 夜雨聆风
夜雨聆风背景:产能的短板在质量
目前来看 AI 的能力越来越强大,能够快速产出代码。但代码量爆炸后,人类很难逐行「肉眼」保证质量。按木桶原理,代码质量上不去会成为整条产线的短板:返工、线上事故、不敢发布,最终产能反而被拖住。
这种拖住往往不是「大家不够努力」,而是结构问题:评审变成扫一眼 diff、回归靠几个人手点几条主路径、每次发版前夜都在赌「应该没事」。合并队列越长,冲突越多;热修越多,主干越不稳定,新功能越不敢合进去——看起来像产能问题,根子经常在不可验证的变更上。
因此需要把测试体系做起来——不是为了写测试而写测试,而是为了可验证的行为、可重复的回归、可发布的信心。
一、为什么需要测试
1. 验证承诺,而不只是「能跑」
测试本质上在验证软件是否守住几类承诺:
- 正确性
:是否做了该做的事(需求、业务规则)。 - 可靠性
:在变更、负载、边界条件下是否稳定。 - 安全性 / 合规
:敏感数据、权限、审计是否不被破坏。
「能跑」往往只说明主路径在某台机器、某种数据、某个时间点没崩;它不包括边界(金额为 0、库存为负、重复提交)、不包括并发下的顺序、也不包括「删了一条记录后列表缓存是否一致」这类业务细节。自动化验证的价值,是把可重复的质疑写进机器里:同一份输入,每次跑都得到同一套可核对的结论。
没有自动化验证时,这些只能靠记忆和手工回归,不可扩展。
2. 缺陷成本随阶段指数上升(左移的价值)
业界常见表述是:在开发期修复的成本远低于测试期,更远低于生产环境(具体倍数因团队而异,但「越晚越贵」是共识)。测试(尤其是自动化)把问题暴露在合并前,减少救火和夜间发布。
链条大致是这样:开发在 IDE 里修,上下文全在脑子里;测试环境复现要搭数据、对齐版本;到了生产,往往还要客服沟通、写事故报告、做数据修复或回滚——同一条逻辑错误,后面的每一步都在叠加沟通与风险。自动化并不是消灭 bug,而是把大量 bug 提前变成一次失败的 CI,让修复发生在便宜的那一端。
3. 回归与重构的安全网
任何持续演进的系统都会改代码。没有测试,「不敢动」会累积技术债;有测试,小步重构、替换实现(例如 AI 重写某段逻辑)才有对照标准。
AI 特别放大这一点:它可以在几分钟内给出「另一种写法」,语法漂亮、结构清晰,但语义是否与原实现一致,只能靠对照物。单测和契约测试就是那个对照物——不是不信任模型,而是不信任「没有约束的替换」在复杂系统里总能碰巧正确。
4. 可执行的规格(Living documentation)
好的测试用例描述「系统在某种输入下应如何表现」,比注释和口头约定更不容易过期——前提是测试与需求同步维护。
反过来,测试如果长期不随需求改,会变成反向的误导:新人读用例以为系统仍支持旧规则,实际上代码早已分叉。Living documentation 不是自动成立的,它需要把「改需求」和「改测试」绑在同一套流程里(评审、任务拆分、CI 红绿),否则它只是另一种形式的文档腐烂。
5. 对管理与协作:风险与节奏
自动化测试与 CI 结合后,能支撑更频繁的集成与发布决策,减少「人肉卡点」。对业务方而言,测试是风险与质量的可视化,而不只是开发内部事务。
当质量信号是可量化、可追溯的(哪些路径被覆盖、最近一次绿是什么时候、失败率里 flaky 占多少),「能不能发」可以从拍脑袋变成有依据的协商:不是测试部门挡业务,而是大家对着同一套证据讨论取舍。
二、测试分层:单元与 E2E 各自解决什么
| 单元测试 | |||
| 集成 / 契约测试 | |||
| E2E(端到端) |
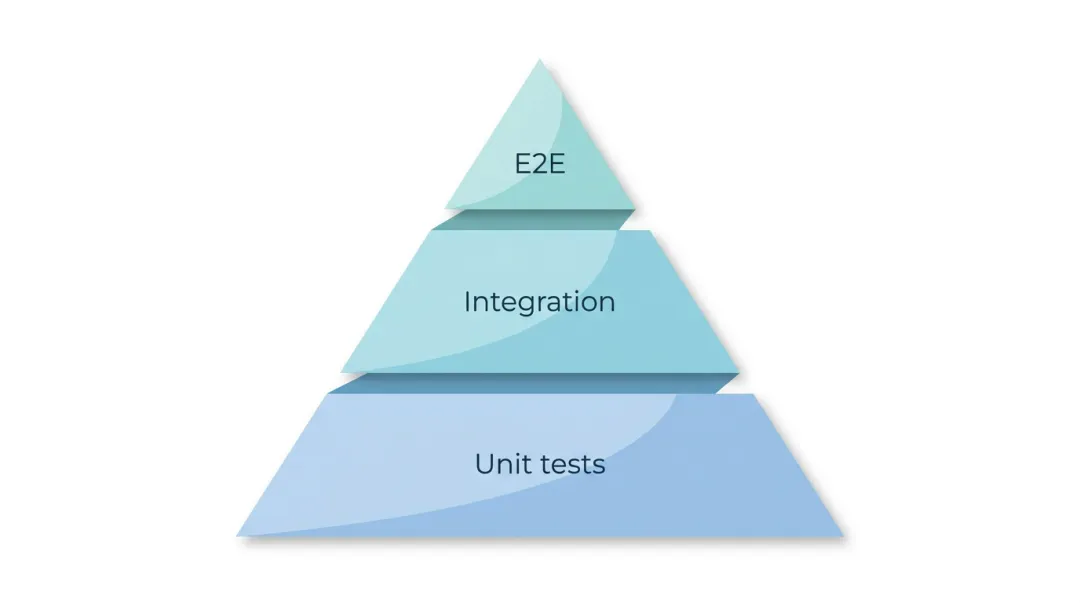
实践上:金字塔结构——大量快速单测 + 适量集成 + 少量高价值 E2E,而不是倒金字塔全靠 E2E。
单测适合把业务规则、边界、错误分支钉死:例如计费、权限判定、状态机迁移。集成层适合抓「接线」问题:SQL 写对了但事务边界错了、消息发了但消费者幂等没做到、HTTP 契约字段悄悄改名。E2E 适合验证整条链路的用户价值:登录后能完成一笔闭环操作——它贵,所以通常只买在少数「断了就赔不起」的路径上。
团队有时会不知不觉长成倒金字塔:E2E 多、单测少,往往是因为「看得见」——录一段浏览器比写纯函数测试更直观,短期也更有成就感。长期代价是 CI 变慢、定位变慢:一红就要从整站路径里猜是哪一环松了。金字塔不是在论文里好看,是在高频提交下还能不能保持信号干净的问题。
三、AI 时代怎么把测试做好

AI 改变了「写代码」的速度,但没有改变「系统必须可验证」的事实;反而因为变更更快、代码更多,验证与约束变得更加重要。以前一周合并几十次,现在可能一天就几十次;同样的 flaky 比例,在更高频的提交下会更快把 CI 变成「习惯性忽略红」的噪声源。
1. 人机分工:AI 加速「生成」,人负责「定义对与错」
- 人
:明确验收标准、边界条件、安全与合规红线;决定哪些路径必须 E2E 覆盖。 - AI
:辅助生成单测、测试数据、Boilerplate;辅助从需求/接口文档生成测试草稿。 - 原则
:AI 生成的测试必须经过人类可读性检查和失败是否有意义的审查,避免为覆盖率而测。
「有意义」的失败指:红灯出现时,你能说出哪条业务规则被破坏了,而不是只看到某个 mock 返回值被改坏了、或断言写得太脆。AI 很擅长补全 describe/it 的骨架,但断言到底对齐哪一句需求,仍然需要人来对齐语义。
2. 把「规格」前置:契约、示例、属性
- API / 契约测试
:接口不变形,前后端与 AI 改实现都有据可依。 - 示例驱动
:Given-When-Then、表格化用例,便于人和 AI 对齐语义。 - 属性测试(Property-based)
:对复杂逻辑用「不变量」描述,比穷举例子更抗 AI 乱改。
契约特别适合多人多仓库协作:接口是显式的「接缝」,改字段名、改错误码格式,契约测试会先红,而不是等到前端联调才爆。属性测试则适合那种「规则很难用几个例子说全」的领域:排序稳定性、金额守恒、幂等等——你写的是对所有合法输入都要成立的性质,而不是穷举业务同事能想到的三个例子。
3. CI 与质量门禁
合并前跑单测 + 关键集成/E2E;失败即阻断。 关注 flaky 测试:AI 时代提交频率高,不稳定测试会快速拖垮信任。
Flaky 的恶性循环很具体:同一测试有时红有时绿,大家开始「重跑就好」;重跑成为习惯后,真的回归就被埋掉了。高频提交下,治理 flaky 的成本反而应该前置:给等待条件、去掉硬 sleep、隔离测试数据、必要时降低并行度——这些都不是「洁癖」,是在保 CI 的可信度。
4. 若系统在卖「AI 能力」:还要测模型与管线
传统软件测「输出是否等于预期」;LLM 应用往往非确定性,需要另一套手段:
- 评测集与金标
:固定输入集合 + 人工或规则打分,做回归对比。 - LLM-as-judge
需谨慎:用于排序/粗筛可以,关键结论要有程序化指标或人审兜底。 - 护栏
:敏感词、越权、注入、幻觉场景要单独用例集。
例如 RAG:模型本身可能很稳,但检索切错文档、引用过期政策,用户看到的答案仍然错——这类问题要在管线级别测:给定文档集合与问题,答案是否落在允许片段内、引用是否可追溯。纯「输出像不像人话」不够。
5. 警惕 AI 测试的盲区
- 幻觉与偏见
:生成用例可能遗漏真实业务边角。 - 过度 mock
:测不到真实集成问题。 - 合规
:日志与数据中是否含 PII,需在测试环境里约定清楚。
AI 生成的用例往往偏向「主路径 + 常见异常」,而真实世界的问题常出在权限组合、历史数据脏、第三方超时、部分失败——这些需要业务输入清单,而不是指望模型凭空补全。
四、E2E:Playwright 体系与落地
下面以 Playwright 为例(同类工具还有 Cypress、Selenium 等),说明如何做端到端测试:录制加速、稳定定位、人工定规格、工程化与排障。第四节后半融入微信公众号文章《人类如何协助 AI 完成 e2e 测试生成》中的可复用实操(原文链接),与上文「人审验收、预埋 data-testid」互补:那篇文章侧重 Agent 探路 + Helper 沉淀 + 业务断言,适合复杂后台与强交互页面。
E2E 说到底是:用浏览器把用户会走的路走一遍,看最后系统是不是你期望的状态。它和第二节的金字塔不矛盾——这里讲的是「这一层里具体怎么落地」,不是让你用 E2E 包打一切。
为什么常画成金字塔?底下宽、上面尖:单测便宜、跑得快,适合兜大量细节;E2E 牵涉环节多、跑得慢、还容易抖,只适合盖住「少了会出事」的少数路径。若什么都指望「打开浏览器跑一遍」,CI 迟早跑不动,大家也会开始不信红——这和第二节表格里「E2E 宜少而精」是对上的。
1. Playwright 是什么、适合做什么
- 跨浏览器
:Chromium / Firefox / WebKit 一套 API,可在配置里用 projects多浏览器并行(见官方 Test across all browsers)。 - Locator 自动等待与可重试
:对元素做可操作性检查(可见、可用等)后再点击,减少「睡一秒再点」的脆弱写法。 - 内置工具链
:Test Generator(录制)、Trace Viewer(失败追溯)、VS Code 扩展、UI Mode 等,官方文档统称为 Use Playwright's Tooling。
E2E 只覆盖少量高价值路径(登录、下单、核心工作流),与单测、接口测分工,避免全站 E2E 拖垮 CI。
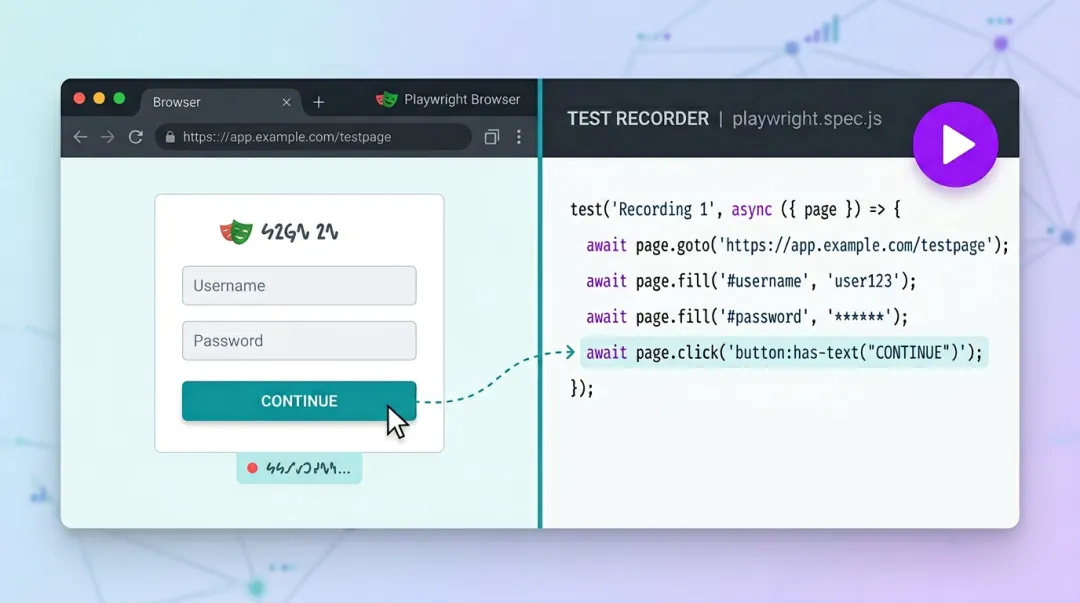
2. 录制与生成:codegen(不是「规格」,是「草稿」)
录制能快速得到操作序列与候选定位符,适合探索与初稿;验收标准仍应由人从需求或用户故事来写,再决定哪些步骤保留、哪些断言必须加。
常用入口:
npxplaywrightcodegen[URL]
敲完后一般会弹出两个窗口:左侧浏览器里正常操作(点击、填表、切页),右侧 Playwright Inspector 把操作翻译成测试代码。codegen 会优先生成 getByRole、getByPlaceholder、getByText 等语义化 locator,而不是一上来就写死深层 CSS / XPath(与官方 Test Generator 描述一致)。
实际工作里,codegen 更像速写:你先走一遍真实流程,确认「这条路走得通」,再回头删掉多余点击、补上「提交后列表多一行」这类业务断言。没有第二步,仓库里会堆满「能执行但不知道在验什么」的脚本。
行为要点:
工具栏可对元素做断言:Assert visibility → expect(locator).toBeVisible();Assert text →toHaveText();Assert value →toHaveValue()。停止录制后可用 Pick Locator:悬停元素看高亮 locator,复制进 spec;在 Inspector 里改 locator 可即时看到匹配个数。 - VS Code 扩展
支持 Record new / Record at cursor,在编辑器里录并落盘。
登录态复用(storage,减少重复登录)(实操常用):
# 先录一次登录,把 cookie/localStorage 存成文件
npxplaywrightcodegen--save-storage=auth.jsonhttps://your-site.com
# 之后录别的流程时带上,就不必每次从头登录
npxplaywrightcodegen--load-storage=auth.jsonhttps://your-site.com
正式跑测试时,也可在 playwright.config / globalSetup 里配合 storageState 复用登录态(见官方认证与 storage 文档)。
其他 CLI 选项(按需组合):-o 输出文件、--browser、--device、--viewport-size 等。
注意:录制产出的是实现草稿;合并进仓库前应删冗余步骤、补业务层断言、统一 locator 策略。
3. 复杂页面上 codegen 的常见问题(为什么还要 Helper / Agent)
简单页面「录完改改就能跑」;复杂业务里经常出现(文中总结的实操坑):
- 结构非语义化
:自定义 Tab 用 li/div堆出来,录到的 click 落在容器上而不是真实激活节点,一跑就偏。 - 遮挡与拦截
:按钮被浮层、Toast、遮罩挡住,录到的 click在 CI 里报 intercepted。 - 输入与联动
: fill()填了数字但不触发计算,需要 blur / Tab 才会跑后续逻辑,codegen 未必帮你录到「失焦」这一步。 - 弹窗顺序不稳定
:引导、免责、确认弹窗每次出现顺序或有无可能变化,录制把「某次手点关掉」全写进脚本,下次跑直接挂。
还有一种常见情况:异步列表:你录的时候数据已经回来了,脚本里没有等「某一行出现」就点编辑,CI 里网络慢一点就偶发失败——这类问题往往要显式 expect 等待业务就绪,而不是加长 timeout 碰运气。
因此:复杂页上录出来的长脚本常常是「一次性」的,仍要人工(或 Agent 反复试)把每一步调成稳定交互;最终把「页面的脾气」收进少量 Helper,而不是让每个 spec 复制粘贴一堆 if 弹窗、evaluate 点击、waitForTimeout。
4. 两阶段 workflow:Agent 探路 → Helper → 业务 spec(实操)
参考文中思路,可与「人手写 + codegen」并行,作为探路手段:
探路(可用 Agent 浏览器 / 自然语言驱动)
目标不是立刻得到可合并的终稿,而是搞清楚:真实用户路径怎么走?哪些按钮不能常规点?哪些输入必须失焦?哪些弹窗必须先关?成功后用什么业务事实做断言(接口数据、列表条数、指标变化)?沉淀 Helper
把探路得到的稳定做法写成函数:例如dismissBlockingDialogs、switchTab、fillAndBlur、clickPrimarySubmit、confirmAction。弹窗处理、Tab 用evaluate点叶子节点、fill后Tab等页面怪癖只维护在一处。Spec 只写业务编排
test里尽量是「清场 → 填参数 → 提交 → 确认 → 断言业务结果」,不堆 UI 细节。
Helper 与 spec 的职责拆分示例(逻辑摘自上文,可按项目改写):
// helpers/actions.ts — 页面怪癖封装在一处
exportasyncfunctiondismissBlockingDialogs(page:import('@playwright/test').Page) {
for (constselectorof ['.welcome-modal .close-btn', '.disclaimer-modal .agree-btn']) {
constel=page.locator(selector);
if (awaitel.isVisible({ timeout:2000 }).catch(() => false)) awaitel.click();
}
}
exportasyncfunctionfillAndBlur(page:import('@playwright/test').Page, selector:string, value:string) {
awaitpage.locator(selector).fill(value);
awaitpage.keyboard.press('Tab'); // 触发 blur / 联动计算
}
// xxx.spec.ts — 只保留业务步骤
test('提交操作', async ({ page }) => {
awaitdismissBlockingDialogs(page);
awaitfillAndBlur(page, '#price-input', '100');
// … 业务动作
// await expect(…). 断言列表、指标、接口落库等,而非仅「Toast 出现」
});
判断标准:未来会复用的动作进 Helper;只出现一次的可以留在单个 spec,避免过度抽象。
5. 稳定定位:优先用户可见语义,必要时 data-testid
官方 Best Practices 强调:测用户可见行为,优先 user-facing、明确的「契约」,而不是易变的实现细节(例如深层 CSS 类名)。推荐 locator 思路包括:
getByRole:按钮、链接、heading 等,与无障碍语义一致。 getByLabel/getByPlaceholder:表单。 getByText:稳定、用户可见的文案(若文案常变则慎用)。 getByTestId:对应 DOM 上的测试专用属性,适合列表项、无文案结构、动态文案等场景。
典型写法示例(语义优先):
awaitpage.getByRole('button', { name:'submit' }).click();
awaitpage.getByTestId('checkout-submit').click();
何时在前端预埋 data-testid(或团队统一的 data-qa-*)
文案来自运营/多语言,频繁变化,不适合用 getByText锁死。多个按钮文案相同,仅靠 role+name 不足以唯一区分。 列表/卡片结构重复,需要稳定、与视觉无关的锚点。
与 AI 协作的关系:浏览器自动化或 AI 生成点击路径时,若只有脆弱 CSS 或模糊文案,模型容易乱猜元素;在关键交互点上约定 data-testid(或统一前缀与命名规范),等于提供机器与人共用的稳定契约,减少误点、降低维护成本。团队可约定命名规则,例如:页面-模块-动作(order-summary-pay)。
若 HTML 使用非默认属性名(如 data-test-id、data-qa),在 playwright.config 的 use 里设置 testIdAttribute,使 getByTestId('foo') 与之一致(见官方 TestOptions / Locators 文档)。
仍应避免的定位方式(社区与官方均反复强调):过深嵌套 CSS、仅依赖 nth-child、脆弱 XPath、与业务无关的 class 等——DOM 一改就碎。
6. 用例编排与断言:业务结果优先(实操)
文中建议的一套执行顺序(可按业务裁剪):
- 清场
:去掉环境里残留数据,避免影响后续断言(类似手测前擦干净环境)。 - 即时提交
:记录操作前关键指标 → 填参 → 提交 → 确认 → 验证指标确实变化。 - 预设条件提交
:带前置条件提交后,验证待办增加、资源占用等。 - 取消 / 回滚类
:先造数据 → 取消 → 验证数量与资源释放。 - 条件触发
:填触发条件 → 提交 → 验证进入预期状态。
断言原则:优先验证业务事实(指标、列表条数、DB/API 可见结果、资源占用),而不是只断言「Toast 弹了」「按钮变灰了」——后者容易因 UI 改版误伤,前者更贴近「链路是否真的可用」。这与「Web-first assertions」不矛盾:对 UI 仍可用 toBeVisible(),但通过标准最好是业务可核对的结果。
状态与并行:这类测试常有前后依赖(指标会变、待办会残留)。文中建议接受现实:必要时关闭过强并行、固定顺序、配合清场;这是设计选择,不是「测试写得差」。
7. 用例从哪来:人工准备为主,录制与 AI 为辅
建议流程:
- 业务侧输入
:用户故事、验收标准、关键路径列表(可表格化 Given-When-Then)。 - 人整理测试用例
:每条 E2E 对应「起点数据状态 + 用户操作 + 期望可见结果/接口结果」,标出必须覆盖的边界(权限、空态、错误提示)。 - 实现方式二选一或混合
:手写 spec; codegen录一遍再删减;Agent 探路再落 Helper + spec;AI 生成草稿后必须对照用例审查(生产环境仍以团队规范为准)。 - 评审
:用例是否与需求一一对应;断言是否落在业务结果上。
原则:录制 / Agent 都不能替代需求分析;否则测试只会固化「当时 UI 偶然长这样」。
新增用例推荐顺序(文中流程):先用 Agent 或手探把新流程跑通 → 记下稳定交互与关键断言点 → 看现有 Helper 是否已覆盖,缺则先补 Helper → 再写 spec → 更新用例/文档。
8. 调试 Playwright 与「代码分析」
- Trace
:失败用 trace: 'on-first-retry'、npx playwright show-trace、show-report,或上传 trace.playwright.dev(见官方 Trace viewer)。 - 调试卡住时换思路
:文中提到用不同模型/工具辅助修脚本——同一问题在一个模型上可能死循环,换模型或人工介入有时更快;以能稳定绿为准,不必绑死单一工具。 - 静态检查
:TypeScript + tsc --noEmit;ESLint@typescript-eslint/no-floating-promises,避免漏await假通过。 - 仓库约定
:关键 UI 变更同步 data-testid/ spec;可选 grep 审计关键路径覆盖。
其他工程习惯(官方 Best Practices):Web-first assertions;隔离用例;第三方用 page.route;并行与 sharding;CI 只装需要的浏览器。
Trace 的价值在于把「红」还原成时间线:哪一步开始等不到元素、当时 DOM 长什么样、网络是否失败——比对着代码猜要快一个数量级。漏 await 的假绿在本地有时能蒙过,上了 CI 才炸,这类用静态检查比在群里问「为什么我这边能跑」更省时间。
五、海量遗留用例迁移:Excel + AI 的两阶段门禁(防幻觉)
已有项目里常积压成千上万条手工用例(Excel / TestRail 等)。目标是利用历史资产批量生成 Playwright,但 LLM 会幻觉:跳步、漏前置条件、臆造页面结构、断言「假通过」。业界没有「一键全对」的银弹,常见做法是 Human-in-the-loop(人机回环) + 分阶段产出物:先产出人类可读、可审批的中间层,再允许生成代码。BrowserStack 等文档把这类流程概括为 迭代式提示与人工 refinement;测试管理领域也有 用例审批流(开发版 / 已批准版)、需求—用例可追溯矩阵(RTM) 等治理手段,本质都是先审后自动化(见文末新增文献)。
下面把流程写成可执行规范,并映射到常见工程实践。
1. 为什么必须「两阶段」:先文字路径,再出代码
| 阶段 A | 初审 | ||
| 阶段 B | 终审 |
直接「Excel 全文 → 扔给 AI → 出 Playwright」在体量上万时,返工成本往往高于两阶段。典型翻车是:脚本里点了一个并不存在的「保存并提交」组合按钮、或断言写成了「页面无报错」——这种代码能合并、能跑绿(在宽松断言下),但不验业务。把阶段 A 做成强制的文字对齐,相当于强迫模型先把「意图」说清楚:人一眼能看出它有没有在读同一本需求。
2. 阶段 A:在 Excel 里固化「AI 执行过程语言」与初审打标
在原有列(用例 ID、模块、前置条件、步骤、预期结果等)基础上,建议固定增加几列:
AI_拟执行路径:模型输出的逐步自然语言(可约定模板: Step1 … StepN+ 可观测期望:页面文案、列表条数、关键字段值或接口状态)。这就是「让 AI 按 Playwright 会怎么做的方式,把过程写回表里」——先不生成代码,只生成可审的剧本;可要求同步标注建议的data-testid或页面区域,减少后续乱猜。AI_风险与假设(可选):测试数据从哪来、是否依赖登录/多 Tab/定时任务等。 初审结论:通过 / 不通过 / 需补充信息;不通过时填驳回原因(用于下一轮 prompt 或业务补需求)。 初审人、初审日期:便于审计与统计。
初审通过的标准建议书面化,例如:步骤完整、顺序合理、期望结果可判定、无凭空页面元素。未通过行禁止进入阶段 B。
与业界概念的对应:这一层相当于在「旧用例文字」和「代码」之间加了一层 可评审的意图说明;若团队熟悉 BDD,也可让阶段 A 对齐 Gherkin(Given-When-Then),再用
playwright-bdd等工具衔接(见参考文献)。Excel 只是载体,也可迁到 TestRail 等 TMS,但列语义建议保持一致。
3. 阶段 B:仅对「初审通过」行生成 Playwright,并做终审
- 输入
:通过行的 AI_拟执行路径+ 原预期结果 + 环境说明(基地址、账号策略、是否 mock 第三方)。 - 输出
: *.spec.ts、共用 fixtures / auth / helpers(与第四节一致)。 - 终审
:人在 PR 或测试管理里标记 代码级 OK(locator 稳定性、断言是否验证业务事实、数据隔离、flaky 风险)。可再列 终审结论:真正 OK / 需修改 / 暂缓。
终审建议至少包含:CI 跑绿、关键用例 Trace 抽查、与业务确认断言验的是结果而非表象。
4. 上万条规模时的工程建议
- 分批与优先级
:按模块、风险、核心交易路径排序,避免一次全量生成。 - 数据驱动
:多行仅参数不同 → 一张表驱动一条或少量 spec(社区常用 ExcelJS 读表 + Playwright 参数化,见参考文献),避免生成上万个几乎相同的文件。 - 规则 + AI 混合
:格式高度规整的旧用例可先做确定性转换(如纯文本步骤 → 初稿脚本),再让 AI 补全与修正,降低纯幻觉(社区有 manual-to-test 类探索,见参考文献)。 - 治理
:在表中保留 需求ID/版本,与 RTM(需求—用例—自动化) 或 审批流(仅 approved 进「永远绿」套件)对齐(见 TestCollab、testRigor 等公开介绍)。
5. 流程总览
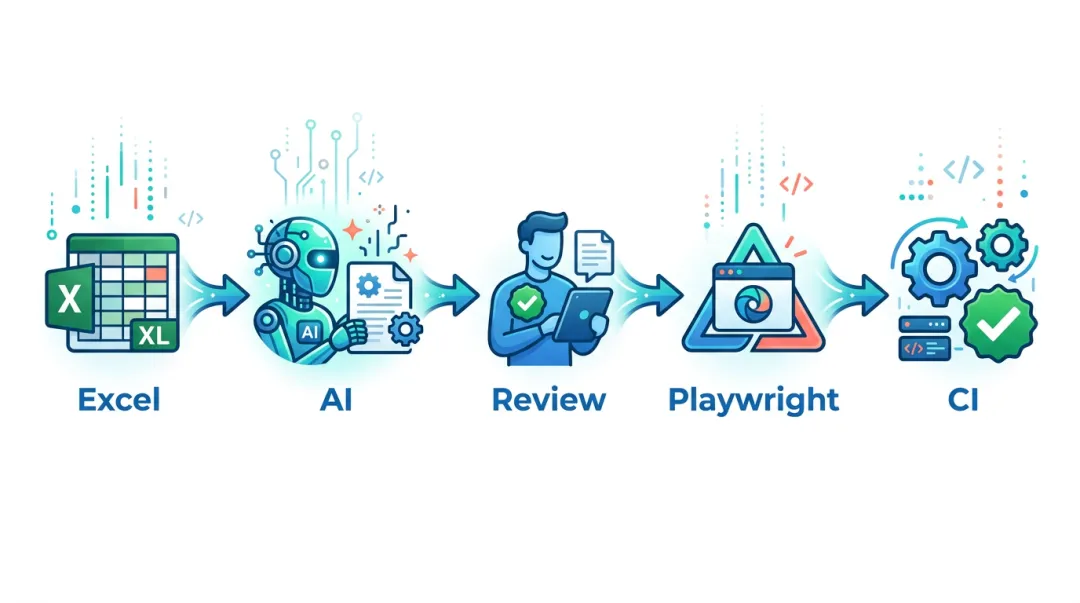
核心原则:文字路径未批准 → 不准生成代码;代码终审未通过 → 不准进入「永远绿」套件。
六、小结
全文从「为什么要测」讲到「怎么分层」,再讲 AI 来了以后谁拍板、谁写草稿,然后落到 Playwright 怎么录、怎么定位、复杂页面怎么收进 Helper,最后讲存量 Excel 怎么分两阶段交给 AI,是一条从理到事的路径。
- 为什么测
:守住正确性/可靠性/安全,降低晚期缺陷成本,支撑重构与发布节奏,并把需求变成可执行约束。 - 怎么测(经典)
:金字塔(单测为主 + 集成 + 精选 E2E),结合 CI。 - AI 时代
:人定义标准与红线,AI 放大编写与迭代速度;对 AI 产品额外做评测集、非确定性下的指标、护栏。 - E2E / Playwright
:codegen(含 storage 登录态、Inspector 断言)与 Pick Locator 提效;复杂页上接受 codegen 局限,用 Agent 探路 + Helper 封装页面怪癖,spec 只编排业务;role / text / testid 分层定位,关键路径 预埋 data-testid;断言优先业务结果(指标、数据、资源),必要时再接受顺序执行与清场;TS + ESLint + Trace,调试可换工具/模型。测试不是拖慢 AI,而是让产出的代码敢合并、敢上线。 - 海量遗留用例 + AI
:采用 两阶段门禁(先 AI 拟执行路径 写入表、人初审打标,再对通过项生成 Playwright、人终审);上万条时配合 分批、数据驱动、可追溯列、审批语义,对齐业界 human-in-the-loop 与 用例审批 / RTM 思路。
参考文献与链接
以下为撰写时查阅的公开资料,便于按图索骥;以各文档最新版本为准。
微信公众号 — 人类如何协助 AI 完成 e2e 测试生成(codegen 与 storage、复杂页局限、Agent 探路、Helper 与业务断言、用例编排与调试等实操叙述)
https://mp.weixin.qq.com/s/F61vQGI52QpVqhkF2uYUtwPlaywright — Best Practices(测试哲学、Locator、codegen、断言、Trace、CI、Lint 等)
https://playwright.dev/docs/best-practicesPlaywright — Generating tests / Test generator(
codegen入门与录制流程)
https://playwright.dev/docs/codegen-intro
https://playwright.dev/docs/codegenPlaywright — Locators(
getByRole、getByTestId等内置定位方式)
https://playwright.dev/docs/locatorsPlaywright — TestOptions(含
testIdAttribute等运行选项)
https://playwright.dev/docs/api/class-testoptionsPlaywright — Trace viewer(Trace 配置与查看方式)
https://playwright.dev/docs/trace-viewer
在线查看器:https://trace.playwright.dev/Playwright — Setting up CI / CI(GitHub Actions 与通用 CI)
https://playwright.dev/docs/ci-intro
https://playwright.dev/docs/ciPlaywright — Getting started - VS Code(扩展录制、调试)
https://playwright.dev/docs/getting-started-vscodeBrowserStack — How to Use Playwright Codegen for Test Automation(codegen 使用指南类文章)
https://www.browserstack.com/guide/how-to-use-playwright-codegenBrowserStack — Playwright Selectors Best Practices(选择器实践归纳)
https://www.browserstack.com/guide/playwright-selectors-best-practicesSensioLabs — Why Tests? Explained for Management(向管理层解释测试价值,含成本视角)
https://sensiolabs.com/blog/2025/why-tests-explained-for-managementLangfuse — LLM Application Testing(LLM 应用测试与 eval 思路,适用于「产品在卖 AI 能力」时)
https://langfuse.com/blog/2025-10-21-testing-llm-applicationsPlaywright — Authentication(
storageState、登录态复用,与codegen --save-storage/--load-storage配套)
https://playwright.dev/docs/authBrowserStack — Refine AI-generated test cases with iterative prompts(AI 生成用例后人工迭代、对话式 refinement,与「两阶段/人工把关」理念相近)
https://www.browserstack.com/docs/test-management/browserstack-ai/ai-generated-test-cases/iterative-promptsDEV Community — How to Build a Playwright Framework with Excel Data-Driven Testing(Excel 数据驱动 Playwright 的示例思路)
https://dev.to/ankitaloni369/how-to-build-a-playwright-framework-with-excel-data-driven-testing-l94Medium — From Excel to Playwright: Building a Smart Data-Driven Test Runner with Grouped Test Cases(分组与数据驱动跑批用例)
https://medium.com/@md.mazidulhasan1/from-excel-to-playwright-building-a-smart-data-driven-test-runner-with-grouped-test-cases-e7d0257c6a8dGitHub — rmgoede/playwright-manual-to-test-generator-info(手工步骤到 Playwright 的迁移/生成信息,偏规则化 + 再人工 refinement 的路线)
https://github.com/rmgoede/playwright-manual-to-test-generator-infotestRigor — How to Use Approval Workflow for Test Cases(用例审批流:开发版与已批准版、晋升与权限,与「终审通过才进回归套件」同构)
https://testrigor.com/blog/how-to-use-approval-workflow-for-test-cases/TestCollab — Requirements Traceability Matrix (RTM)(需求—用例可追溯、审计与覆盖率视图;可用 Excel 简化实现同一列语义)
https://testcollab.com/features/requirements-traceability-matrixPlaywright BDD 实践(Gherkin 与 Playwright 结合,可作为「阶段 A 文字」与代码之间的中间层参考)
https://testdino.com/blog/playwright-bdd/DEV — AI-Powered Test Case Review with MagicPod MCP Server and Claude(AI 辅助评审测试用例、与人审结合)
https://dev.to/aws-builders/ai-powered-test-case-review-with-magicpod-mcp-server-and-claude-4123
