 夜雨聆风
夜雨聆风很多人把 Meta AI 这波爆发理解成:又一个 AI App 靠新模型冲上了榜单。
但真正值得警惕的,可能不是 Muse Spark 让它更聪明了,而是 Meta 把原本属于 Instagram 的熟人关系链,第一次更直接地接进了 AI 产品增长里。
你以为自己只是下载了一个 AI App,结果据 TechCrunch 报道与截图显示,朋友可能收到提示,也会因此知道你开始用了它。
这件事的重点,从来不只是"Meta AI 排名涨了"。更大的信号是:AI 产品的下一轮增长,也许不再只拼模型能力,而是开始拼谁更敢把社交关系、默认可见性和熟人压力,变成分发机器。
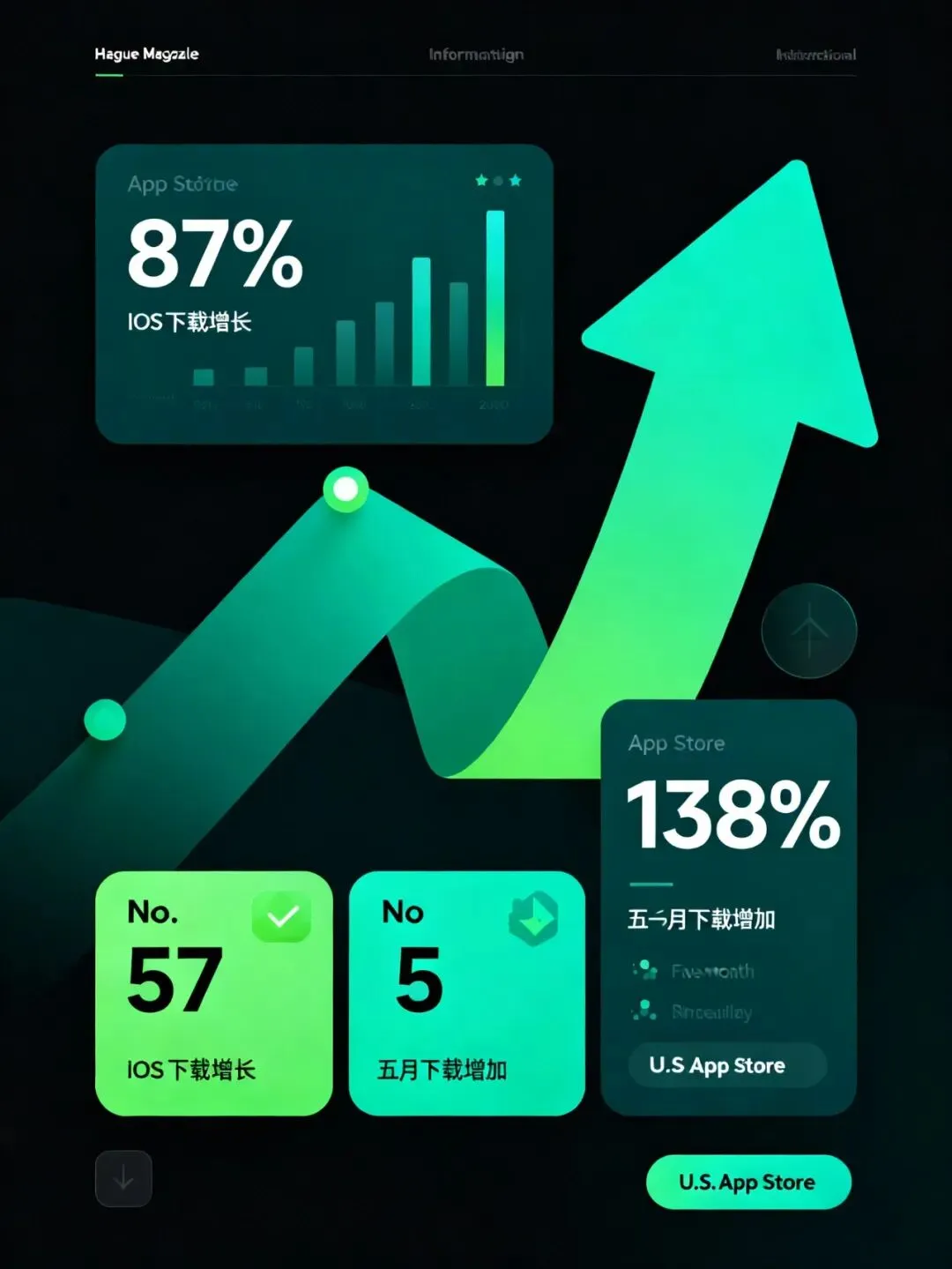
先看最容易被传播的那层新闻:Meta AI app 在美国 App Store 的排名迅速上涨。
根据研究资料汇总,Meta 官方在 2026 年 4 月 8 日发布了 Muse Spark,并明确表示这一模型当前已驱动 Meta AI app 和 meta.ai 的体验。随后,据 Appfigures 口径,Meta AI app 在美国 App Store 的排名从 No.57 升至 No.5,据 Sensor Tower 估计,4 月 8 日美国 iOS 下载量约 46,000 次,日环比增长 87%。
这些数字当然重要,但如果只盯着数字,反而容易看偏。
因为 Muse Spark 更像一个导火索,而不是全部答案。
今天大模型产品太多了,模型一升级就冲榜,已经不是新鲜事。真正稀缺的是:谁能把一次能力升级,迅速放大成社交网络里的可见事件,进而带来更低成本、更强传播性的新增量。
Meta 恰恰拥有这个条件。
和多数独立 AI 产品不同,Meta 不是从零开始做一个需要重新教育用户、重新购买流量的 App。它手里本来就有 Instagram、Facebook、Threads、Messenger、WhatsApp 这些入口,更关键的是,它手里还握着一张现成的关系图谱。
Meta 官方在发布 Muse Spark 时提到,未来的 Meta AI 会建立在用户生活中已经存在的 relationships and context 之上。翻成更直白的话就是:它不是只想让你"用一个 AI",而是想让 AI 嵌进你已经存在的社交关系里。
这就是 Meta AI 这波增长里最值得行业重视的一点:它不只是入口型分发,也不只是内容型推荐,而是关系链分发。
过去我们总以为 AI 增长主要看两件事:模型够不够强,产品够不够好用。但 Meta 这次给出的新变量是,哪怕模型升级是起点,真正把增长拉爆的,也可能是"谁先知道你在用"。
二、真正让人不舒服的,不是冲榜,而是"朋友可能知道你开始用了它"
这也是为什么 TechCrunch 4 月 10 日那篇报道,比单纯的下载新闻更值得看。
据 TechCrunch 报道与截图显示,用户在使用 Meta AI app 后,朋友可能会在 Instagram 收到相关提示。
报道还提到,这类提示的显眼程度接近"new follower"这类高注意力通知。注意,这里的表述必须很克制:目前最强证据来自媒体记者体验和截图,而不是 Meta 官方对机制细节的完整公开说明。
但即便如此,这已经足够说明问题。
因为它触碰到的,不是传统隐私争议里那种抽象的数据授权条款,而是一种更具体、更日常、也更容易让普通用户当场产生不适的场景:我只是想试试一个 AI App,为什么熟人网络可能会知道?
这类不适感,恰恰来自用户预期和平台机制之间的落差。
用户对社交产品的很多默认公开,其实是有心理预期的。比如你发了一条动态、关注了一个人、点赞了一条内容,被别人看到,很多人并不会完全意外,因为那本来就发生在"社交表达"环境里。
但 AI App 在很多人的想法里,更接近搜索、聊天、工具、陪伴或私人试验场。它带有更强的"半私密使用"属性。
一旦平台把这种行为外溢到熟人网络,它带来的就不是单纯曝光,而是社交压力。
尤其是 AI 仍处在一个微妙阶段:很多人会用,但未必想被朋友知道自己"怎么用、为什么用、是不是在偷偷依赖它"。
有的人担心尴尬,有的人担心被贴标签,有的人只是单纯不喜欢自己的新行为被系统抢先广播。于是,增长逻辑成立了,信任摩擦也同时冒出来了。
真正值得讨论的,不是"有没有通知"这么简单,而是它把一个原本更接近个人选择的 AI 使用行为,变成了一个可能被社交系统放大的公共信号。
三、这不是单点产品设计问题,而是一种新的AI增长范式
如果把这件事只理解成一次"通知设计翻车",那就低估了它的行业意义。
更准确的看法是:Meta 正在尝试把 AI 产品增长,从"能力驱动"推进到"关系驱动"。
在上一轮 AI 产品竞争里,大家熟悉的打法主要有三种。
第一种是 ChatGPT 路线:靠品牌认知、模型能力、口碑外溢和产品延展来拉新。用户会因为它强、通用、被广泛讨论而下载,也会因为插件、工作流、办公场景继续留存。它的增长核心,更像"产品被证明有用,所以用户主动来"。
第二种是 Gemini 路线:靠 Google 自带的系统入口、搜索入口和 Assistant 替换能力把用户带进来。它的优势更像"系统默认分发",用户也许不是强烈主动下载,但会因为设备、系统和服务整合而接触到它。
第三种就是 Meta AI 这次显露出来的路线:不仅有产品矩阵入口,还有熟人关系链外溢。
它不是只把 AI 放在你的手机里,也不是只把 AI 放在系统入口里,而是进一步把 AI 使用状态变成社交世界里可能被感知、被讨论、被模仿的事件。
这三种路径的区别,非常关键。
ChatGPT 主要是在争夺"认知入口";Gemini 主要是在争夺"系统入口";Meta AI 更像是在争夺"关系入口"。而关系入口往往是效率最高、成本最低、扩散最快的一种分发方式,因为熟人可见本身就会制造从众、好奇和试用。
这就是为什么 Meta AI 这波爆发,不能只看成"又一个 AI App 上榜"。它更像是整个行业在试探一个新问题:如果模型能力差距越来越难一眼拉开,平台是否会越来越依赖熟人网络,来弥补获客成本和增长压力?

一旦答案是"会",那未来被讨论的就不只是 Meta。
四、问题不在于它有没有增长,而在于增长是否建立在用户没准备好的边界上
站在增长视角,这套机制几乎可以理解。
一个成熟平台最擅长的事,本来就不是发明全新流量,而是把现有行为重新组织成更高效率的转化漏斗。
如果一个用户开始使用 Meta AI,而他的朋友又恰好活跃在 Instagram 上,那么让"朋友可能看到这个行为"就会天然形成扩散链条:注意到、好奇、点击、尝试、跟进。
从增长语言看,这叫降低冷启动成本。从用户语言看,这可能叫"我还没来得及决定要不要公开,系统已经替我往前走了一步"。
这就是整件事最敏感的地方。
很多平台型产品在在做增长时,都会借助默认设置、入口联动、社交暗示、熟人提醒这些机制。但 AI 产品和传统内容产品不一样。
用户对 AI 的使用,往往混合了搜索、求助、试探、表达、情绪处理甚至工作依赖。也就是说,它天然比"刷视频""看帖子"更容易被用户归入个人空间。
当平台把这种行为转化成一种社交信号时,用户真正反感的,不一定是某一个通知本身,而是那种边界被提前决定的感觉。
而且这里还有一个必须保持克制的事实:截至目前,公开资料中并未看到 Meta 对这轮隐私争议机制给出足够细的公开解释,也未见明确的单独关闭说明。
于是,这篇文章不能写"Meta 已承认隐私问题",也不能写"所有好友都会收到通知",更不能写"用户无法关闭"。
但正因为这些细节仍不透明,用户的不安才更容易被放大。因为不透明本身,就是信任成本的一部分。
五、谁最该警惕这件事?不只是普通用户,更是所有做AI产品的人
从普通用户视角,这件事提醒的是一件很现实的小事:以后你装的,不一定只是一个 AI 工具,也可能是一套会沿着平台关系链扩散的产品机制。
哪怕到头来证明通知范围有限、可控、可调整,用户也会开始重新评估一个问题:我对 AI 的使用,到底算不算私域行为?
但从行业视角,这件事更值得警惕。
因为它可能意味着,AI 产品竞争正在进入一个新的阶段:模型能力仍然核心,但增长红利会越来越多地来自"谁拥有更强的现实分发底盘"。而在所有分发底盘里,社交关系链的威力一直是最大的,也是最容易跨过用户心理边界的。
今天是 Meta AI。明天可能是任何拥有聊天入口、社交图谱、系统默认位或内容网络的平台。大家都会发现,把 AI 做成"朋友会知道你用了"的产品,也许远比把 AI 再做聪明一点,更能短期撬动数据。
问题是,短期增长往往最会掩盖长期代价。
一旦用户开始把 AI 产品和"被看见""被误解""被系统代替做公开决定"联系在一起,那么平台换来的可能不只是下载,也包括更高的戒备、更低的信任,以及下一次功能联动时更强的防御心理。
说白了,Meta AI 这波事件真正值得写进行业观察的,不是它有没有赢一次冲榜,而是它把一件事提前暴露出来了:下一轮 AI 增长,最危险也最有效的方式,可能就是把社交关系变成分发引擎。
而一旦增长引擎建立在边界感被压缩之上,反噬也只是时间问题。
💡闲菜哥结语
如果你只把 Meta AI 这次看成"新模型带动下载上涨",那这条新闻很快就会过去。
但如果你看到的是另一层:AI 产品开始借熟人关系链制造扩散,而且这种扩散可能先于用户的明确知情与边界确认,那它就不是 Meta 一家的小风波,而是整个行业接下来都会面对的增长命题。
模型会越来越像,入口会越来越贵,真正决定增长效率的,可能是平台敢不敢把"你和朋友的关系"也拉进来。
问题只剩一个:当 AI 增长越来越依赖"被别人知道你在用",你还会把它当成一个纯粹的私人工具吗?
#MetaAI #Instagram #AI隐私 #社交分发 #AI增长 #产品运营
