https://doi.org/10.1016/j.aichem.2026.100107本文聚焦人工智能在功能分子与材料发现领域的应用,核心针对生成模型发展受限于实验数据混乱、高质量真值数据稀缺的行业瓶颈,系统整合了数据治理、表征方法、生成建模、闭环实验验证的全流程最佳实践,提出了可落地的四阶段工作流,同时梳理了核心算法体系、支撑基础设施、可重复性与伦理保障方案,最终给出实验室 AI 转型的优先级检查清单与未来开放挑战。
一、研究背景与核心瓶颈
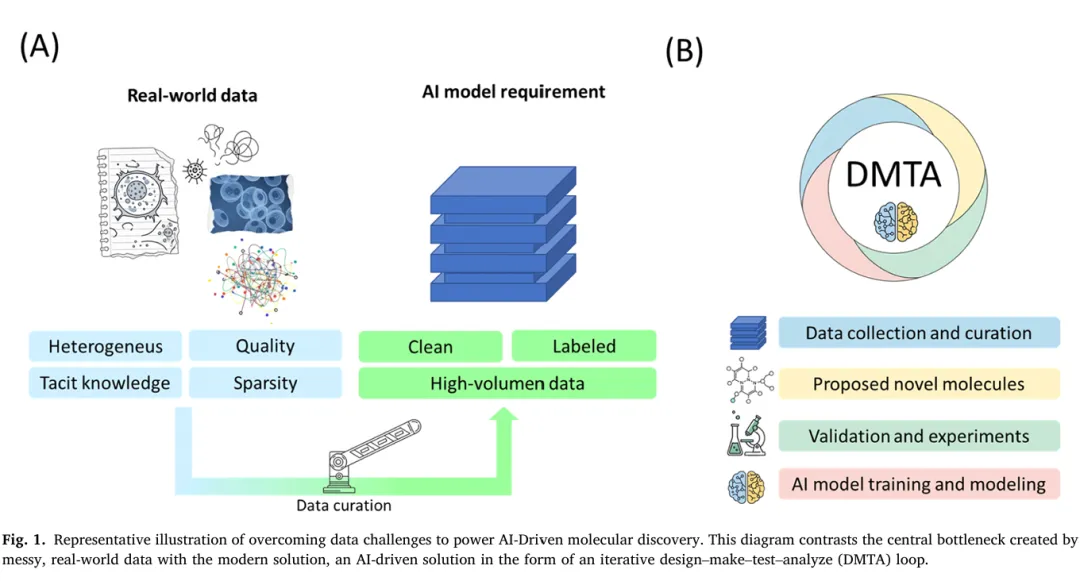
传统分子与材料发现依赖耗时的试错实验,需在广阔的化学空间中无明确方向地筛选,在能源材料、环境应用、医药研发等领域效率极低。AI 与机器学习技术可大幅加速发现进程,图神经网络等模型已实现化学空间探索量级的突破,甚至可跳过传统数十年的实验流程。当前行业核心瓶颈在于真实世界实验数据与 AI 模型需求的根本性不匹配。Fig.1 展示了这一核心矛盾:AI 模型需要干净、标注完整的高质量数据,而真实实验数据普遍存在稀疏、噪声大、异质性强的问题;实验与模拟数据多为碎片化、质量参差不齐的状态,来自多种检测技术、仪器、合成路线的数据格式、噪声水平、元数据规范均不统一,导致强大的模型在真实数据上易失效或过拟合。生成式 AI 为该瓶颈提供了新的解决路径,可直接提出全新分子设计方案,通过将已知结构嵌入连续潜空间再解码生成新候选分子,实现从噪声数据到可用设计假设的转化。本文提出的核心解决方案,是一套打通模型构建与真实世界数据的闭环迭代工作流,将数据预处理、特征工程、生成建模、实验验证深度融合,确保生成的设计方案扎根于实验现实。
二、分子发现的核心数据挑战
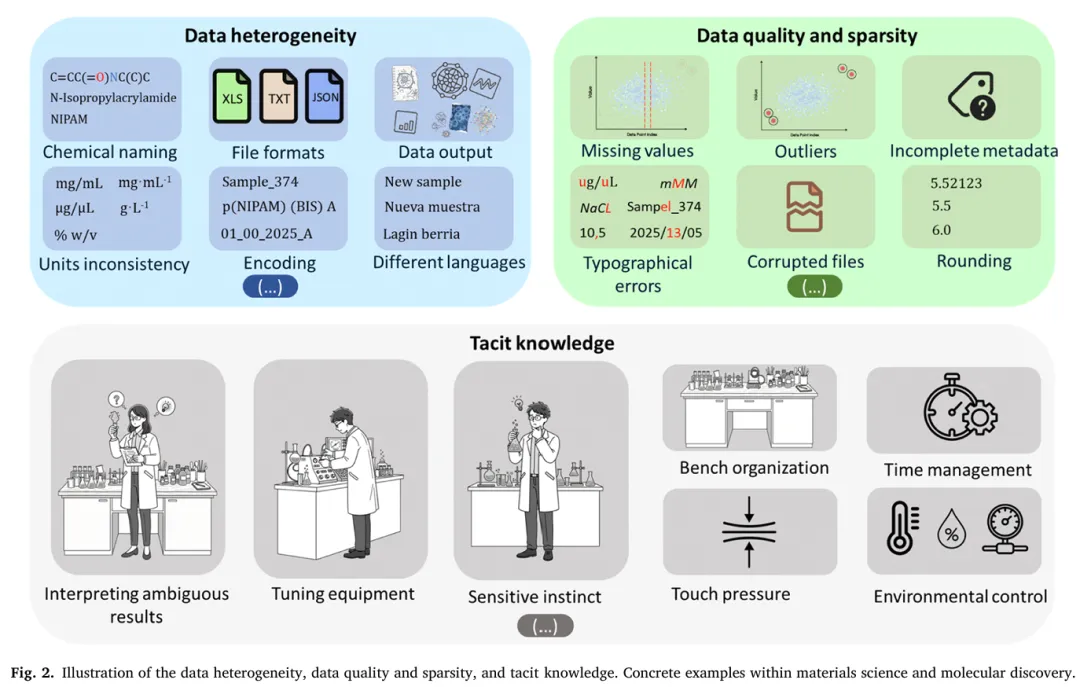
这是 AI 驱动分子发现的首要障碍,综述从三大维度拆解了数据问题,并给出了系统性解决方案。Fig.2 具象化呈现了数据异质性、数据质量与稀疏性、隐性知识三大核心挑战的具体表现与化学领域实例。2.1 数据异质性
科学数据分为结构化、半结构化、非结构化三类,在材料与化学研究中,单个项目可产生从原子尺度的化学组成、晶体结构,到实验室规模的合成条件等多维度异构数据,核心问题体现在:结构差异:同一性质通过不同技术测量(如差示扫描量热法与毛细管法测熔点),结果格式与隐含假设不统一,无法直接对比;
单位与元数据不规范:温度、压力等参数单位冲突,电子实验记录本(ELN)中的自由文本缺乏标准化描述符;
表征数据变异性:不同场强的核磁、不同分辨率的红外光谱需复杂的归一化预处理;
实验与计算数据融合难:合成收率等实验值与 DFT 计算的能量值在尺度、不确定性上存在本质差异,缺乏统一的融合框架。
针对异构数据的整合,综述提出了四阶段数据准备与概率整合工作流,Table 1 详细定义了每个阶段的核心任务、描述与配套工具框架: | | |
|---|
| | REST/SQL API、Pandas 数据探查库、数据目录、本体映射工具 |
| 将原始数据转化为一致的机器可读格式,解决单位归一化、命名规范、缺失值处理等问题 | Python(Pandas、NumPy)、MatMiner/PyMatGen、Scikit-learn 插补工具、自定义规则过滤器 |
| 将标准化数据流合并为统一主数据集,通过统计或算法方法解决数值冲突 | 概率模型(贝叶斯融合、极大似然估计)、矩阵分解、网络集成模型、加权平均算法 |
| 评估融合后数据集的质量与适用性,通过领域专家审核、预测建模验证清洗效果 | 领域专家评审、Scikit-learn/XGBoost、统计指标(R²、RMSE)、特征重要性分析 |
2.2 数据质量与稀疏性
与计算机视觉、NLP 领域的十亿级标注语料不同,材料与分子科学的数据依赖实验室生成,实验的高成本、长周期导致数据库规模小、稀疏、充满测量误差与缺失信息,高质量真值数据稀缺,直接引发机器学习的冷启动问题—— 针对全新材料体系,模型无实验数据可学习,无法泛化或给出有效预测。自主实验室
集成自动化与机器学习的机器人平台,通过动态流动实验实时监测反应,数据生成效率是传统稳态方法的 10 倍以上,同时减少试剂消耗与废弃物;
合成数据增强
通过生成模型创建高质量合成数据用于训练,如 MatWheel 框架可在数据极度稀缺的场景下训练预测模型,性能接近甚至超过真实样本训练的模型,从根本上将数据稀缺问题转化为智能数据生成问题。
2.3 隐性知识的捕获
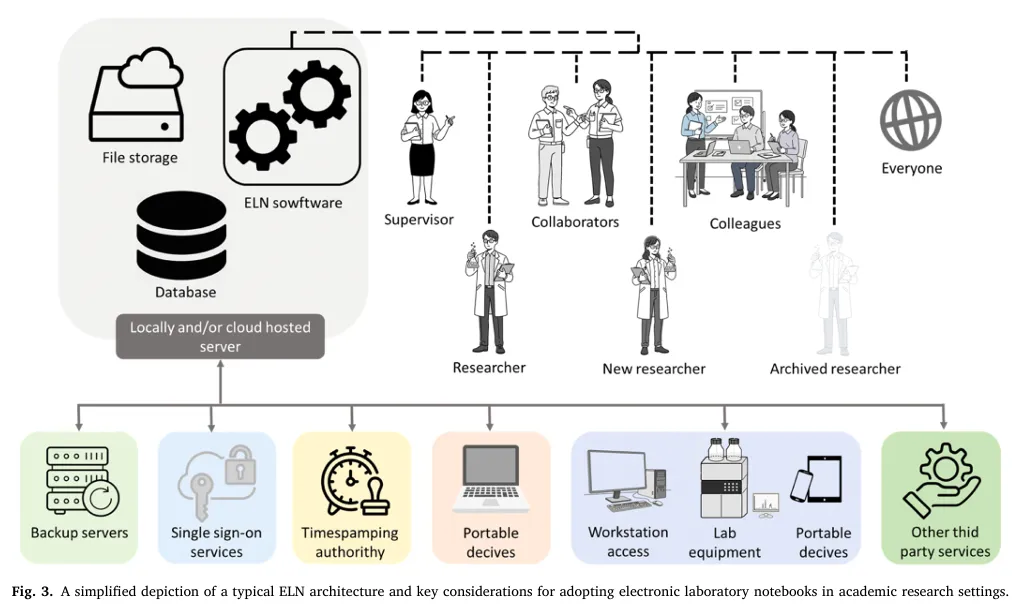
隐性知识是科学家通过经验与直觉积累的、难以清晰表述的实验诀窍,如搅拌速度、试剂滴加速率、容器几何形状等未记录的参数,是实验可重复性的核心,也是 AI 模型部署的关键瓶颈。两个形式上完全一致的合成方案,会因隐性知识的缺失导致结果天差地别,仅基于公开文献或数据库训练的模型,在真实实验室场景中极易失效。解决隐性知识捕获的核心基础设施是智能化电子实验记录本(ELN),Fig.3 展示了典型 ELN 的架构与核心功能模块:核心架构:ELN 软件作为中心枢纽,连接数据库、文件存储,部署在本地或云端服务器,配套备份系统、单点登录、时间戳授权、实验室仪器直连等模块;
多角色协作:覆盖研究员、新入职人员、归档人员、主管、合作者等全角色,实现实验记录的时间戳留存、电子签名审批、历史数据可追溯、团队协作共享;
AI 赋能的知识提取:通过 NLP 与大语言模型解析自由文本记录,提取化学名称、反应条件、操作步骤等机器可读实体,将被动的文档记录转化为主动的结构化知识捕获,同时完整记录阴性结果与失败实验,消除数据集的幸存者偏差;
知识图谱落地:将捕获的材料、反应条件、实验流程作为节点,因果关系与相关性作为边构建知识图谱,让 AI 模型能够有效推理材料 - 工艺 - 性能之间的复杂非线性关系。
ELN 构建了科学家与 AI 之间的双向反馈闭环:ELN 捕获的专家经验丰富知识图谱,优化 AI 的预测能力;AI 则基于知识库为实验设计与优化提供数据驱动的建议,实现人类直觉与计算分析的协同。
三、分子发现的机器学习模型体系
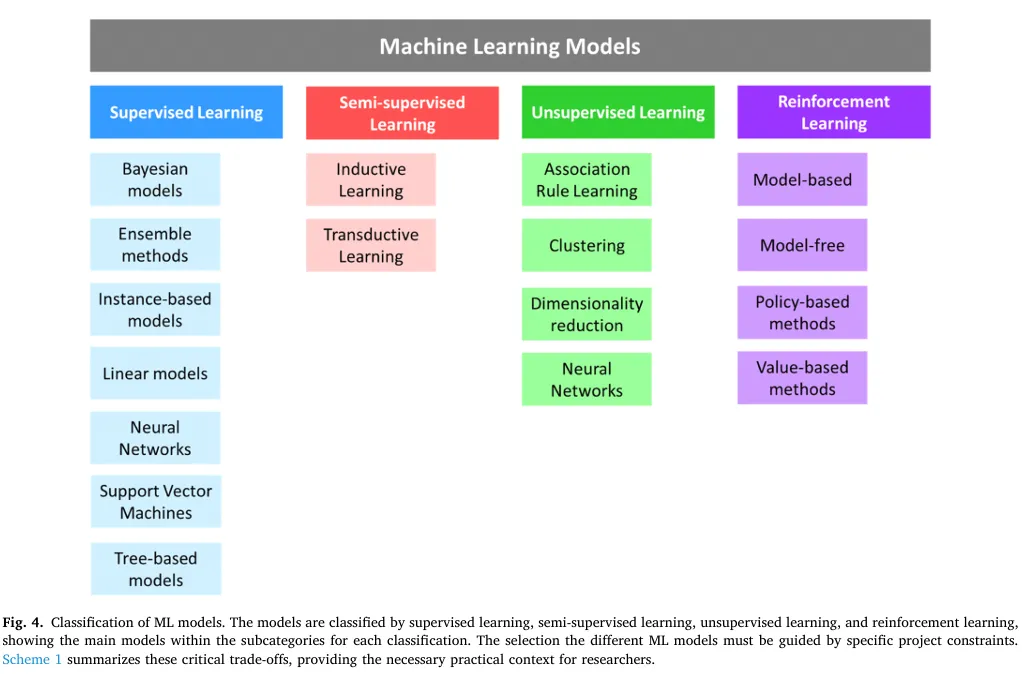
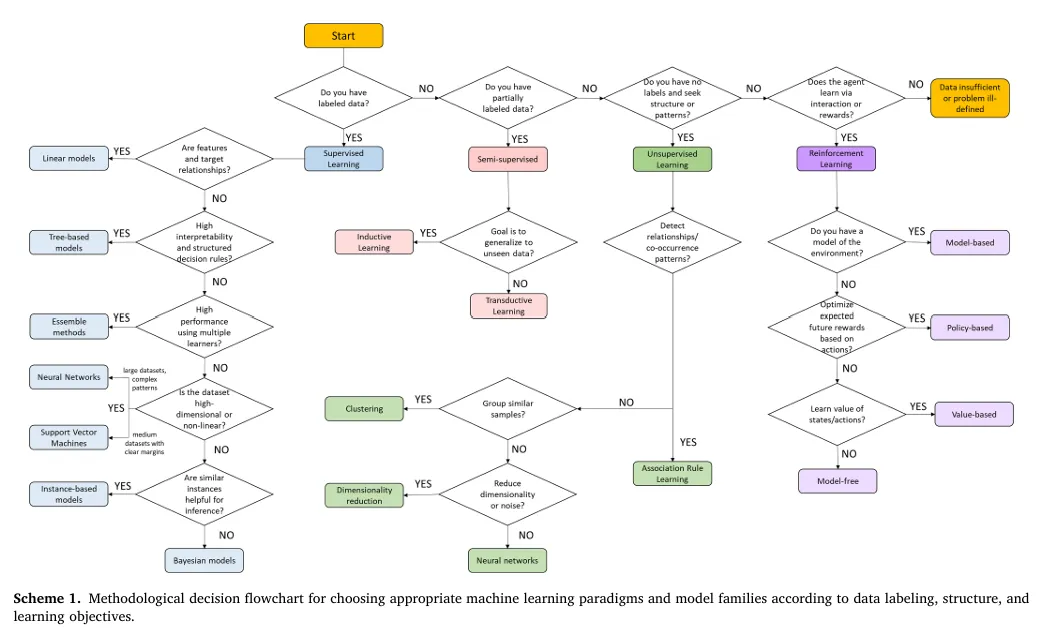
综述系统梳理了机器学习的四大核心范式,明确了各类模型在分子发现任务中的适用场景、子类别与优劣势。Fig.4 对机器学习模型进行了整体分类,涵盖监督学习、半监督学习、无监督学习、强化学习四大类及各自的核心子模型;Scheme 1 提供了基于数据标注情况、结构与学习目标的机器学习范式选择决策流程图。3.1 监督学习
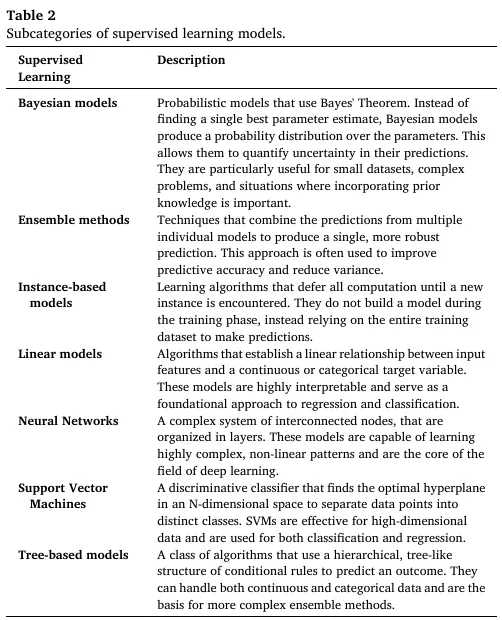
监督学习是分子发现中最基础的范式,基于标注数据集学习输入到输出的映射,核心分为分类与回归两类任务,Table 2 详细定义了各子类别的原理与适用场景: | |
|---|
| 基于贝叶斯定理的概率模型,输出参数的概率分布,可量化预测不确定性,适用于小数据集、需融入先验知识的复杂问题 |
| 结合多个独立模型的预测生成单一稳健结果,用于提升预测精度、降低方差 |
| 遇到新实例时才启动计算,训练阶段不构建模型,完全依赖训练数据集完成预测 |
| 建立输入特征与目标变量的线性关系,可解释性极强,是回归与分类任务的基础方案 |
| 多层互联节点构成的复杂系统,可学习高度复杂的非线性模式,是深度学习的核心 |
| 在高维空间中找到最优分类超平面的判别式分类器,对高维数据效果优异,可用于分类与回归任务 |
| 通过分层条件规则的树状结构预测结果,可处理连续与分类数据,是复杂集成方法的基础 |
监督学习的核心应用包括材料热力学稳定性预测、晶体缺陷识别、药物 - 靶点结合亲和力预测、分子毒性分类、合成反应收率优化;核心发展方向聚焦可解释 AI(XAI)、小样本 / 零样本学习、自动化机器学习(AutoML)。3.2 半监督学习
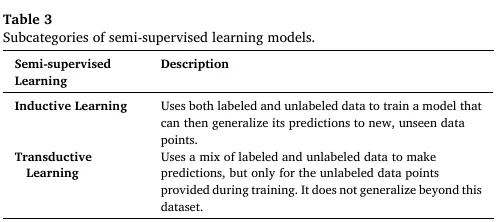
半监督学习是解决标注数据稀缺的核心方案,结合少量高成本标注数据与大量无标注数据训练模型,Table 3 定义了两大核心子类别: | |
|---|
| 基于混合数据训练可泛化到全新未见数据的模型,是通用部署场景的首选 |
| 仅对训练中提供的无标注数据做预测,不具备泛化能力,适用于固定数据集的分析任务 |
其核心应用为材料合成缺陷检测、微观图像异常识别,仅需少量缺陷样本即可在海量无标注显微图像中识别异常模式。3.3 无监督学习
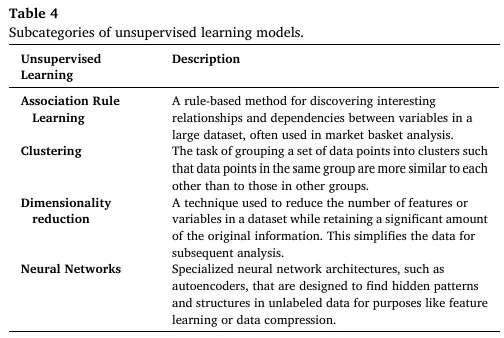
无监督学习可在无预定义标签的数据中发现隐藏的模式与结构,是探索性数据分析的核心工具,Table 4 定义了四大核心子类别: | |
|---|
| 基于规则的方法,用于发现大数据集中变量间的关联与依赖关系,典型应用为市场篮分析 |
| 将数据点按相似度分组,使同组内数据点的相似度高于组间,核心算法包括 K-means |
| 在保留原始数据核心信息的前提下,减少特征 / 变量数量,简化高维数据的后续分析,核心算法包括 PCA、SVD |
| 以自编码器为代表的专用架构,用于无标签数据的隐藏模式挖掘、特征学习与数据压缩 |
其核心应用包括新材料分类与聚类、分子性质聚类、分子子结构与生物功能的关联规则挖掘、高维光谱数据的降维与特征提取;未来发展聚焦自监督学习,通过数据内在结构生成监督信号,实现大规模无标注数据的预训练。3.4 强化学习
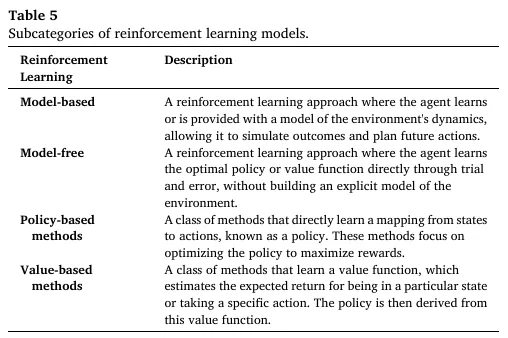
强化学习通过智能体与环境的交互、基于奖励信号的试错学习实现序列决策优化,Table 5 定义了四大核心子类别: | |
|---|
| 智能体学习或被明确提供环境动力学模型,可模拟结果、规划未来动作,无需高成本的真实世界交互 |
| 直接通过试错学习最优策略或值函数,不构建显式的环境模型,分为策略基与值基两类 |
| 直接学习从状态到动作的映射(策略),核心是优化策略以最大化奖励 |
| 学习值函数,评估特定状态 / 动作的预期未来回报,再通过值函数推导策略 |
其核心应用包括薄膜沉积参数优化、自主实验室自动化、个性化药物分子设计、合成路线优化、分子对接与化学空间探索;强化学习通常不单独使用,而是作为其他模型的优化层,如通过奖励函数微调生成模型,使其生成具备目标性质的分子。
四、深度学习与生成式分子设计
4.1 核心深度学习架构
深度学习是实现端到端分子表征与生成的核心技术,Fig.5 展示了分子发现场景中四大核心深度学习架构的输入输出逻辑:多层感知机(MLP):全连接前馈网络,适用于结构化 / 表格数据,是分子描述符建模的基础架构;
卷积神经网络(CNN):通过卷积与池化层提取空间结构特征,适用于分子图像、显微图像、光谱数据的处理;
循环神经网络(RNN/LSTM/GRU):专为序列数据设计,具备记忆能力,适用于 SMILES 字符串、反应时序数据的建模;
Transformer 架构:通过自注意力机制建模长程依赖,并行处理序列数据,是当前化学大语言模型的核心架构。
4.2 生成式模型体系
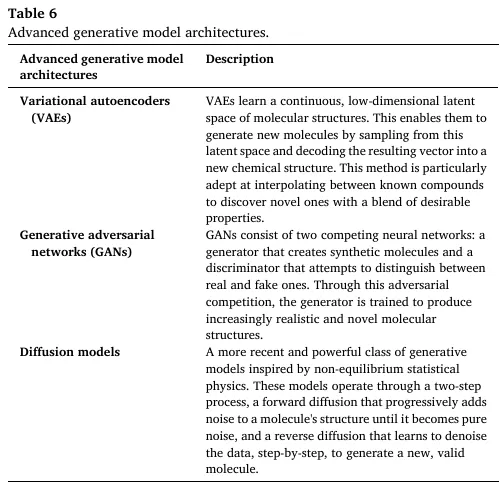
生成式模型是逆分子设计的核心,可直接生成具备目标性质的全新分子,颠覆了传统 “先合成再筛选” 的模式。Fig.6 展示了三大核心生成模型的底层机制,Table 6 详细定义了各架构的原理与分子设计中的特性: | |
|---|
| 学习分子结构的连续低维潜空间,通过潜空间采样解码生成新分子,擅长在已知化合物间插值,发现融合目标性质的新分子 |
| 由生成新分子的生成器与判别分子真伪的判别器构成,通过对抗博弈训练,生成高保真、高真实度的新型分子结构 |
| 受非平衡统计物理启发的生成模型,通过逐步向分子结构加噪、再逆过程去噪生成新的有效分子,是当前化学设计领域的 SOTA 方案,可自然保留 3D 几何结构与物理约束 |
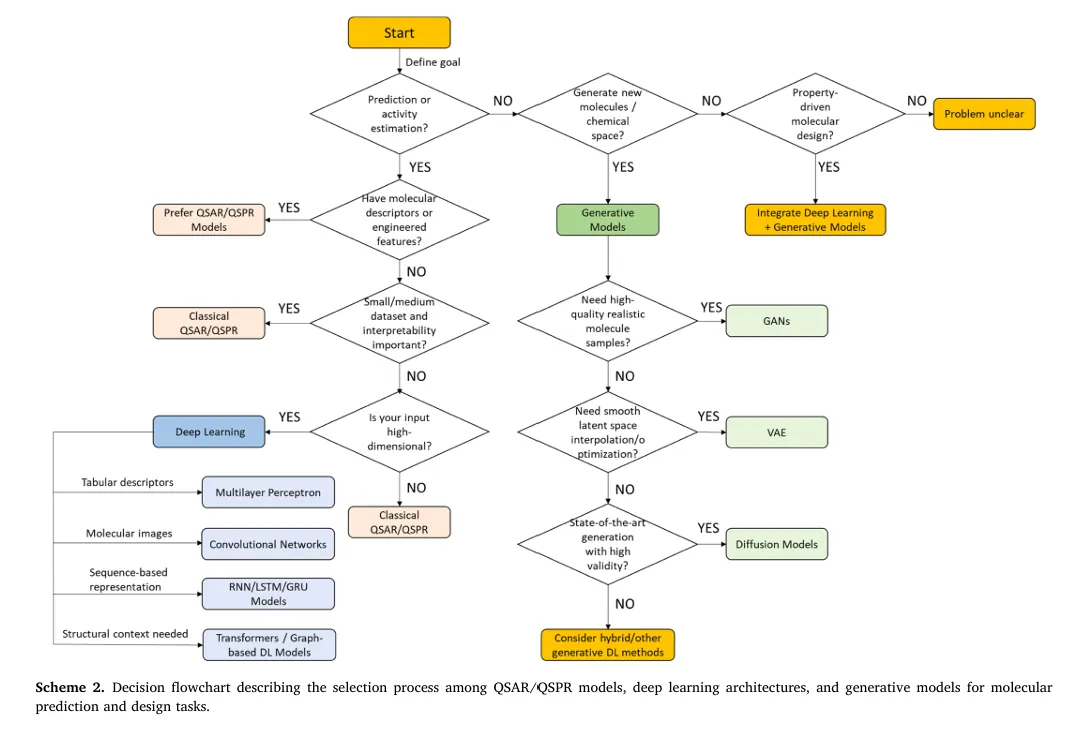
Scheme 2 提供了分子预测与设计任务中,QSAR/QSPR 模型、深度学习架构、生成模型的选择决策流程图,核心基于任务目标、数据规模、可解释性需求、输入数据形式等维度指导模型选型。同时,综述提出了多智能体协同的生成框架:一个 AI 智能体生成分子结构,另一个同步评估其性质与合成可行性,通过迭代交叉验证避免 “分子幻觉”—— 即生成符合化学规则但无实际活性或合成可行性的化合物。
五、AI 驱动分子发现的集成研发闭环
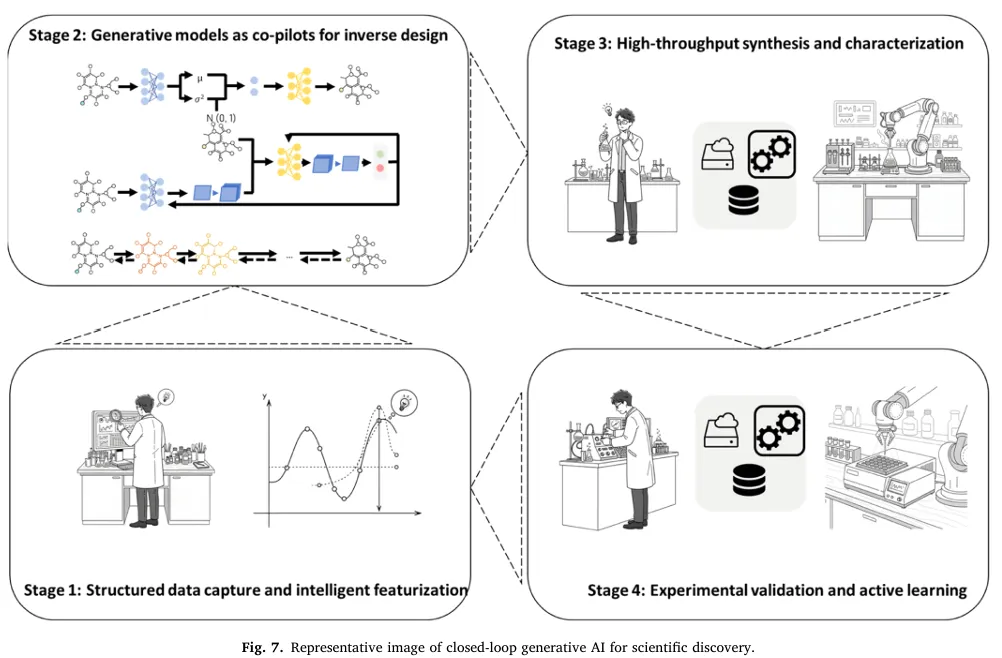
传统线性的分子发现模式已无法适配 21 世纪的广阔化学设计空间,当前主流范式是AI、机器人、自动化融合的动态互联自主闭环体系,本质是加速版的设计 - 制造 - 测试 - 分析(DMTA)循环。Fig.7 展示了闭环生成式 AI 科学发现的四阶段框架,各阶段高度耦合,前一阶段的质量直接决定后一阶段的效果。阶段 1:结构化数据捕获与智能特征化
这是整个闭环的基础,核心是从实验设计之初就融入 AI 适配的考量,从传统非正式的数据记录转向正式的结构化、机器可读的数据捕获体系。核心工作:遵循 FAIR 原则(可查找、可访问、可互操作、可重用),通过 ELN、标准化本体、仪器直连实现多模态数据的统一采集;
特征化方案:传统方案包括 SMILES 字符串、分子指纹(如 ECFP),当前主流是图神经网络(GNN)驱动的图表示 —— 将原子作为节点、化学键作为边,自动提取拓扑信息,无需人工特征工程,可捕捉 2D/3D 分子几何结构的复杂关系;
核心风险:“垃圾进,垃圾出(GIGO)” 级联效应,数据命名不规范、合成细节缺失等问题,会导致特征化错误,最终让生成模型产生化学无效、合成不可行的幻觉分子。
阶段 2:生成模型作为逆设计的副驾驶
基于结构化与特征化的数据,生成模型解决逆设计问题 —— 直接生成具备预定义性质的分子 / 材料结构,AI 从被动分析工具转变为主动设计智能体。核心工作:通过 VAE、GAN、扩散模型、图生成模型,在化学空间中主动导航,生成全新的候选结构;
关键保障:生成输出在提交合成前,必须经过快速的硅内验证流程,包括合成可行性(SA)评分、基于规则的化学合理性检查、低精度性质计算,从根源上避免无效的实验资源浪费。
阶段 3:高通量合成与表征
计算设计的假设需通过物理实现才能产生价值,本阶段的核心是通过 ** 自主驾驶实验室(SDL)** 实现合成与表征的自动化、实时化。核心平台:多机器人并行反应系统、连续流有机合成平台(如 Rainbow 多机器人实验室、Chemputer 系统),可单日完成数百至数千次实验;
关键能力:原位、实时表征技术(如扫描探针显微镜、X 射线衍射)直接集成到合成平台,为闭环提供即时的性质反馈,打破传统离线表征的时间延迟。
阶段 4:实验验证与主动学习的模型优化
这是闭环自迭代的核心,通过实验获取的高质量数据并非最终结果,而是模型优化的关键输入,通过主动学习算法指导下一轮的发现循环,实现快速收敛到目标性质。核心算法:贝叶斯优化(BO)是主动学习的核心技术,基于高斯过程构建概率代理模型,通过采集函数平衡 “利用(接近最优值的区域采样)” 与 “探索(高不确定性区域采样)”,以最少的实验次数找到全局最优解;
典型案例:CAMEO 平台通过物理信息驱动的贝叶斯机器学习预测材料性质,主动学习选择最具信息量的下一个实验,表征结果反馈回模型持续优化,大幅减少发现所需的实验数量;
人机协同:纯自主系统在高难度、全新体系中效率有限,在循环中保留人类专家的隐性知识与直觉,可显著提升人机协同的发现效率。
六、结论、落地建议与开放挑战
6.1 核心结论
AI 驱动的闭环实验正在彻底重塑分子发现领域,通过数据分析与自动化实验室的融合,研究者正在突破数据异质性、高价值测量稀疏、专家知识非形式化的传统瓶颈。当前最先进的工作流包含四大核心环节:全面的数据捕获、生成式设计、自动化执行、反馈式优化,通过不确定性感知的预测指导每一轮循环,即使在探索不足的化学空间中,也能以远少于传统试错的实验次数获得高性能候选分子。6.2 实验室 AI 转型的落地建议
基础设施建设
采用现代化、AI 兼容的基础设施,将多模态数据管理作为标准,实验记录不再使用自由文本,而是通过标准化本体实现机器可读的格式记录试剂、条件、流程与结果,落地 ELN 与结构化数据库,遵循社区数据标准实现数据互操作性;
组织与能力建设
实验室需培养数据管理员、机器学习工程师等专业角色,建立激励机制推动阴性结果的系统记录、跨部门数据共享,从 “专有知识优先” 转向 “数据规范优先” 的文化转变;
人机协同体系
搭建展示模型预测与不确定性的实时仪表盘,保留人类专家在循环中的监督与引导,通过可解释的界面建立对 AI 的信任,同时让 AI 充分吸收人类的专业经验。
6.3 未来展望与开放挑战
技术愿景
未来将形成由数字孪生与共享知识库互联的 “全球自主驾驶实验室”,大语言模型将文献、实验室数据、实时测量整合为统一的推理引擎,实验不再是孤立的试错,而是连续数据流的一部分,AI 可跨实验推理、提出假设、协调全球的机器人平台完成验证;
核心开放挑战
数据标准与互操作性、因果推理能力的提升、AI 工具的可及性与普及化;
伦理与安全保障
自动化工作流必须内置明确的 “停止条件” 与危害检查,每一个 AI 预测都需附带不确定性与可解释性标注,避免过度自信;同时需关注数据来源与偏差,防止在稀疏数据上的过拟合与错误假设的传播,科学家需在自动化流程普及的同时,掌握与 AI 协同工作的核心能力。
 夜雨聆风
夜雨聆风