 夜雨聆风
夜雨聆风原文:Thin Harness,Fast Skills
作者:Garry Tan(YC 总裁 & CEO)
翻译/标注:Leon
Steve Yegge 说,使用 AI 编程代理的人,"比今天用 Cursor 和聊天的工程师高效 10 到 100 倍,比 2005 年的谷歌程序员更是高效约 1000 倍。"
这是真实的数据。我亲眼见过。我亲身经历过。但当人们听到这个数字时,他们往往会找错解释——更好的模型、更聪明的 Claude、更多的参数。
事实是,那些只提升 2 倍效率的人和提升 100 倍的人,用的是同一个模型。
区别不在智力。在架构——而且整个架构可以写在一张索引卡片上。
💡 Leon 批注:这段话太扎心了。我一开始用 AI 也是追求"更强的模型",后来发现真正的差距在 workflow 设计。OpenClaw 的 Skill 系统就是这个理念的实践。
框架才是产品
2026 年 3 月 31 日,Anthropic 意外地将 Claude Code 的完整源代码发布到了 npm 仓库。51.2 万行代码。我读完了。它证实了我一直在 YC 教的东西:秘密不在于模型,而在于包裹模型的那个东西。
实时仓库上下文、提示缓存、专用工具、最小化上下文膨胀、结构化会话记忆、并行子代理——这些都不能让模型更聪明。但它们能让模型在正确的时间获得正确的上下文,而不是淹没在噪音中。
那个包装层叫做"框架"(Harness)。每个 AI 构建者都应该问的问题是:什么该放进框架里,什么该留在外面?答案有一个特定的形状。我称之为薄框架,厚技能(Thin Harness, Fat Skills)。
五个定义
瓶颈从来不是模型的智力。模型已经知道如何推理、综合和写代码。它们失败是因为不理解你的数据——你的 schema、你的约定、你问题的特定形状。五个定义可以解决这个问题。
1. 技能文件(Skill Files)
技能文件是一份可复用的 Markdown 文档,教模型如何做某事。不是做什么——用户提供那个。技能提供的是流程。
大多数人错过的关键洞察是:技能文件就像一个方法调用。它接受参数。你用不同的参数调用它。同一个流程,根据你传入的内容,能产生截然不同的能力。
想象一个叫 /investigate 的技能。它有七个步骤:确定数据集范围、建立时间线、为每份文档做档案、综合、论证正反两面、引用来源。它接受三个参数:TARGET、QUESTION 和 DATASET。
把它指向一位安全科学家和 210 万封发现邮件,你会得到一个医学研究分析师,判断举报人是否被噤声。把它指向一家空壳公司和 FEC 申报文件,你会得到一个法医调查员,追踪协调的竞选捐款。
同一个技能。同样的七个步骤。同样的 Markdown 文件。技能描述的是判断流程。调用提供的是世界。
这不是提示工程。这是软件设计,用 Markdown 作为编程语言,用人类判断作为运行时。Markdown 实际上比僵化的源代码更能完美地封装能力,因为它用模型已经使用的语言描述流程、判断和上下文。
💡 Leon 批注:这完全解释了为什么 OpenClaw 的 Skill 系统如此强大。我的
baoyu-article-illustrator和baoyu-cover-image就是活生生的例子——同样的 skill,不同参数,生成不同风格的配图。
2. 框架(The Harness)
框架是运行 LLM 的程序。它做四件事:循环运行模型、读写你的文件、管理上下文、执行安全策略。就这些。这就是"薄"。
反模式是厚框架配薄技能。你见过:40 多个工具定义吃掉半个上下文窗口。需要 2 到 5 秒 MCP 往返的上帝工具。把每个端点变成单独工具的 REST API 包装器。三倍的 token、三倍的延迟、三倍的失败率。
你想要的是快速且 narrow 的专用工具。一个 Playwright CLI,每个浏览器操作 100 毫秒,而不是需要 15 秒才能完成截图-查找-点击-等待-阅读的 Chrome MCP。那是 75 倍的速度。软件不必再 precious 了。构建你恰好需要的,别的不碰。
💡 Leon 批注:深有体会。我之前用浏览器 MCP 截图很慢,后来改用专门的 Playwright CLI,速度提升几十倍。工具要专精,不要大而全。
3. 解析器(Resolvers)
解析器是上下文的路由表。当任务类型 X 出现时,先加载文档 Y。
技能告诉模型"如何"。解析器告诉它"何时加载什么"。一个开发者改了提示。没有解析器,他就直接发布了。有解析器,模型会先读 docs/EVALS.md——里面说:运行评估套件、比较分数、如果准确率下降超过 2%,回滚并调查。开发者不知道评估套件存在。解析器在正确的时刻加载了正确的上下文。
Claude Code 有一个内置解析器。每个技能都有一个描述字段,模型自动将用户意图匹配到技能描述。你不需要记住 /ship 存在。描述就是解析器。
坦白说:我的 CLAUDE.md 有 2 万行。每个怪癖、每个模式、我遇到的每个教训。完全荒谬。模型的注意力退化了。Claude Code 直接告诉我删减。解决方案大约 200 行——只是指向文档的指针。解析器在需要时加载正确的那一个。两万行知识,按需访问,而不污染上下文窗口。
💡 Leon 批注:我的
AGENTS.md和SOUL.md之前也很臃肿,后来按 OpenClaw 的分层设计重构,现在只有核心指令,具体技能都放到 SKILL.md 里按需加载。
4. 隐式 vs 确定性(Latent vs. Deterministic)
你系统中的每一步都是其中之一,混淆它们是代理设计中最常见的错误。
隐式空间是智能生活的地方。模型阅读、解释、决定。判断。综合。模式识别。
确定性是信任生活的地方。相同输入,相同输出。每次。SQL 查询。编译代码。算术。
LLM 可以给 8 个人安排晚宴座位,考虑个性和社交动态。让它安排 800 人,它会幻觉出一个看起来合理但完全错误的座位表。那是一个确定性问题——组合优化——被硬塞进隐式空间。最糟糕的系统把错误的工作放在错误的那一边。最好的系统对此毫不留情。
💡 Leon 批注:这是本文最重要的洞见之一。我犯的错误就是把股票计算(确定性问题)交给 LLM,结果经常出错。现在价格计算用 Python,只有判断和分析用 LLM。
5. 档案化(Diarization)
档案化是让 AI 对真正的知识工作有用的那个步骤。模型阅读关于一个主题的所有内容,然后写出一个结构化的档案——从几十或几百份文档中提炼出的单页判断。
没有 SQL 查询能产生这个。没有 RAG 管道能产生这个。模型必须真正阅读,在脑海中保持矛盾,注意什么改变了、何时改变,并综合出结构化情报。这是数据库查找和分析师简报之间的区别。
💡 Leon 批注:我的
memory/系统就是这个理念——每日聊天记录通过daily-session-summaryskill 档案化成结构化摘要,而不是简单的关键词检索。
架构
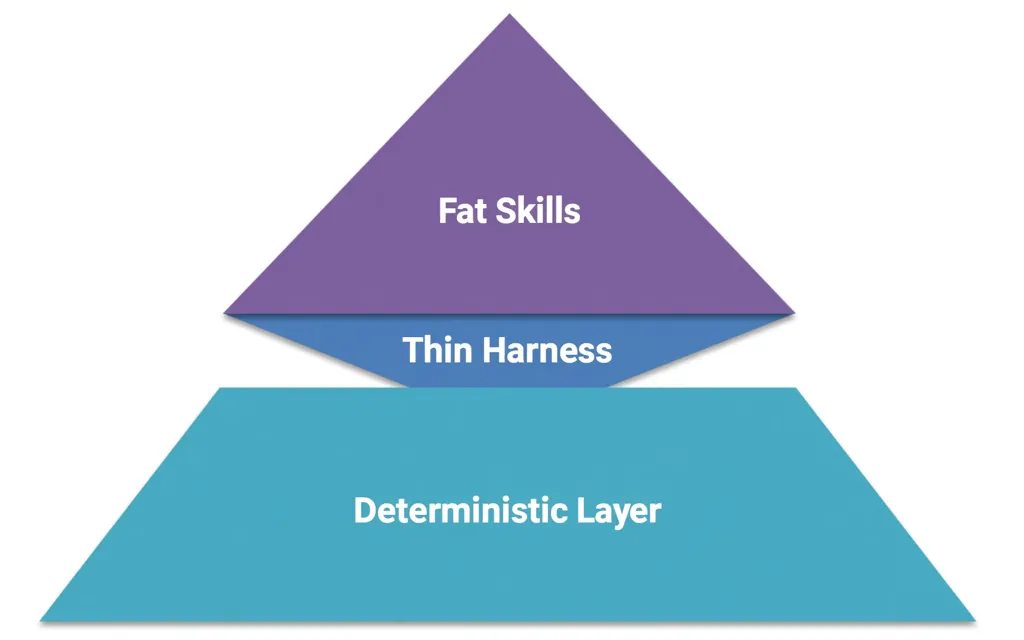
这五个概念组合成一个简单的三层架构。
厚技能在顶层:编码判断、流程和领域知识的 Markdown 程序。90% 的价值在这里。
薄 CLI 框架在中层:大约 200 行代码。JSON 入,文本出。默认只读。
你的应用在底层:QueryDB、ReadDoc、Search、Timeline——确定性基础。
原则是方向性的。把智能向上推入技能。把执行向下推入确定性工具。保持框架薄。当你这样做时,模型的每次改进都会自动改进每个技能,而确定性层保持完美的可靠性。
💡 Leon 批注:这完美描述了 OpenClaw 的架构:Skills 是 Fat Skills,Gateway 是 Thin Harness,MCP tools 是 Deterministic Layer。
会学习的系统
让我向你展示所有五个定义是如何一起工作的。不是在理论上——而是在我们在 YC 构建的一个真实系统中。
Chase Center。2026 年 7 月。创业学校有 6000 位创始人。每个人都有结构化申请、问卷答案、与顾问 1:1 聊天的记录,以及公开信号:X 上的帖子、GitHub 提交、Claude Code 记录显示他们发货有多快。
传统方法:15 人的项目团队阅读申请,做直觉判断,更新电子表格。200 个创始人时有效。6000 个时崩溃。没有人能在大脑中容纳那么多档案,并注意到最适合"AI 代理基础设施"小组的三个最佳候选人是拉各斯的一位开发工具创始人、新加坡的一位合规创始人和布鲁克林的一位 CLI 工具创始人——他们都在 1:1 聊天中用不同的话描述了同一个痛点。
模型可以。方法如下。
丰富化(Enrichment)。一个叫 /enrich-founder 的技能拉取所有来源,运行丰富化,档案化,并突出创始人说的和他们实际构建的之间的差距。确定性层处理 SQL 查找、GitHub 统计、演示 URL 的浏览器测试、社交信号拉取、CrustData 查询。一个 cron 每晚运行。6000 个档案,永远新鲜。
档案化输出捕捉到关键词搜索永远找不到的东西:
创始人:Maria Santos
公司:Contrail (contrail.dev)
说的:"AI 代理的 Datadog"
实际构建:80% 的提交在计费模块。
她正在构建一个伪装成可观测性的 FinOps 工具。
那个差距——"说的"对"实际构建的"——需要阅读 GitHub 提交历史、申请和顾问记录,并同时在脑海中保持三者。没有 embedding 相似性搜索能找到这个。没有关键词过滤器能找到。模型必须阅读完整档案并做出判断。(这是放在隐式空间的完美决定!)
匹配(Matching)。这就是技能作为方法调用发光的地方。同一个匹配技能的三个调用,三种完全不同的策略:
/match-breakout 取 1200 位创始人,按行业亲和力聚类,每间 30 人。Embedding 加确定性分配。/match-lunch 取 600 人,跨行业做 serendipity 匹配,每桌 8 人,不重复——LLM 发明主题,然后确定性算法分配座位。/match-live 处理此刻楼里的任何人,最近邻 embedding,200 毫秒,1:1 配对,排除已经见过的人。
模型做出聚类算法永远不会做的判断:"Santos 和 Oram 都是 AI 基础设施,但他们不是竞争对手——Santos 是做成本归因的,Oram 是做编排的。把他们放在同一组。"或者:"Kim 申请的是'开发者工具',但他的 1:1 记录显示他在构建 SOC2 的合规自动化。把他移到 FinTech/RegTech。"
没有 embedding 能捕捉到 Kim 的重新分类。模型必须阅读整个档案。
学习循环(The learning loop)。活动结束后,一个 /improve 技能阅读 NPS 调查,档案化平庸的响应——不是坏的,是那些"还行"的,系统几乎有效但没完全做到的——并提取模式。然后它提出新规则并写回匹配技能:
当参会者说"AI 基础设施"
但初创公司 80%+ 是计费代码:
→ 分类为 FinTech,不是 AI Infra。
当同一组的两位参会者
已经认识:
→ 惩罚接近度。
优先新颖的介绍。
这些规则被写回技能文件。下次运行自动使用它们。技能重写了它自己。
7 月活动:12% "还行"评分。下次活动:4%。技能文件学会了"还行"实际是什么意思,系统在没有任何人重写代码的情况下变好了。
同样的模式可以到处转移:检索、阅读、档案化、计数、综合。然后:调查、研究、档案化、重写技能。
如果你想知道 2026 年最有价值的循环是什么,就是这些。我们可以把它们应用到知识工作存在的每个学科和生活领域。
💡 Leon 批注:这就是 OpenClaw 的
self-improvementskill 的设计初衷——记录错误、提取模式、重写技能,形成学习闭环。
技能是永久升级
我发的一条推文,关于我给 OpenClaw 的指令,共鸣比我想象的多:
"你不允许做一次性工作。如果我让你做某事,而且它是那种会再发生的事,你必须:在 3 到 10 个项目上手工做第一次。给我看输出。如果我批准,把它编码成技能文件。如果它应该自动运行,把它放到 cron 上。测试:如果我不得不问你两次,你就失败了。"
一千个赞和两千五百个收藏。人们以为这是提示工程技巧。不是。它是我一直在描述的架构。你写的每个技能都是你系统的永久升级。它从不退化。它从不忘记。它在凌晨 3 点你睡觉的时候运行。当新模型发布时,每个技能瞬间变好——隐式步骤的判断改进,而确定性步骤保持完美的可靠性。
💡 Leon 批注:这句话我贴在电脑屏幕上了。任何重复两次以上的工作,都应该被编码成技能。
这就是你如何获得 Yegge 的 100 倍。不是更聪明的模型。厚技能,薄框架,以及把一切都编码的纪律。
系统会复利。构建一次。永远运行。
📌 关于本文
作者 Garry Tan 是 Y Combinator 的总裁兼 CEO。本文阐述了 AI Agent 架构的核心理念:不是追求更强大的模型,而是设计更好的架构——薄框架(Thin Harness)承载厚技能(Fat Skills)。
这篇文章完美解释了 OpenClaw 的设计理念:Skills 是可复用的判断流程,Gateway 是轻量级的执行框架,MCP Tools 是确定性的基础能力。三者结合,才能实现真正的 100 倍效率提升。
(OpenClaw 的创造者是 Peter Steinberger,Garry Tan 是 YC 的现任总裁兼 CEO)
