 夜雨聆风
夜雨聆风
还在担心你的AI模型上线后“水土不服”吗?星球里不仅有AI医疗、模型鲁棒性的最新论文拆解,更有海量前沿资讯、开源代码和实战经验分享,帮你打造“金刚不坏”的AI系统!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文解决了一个非常实际且关键的问题:如何让医疗AI模型在部署后持续保持高性能,而不是随着时间推移和数据变化而“退化”。它提出的三阶段框架思路清晰,结合了特征分析和不确定性量化,像一个智能的“质检员”和“安全阀”,既能让模型学习新知识,又能防止“学坏”或“遗忘”。对于任何关心模型鲁棒性、持续学习和AI系统长期稳定性的同学来说,都极具启发和实用价值。
原论文信息如下:
ROBUST BY DESIGN: A CONTINUOUS MONITORING AND DATA INTEGRATION FRAMEWORK FOR MEDICAL AI 发表日期:
2026年04月 发表单位:
University of Houston, University Hospital Cologne, Stanford University, The University of Chicago 原文链接:
https://arxiv.org/pdf/2604.09009v1.pdf

医疗AI的“隐形杀手”:数据漂移
三阶段框架:像质检员一样筛选新数据
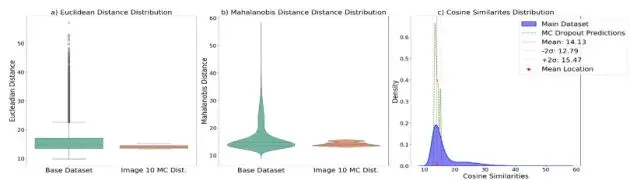
第一阶段:特征分析——建立“标准样”档案
欧氏距离:衡量特征向量与整体均值在空间中的直线距离。
余弦相似度:衡量特征向量的方向与均值方向的一致性,忽略长度。
马氏距离:考虑了特征各维度相关性(协方差)的“加权”距离,更能反映数据在分布中的位置。
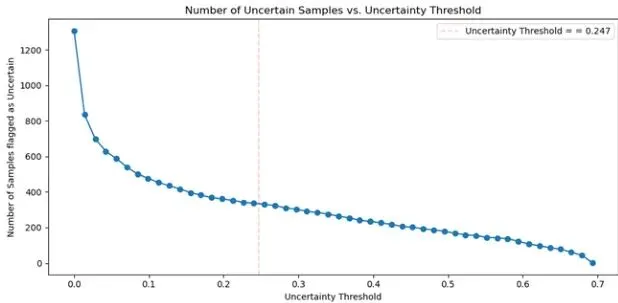
第二阶段:不确定性评估——检查“自信心”水平

第三阶段:安全更新与监控——最后一道“安全阀”
只有当所有核心性能指标(AUC、准确率、敏感度、特异度)的下降幅度均不超过5%,并且第二阶段的不确定性阈值没有升高超过5%时,这次数据整合和模型更新才算正式被接受。
核心武器:特征距离与不确定性双保险
保险一:特征空间距离/相似度(看“长相”) - 欧氏、余弦、马氏距离三者结合,提供了互补的视角。欧氏距离看绝对远近;余弦相似度看方向是否一致,对于特征归一化后特别有用;马氏距离则是最严格的,因为它考虑了特征之间的相关性,能更准确地判断一个点是否属于某个多元高斯分布。三者都达标,才能证明新数据在统计特性上与旧数据“同宗同源”。
保险二:预测不确定性(看“信心”) - 即使数据“长相”合格,模型也可能因为各种原因(如图像模糊、处于类别边界)而对它没把握。MC Dropout提供的预测熵是一个非常好的认知不确定性度量。只整合那些模型自己都很有信心的样本,相当于让模型“教”自己已经会的东西,自然更安全。
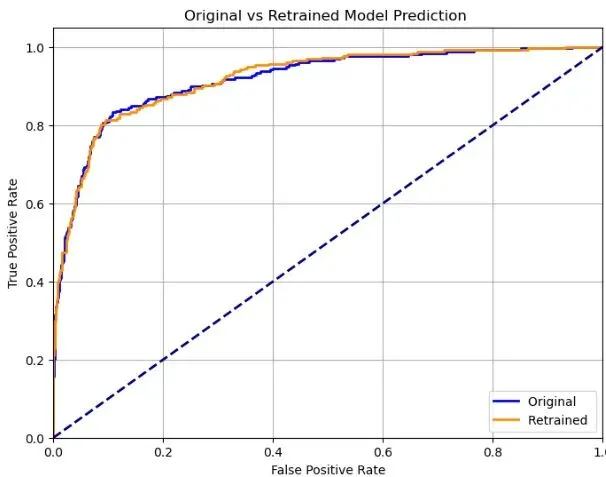
实验结果:单图更新,性能稳如泰山


AUC稳如磐石:整合任何一张图像后,AUC都在92%左右波动,变化幅度不超过0.26%。
准确率几乎不变:准确率保持在89%附近,最大变化仅0.09%。
敏感度/特异度平衡:敏感度(对阳性类的识别能力)有轻微下降(最大-4.35%),但特异度(对阴性类的识别能力)有轻微上升(最大+0.6%),总体性能权衡在可控范围内。

局限与展望:从单点更新到批量进化
过于严格的“守旧”策略:当前的阈值机制可能会永久性地拒绝那些真正新颖、但分布外的重要病例。比如一种新的、罕见的病变亚型。未来可能需要引入人类专家复核环节,将这些“特殊样本”在确认后,以更可控的方式(如单独微调分支)纳入学习。
单点更新的效率瓶颈:实验只演示了每次添加一张图。现实中数据是批量到来的。如何设计高效的批量筛选和更新策略,同时保证安全,是工程落地的关键。
静态阈值的适应性:随着模型不断学习,其特征空间分布本身也在缓慢演变。最初的“第80百分位”阈值可能不再适用。因此,研究动态调整的阈值机制,让“正常范围”的定义也能与时俱进,是下一个逻辑步骤。
龙迷三问
数据漂移具体指什么?和域适应有啥区别?数据漂移(Data Drift)指的是模型部署后,所处理的实时数据分布与训练数据分布发生偏离的现象。这可能源于人口统计变化、采集设备更新、操作流程改变等。它与域适应(Domain Adaptation)有联系也有区别:域适应通常指在训练阶段,已知目标域(新分布)数据,主动让模型去适应;而数据漂移关注的是部署后未知的、逐渐发生的分布变化,更侧重于在线监测和动态调整。
马氏距离是什么?为什么它比欧氏距离更严格?马氏距离(Mahalanobis Distance)是一种考虑了数据特征间相关性的距离度量。简单来说,如果数据点在某个方向上方差很大(分布很散),那么在那个方向上偏离均值远一点也算“正常”;如果在某个方向上方差很小(分布集中),那么稍微偏离一点就算“异常”。它通过除以协方差矩阵来进行这种“加权”。因此,它能更准确地判断一个点是否属于一个多元分布。相比之下,欧氏距离对所有方向一视同仁,不够精细。
这个框架如何防止“灾难性遗忘”?主要通过三重机制:1. 选择性整合:只加入分布内且模型自信的样本,这些样本与旧知识冲突小。2. 增量训练:重训时是在原有训练集(包含所有旧数据)的基础上增加新样本,而不是只用新样本。3. 性能保障:更新后立即在代表旧知识的测试集上验证,性能下降超限则回滚。这确保了新知识的学习不会以牺牲旧知识为代价。
龙哥点评
论文创新性分数:★★★☆☆ 三颗星。框架本身并非从0到1的突破,而是将特征漂移检测、不确定性量化、安全持续学习等已有概念进行了巧妙、系统化的工程整合。其创新点在于针对医疗AI高可靠性要求的设计哲学和严谨的三阶段流程。
实验合理度:★★★★☆ 四颗星。实验设计紧扣核心主张,通过“单图更新”这种极端但清晰的场景,有力验证了框架维持性能稳定的能力。使用独立测试集进行评估和阈值确定,避免了数据泄露。美中不足是缺少与更复杂的持续学习基线方法(如基于回放的算法)的直接对比。
学术研究价值:★★★★☆ 四颗星。为医疗AI的长期部署和运维提供了一个极具实用参考价值的研究范式和基准。它强调了在追求模型“智能”增长时,“稳定”和“安全”应作为前置约束条件,这对高风险的AI应用领域有重要启发。
稳定性:★★★★☆ 四颗星。从实验来看,在设定的严格规则下,框架表现出极高的稳定性,能有效防止性能退化。但其稳定性严重依赖于阈值的合理性和“性能保障”策略,在面临剧烈或复杂的数据漂移时,可能需要额外机制。
适应性以及泛化能力:★★★☆☆ 三颗星。框架思路具有很好的泛化性,可迁移到其他医学影像甚至非影像任务。但其当前形式更适用于相对平稳、渐进的数据变化。对于需要学习全新模式或快速适应突变的情况,现有的保守策略会成为瓶颈。
硬件需求及成本:★★☆☆☆ 两颗星。主要的计算开销在于两个环节:1. 对每张新图像进行多次MC Dropout推理(文中250次)以计算不确定性;2. 每次整合新数据后都需要从头重训模型(尽管是在原有数据上加新数据)。这在数据量大或模型复杂时,会产生显著的存储和计算成本。
复现难度:★★★☆☆ 三颗星。方法描述清晰,使用的都是成熟技术(ResNet, MC Dropout, 标准距离度量)。但论文未提供完整代码,且多中心医疗数据的获取和标注是主要复现壁垒。算法逻辑本身的复现难度中等。
产品化成熟度:★★☆☆☆ 两颗星。目前仍是一个研究框架原型。要产品化,必须解决批量处理、动态阈值、计算效率、与现有医院信息系统集成、以及最重要的——如何处置被拒绝的“异常”样本(需设计临床工作流)等一系列工程和流程问题。
可能的问题:本文的实验验证在“单图、同分布”的理想条件下非常成功,但未测试在连续、批量、且包含显著分布外样本的真实数据流下的长期表现。其保守性可能导致模型“进化”缓慢,无法捕捉重要的分布变化趋势。
参考文献
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!



