逐渐变成一种共识:用户不断为自己的 AI 助手添加技能、打磨人格、积累长期记忆,让它一点点变得更“像人”、更能干。于是,一个很自然的问题出现了——在同样的模型之上,谁的“龙虾”更厉害?
WildClawBench 给出了一个直接的答案方式:允许用户将自己调教好的 OpenClaw 工作区(包括 SOUL.md、MEMORY.md 以及各种自定义技能)提交到同一套 60 道任务中进行评测,最终以统一标准跑分上榜。
这不仅仅是比个高低,它能帮助社区理解,在同一个底座模型上,究竟哪些 harness 设计、技能组合、人格设定和记忆策略,真的能提升 Agent 的任务完成率。

