 夜雨聆风
夜雨聆风你有没有碰到过这种崩溃时刻:让AI帮你查一篇顶刊,要么搜索半天PDF卡死,要么乱编数据,疯狂吞Token烧钱?
今天要聊的DeepXiv-SDK,就是来给科研智能体 “开挂” 的神器 —— 它把 arXiv 上近 300 万篇杂乱论文,变成 AI 能秒读、精准查、省钱读的结构化数据接口,让智能体从此告别 “啃 PDF”,直接 “吃营养餐”。
一、先搞懂:AI 读论文到底有多难?
想象一下,你让 AI 做个小任务:
帮我找出近一个月 HLE 任务效果最好、最火的 3 篇论文,把实验数据整理成表。
传统 AI 的操作是这样的:
先去搜索引擎里像没头苍蝇一样撞一通; 好不容易拉回来一堆 PDF,发现排版全是“人类迷惑行为”(两栏、图表、奇怪的换行符); 为了找到一句实验结果,它不得不把整篇几万字的文章全吞进肚子里(Context Window 瞬间爆满); 结果:Token 烧没了,老板的钱包瘪了,你想要的表还没出来。
这个流程就像让一个没带眼镜的人,在满是纸屑的房间里找一根针。结果只能是:又慢、又贵、又不准。
问题根源很简单:
论文是给人看的,不是给 AI 看的!
PDF、HTML 全是人类视觉友好的排版,对 AI 来说全是噪音,没有结构、没有索引、没有成本提示,读起来全是内耗。
二、DeepXiv 到底是什么?
DeepXiv-SDK 是专为 AI 智能体打造的科研文献数据接口。它干了一件事:把人类可读的杂乱论文 → 变成 AI 可用的标准化数据对象。
它有三个灵魂设计,像给 AI 配了三件神装:
结构化归一化:统一 JSON 格式,标题、作者、章节、公式、代码链接全部分类装好; 渐进式阅读:先看标题摘要→再看章节→最后才读全文,按需读取,不浪费 Token; 混合条件检索:按时间、作者、引用、热度精准筛选,不用全文扫一遍才找到目标。
简单说:DeepXiv 让 AI 读论文,像人查字典一样轻松。
三、DeepXiv的三把钥匙
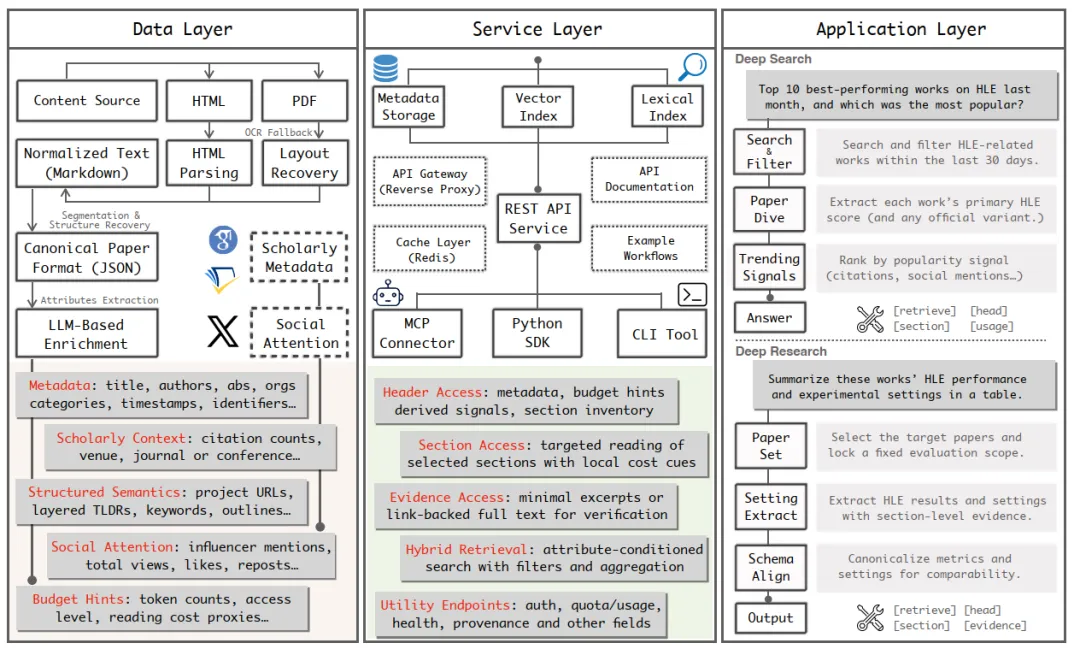
DeepXiv 的核心是三层架构,从数据清洗到服务调用,再到直接用的智能体,层层递进,丝滑无比。
1. 数据层:把论文“翻译“成AI的语言
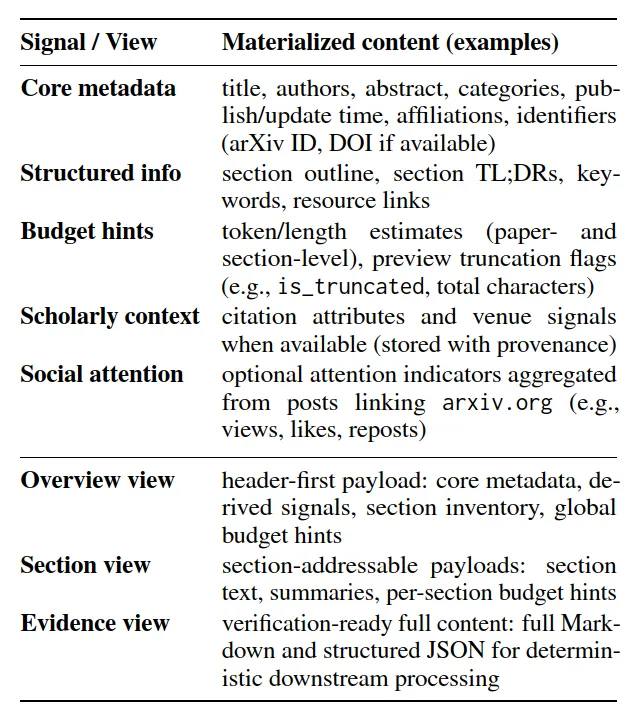
这一层是幕后清洁工 + 营养师,把乱糟糟的 PDF/HTML,变成规整的 JSON。
拆解结构:把"引言""方法""实验"分得清清楚楚 贴上标签:这篇论文讲什么?用一句话说清楚 计算成本:读完整篇要花多少token?每个章节又要多少? 附赠小抄:每章一个摘要,AI可以先看目录再决定读哪里
最终输出三种 “阅读套餐”,AI 按需点单:
先看标题和作者(成本:几乎为零) 觉得有意思?看看摘要和章节列表(成本:几百token) 需要某个具体信息?只读那一章(成本:几千token) 必须核实证据?好吧,读全文(成本:这才花大钱)
2. 服务层:AI 的 “论文外卖平台”
数据层做好菜,服务层就是外卖平台,提供稳定、高速、可监控的调用接口。
它给 AI 准备了三种 “点餐方式”:
Python SDK:一行代码调用,集成到自己的智能体; CLI 命令行:脚本党狂喜,直接跑批量检索、批量分析; MCP 连接器:无缝插进主流智能体框架,开箱即用。
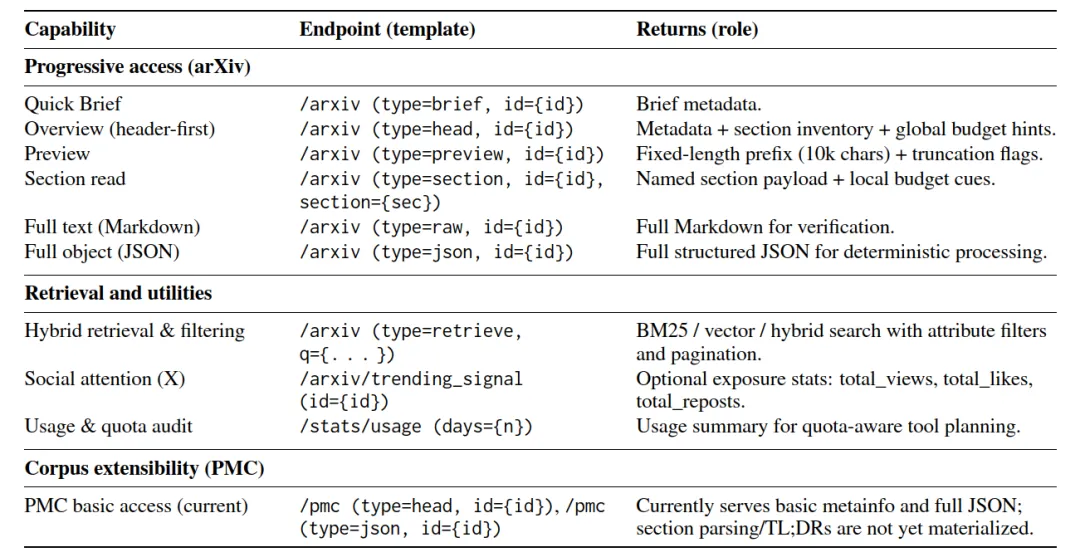
核心 API 超直观,举几个例子:
/arxiv?type=head&id=xxx:拿概览,极低 Token;/arxiv?type=section&id=xxx§ion=Introduction:只读引言;/arxiv?type=retrieve&q=HLE:条件检索,过滤时间、引用、类别。
再加 Redis 缓存、Elasticsearch 检索,高并发、低延迟,每秒能扛住海量请求,智能体再也不会卡成 PPT。
3. 应用层:开箱即用的 “科研小助手”
为了让开发者能够更加方便,DeepXiv还直接打包封装了好几个常用工具:
Deep Search(深度搜索):指令→条件检索→概览快速筛选→排序输出。几秒锁定目标论文。
Deep Research(深度调研):找论文→筛章节→抽数据→对指标→生成带证据的总结 / 表格。全自动产出科研报告。
如果你懒得自己调用API,DeepXiv内置了一个专门读论文的AI助手
import deepxivagent = deepxiv.agent()result = agent.query("找出上个月关于RAG的所有论文,对比它们的实验效果")DeepXiv 智能体自己就干完了,不用你管 PDF、不用你算 Token、不用你核对证据。
四、核心理念
DeepXiv 最牛的一点,是按 “知识密度” 渐进披露,用公式表达就是:
有效信息密度 = (结构化语义 + 预算感知 + 混合检索) ÷ token 消耗
让我解释一下这个公式:
分子越大越好:结构越清晰、预算越明、检索越准,信息就越有价值 分母越小越好:token 消耗越少,效率就越高
对应阅读路径:概览筛选 → 章节精读 → 全文核验。
好处直白到爆炸:
省 Token:不用全文塞进模型,无效阅读直接砍掉; 速度快:筛选 100 篇论文,只看概览,几秒搞定; 更准确:按结构读取,不会把页码、脚注当成正文; 可复现:固定 JSON 结构,每次读取结果一模一样,不玄学。
对比传统 “下载→解析→全文喂模型” 流水线,处理 1000 篇论文,DeepXiv 能快 50 倍以上,Token 开销砍半。
五、实测有多强?数据说话
DeepXiv 不是纸上谈兵,论文里放了硬核测试:
场景一:AI找论文(Deep Search)
开发者设计了50个"地狱级难度"的检索任务,每个任务只有一个正确答案。比如:
"找出那篇提出用想象力驱动的智能体,能在冲突环境中平衡救援和自保的论文"
结果?DeepXiv 不仅找到了,而且:
Recall@10 远超Google Scholar、PASA等对手 搜索延迟 只有对手的一半不到
秘诀是什么?因为我不需要读全文就能判断相关性。先看标题摘要,有希望再看章节小抄,确认了才读全文——省时省力还准确。
场景二:AI做研究综述(Deep Research)
47个复杂问答任务,要求AI综合多篇论文给出有证据支撑的答案。
对比传统的"搜索→读全文"方案:
Token消耗减少 约40% 回答质量提升 显著 完成时间缩短 近一半
为什么?因为AI只读了真正需要读的内容,而不是把几十篇论文全文都塞进context里"大海捞针"。
六、总结
过去,AI 读论文像在垃圾堆里找宝藏;
有了 DeepXiv,AI 读论文像在超市里按清单购物。
它的核心价值,用三句话总结:
结构统一:PDF/HTML→标准 JSON,AI 零门槛理解; 渐进阅读:筛选→精读→核验,省 Token、提速度、增准确; 开箱即用:SDK+CLI+MCP,集成简单,智能体直接上岗。
如果你在做科研、写论文、开发 AI 助手,DeepXiv 就是那个能让你效率翻倍、痛苦减半的神器。
项目地址:https://github.com/DeepXiv/deepxiv_sdk
论文地址:https://arxiv.org/pdf/2603.00084
