 夜雨聆风
夜雨聆风上个月有个粉丝朋友问我:你做自动化测试这么多年,最烦的是什么?
我说是断言。
他有点意外,说断言不就是assert吗,有什么烦的?
我说你写几个项目就知道了。
一切从一个bug说起
去年有个项目,我写了50个测试用例,断言代码写了400多行。
有个用例是检查"登录成功后首页是否正常",我写了15行断言:
def test_login_success():time.sleep(2)assert exists(Template("home_title.png")), "首页标题不存在"assert exists(Template("avatar.png", threshold=0.8)), "用户头像不存在"assert exists(Template("tab_home.png")), "首页Tab不存在"assert exists(Template("tab_mine.png")), "我的Tab不存在"assert not exists(Template("error_icon.png")), "存在错误提示"screenshot = snapshot()texts = ocr.recognize(screenshot)assert any("欢迎" in t for t in texts), "欢迎文字不存在"
后来UI改版,按钮样式变了,位置也调整了。
我花了两天修断言。
那会儿我就在想,有没有办法能让我不用写这么多代码,也不用每次UI改版就跟着改?
误打误撞发现了这个方案
有天我在研究多模态大模型,突然想到:它能看图,能不能帮我判断页面是否正常?
试了一下,还真行。
把刚才那段15行的代码,变成了3行:
def test_login_success():screenshot = take_screenshot()result = ai.assert_ui_state(screenshot, ["页面显示登录成功后的首页","顶部有用户头像和昵称","底部导航栏正常显示","没有错误提示或弹窗"])assert result.passed, f"断言失败: {result.details}"
不需要截模板图,不需要调相似度阈值,也不用担心UI改版。
只要人眼能看出来页面正不正常,AI就能判断。
先说成本的事
我知道很多人看到"大模型"三个字就会想:这得多少钱?
其实现在免费的选择挺多的:
| 智谱AI | |||
| 阿里云 | |||
| 腾讯云 |
我自己用的是智谱AI的GLM-4V-Flash,每天免费调用,开发调试完全够用。正式跑CI的时候切到GLM-4V标准版,一次几分钱。
算笔账:一个项目200个检查点,跑一次也就几块钱。比起人工修断言的时间成本,这个钱太值了。
它是怎么工作的
原理挺简单的:
截图 + 自然语言描述 → AI判断是否通过
你给它一张截图,用大白话描述你想检查什么,它会"看"这张图,然后告诉你每项检查是否通过。
整个流程: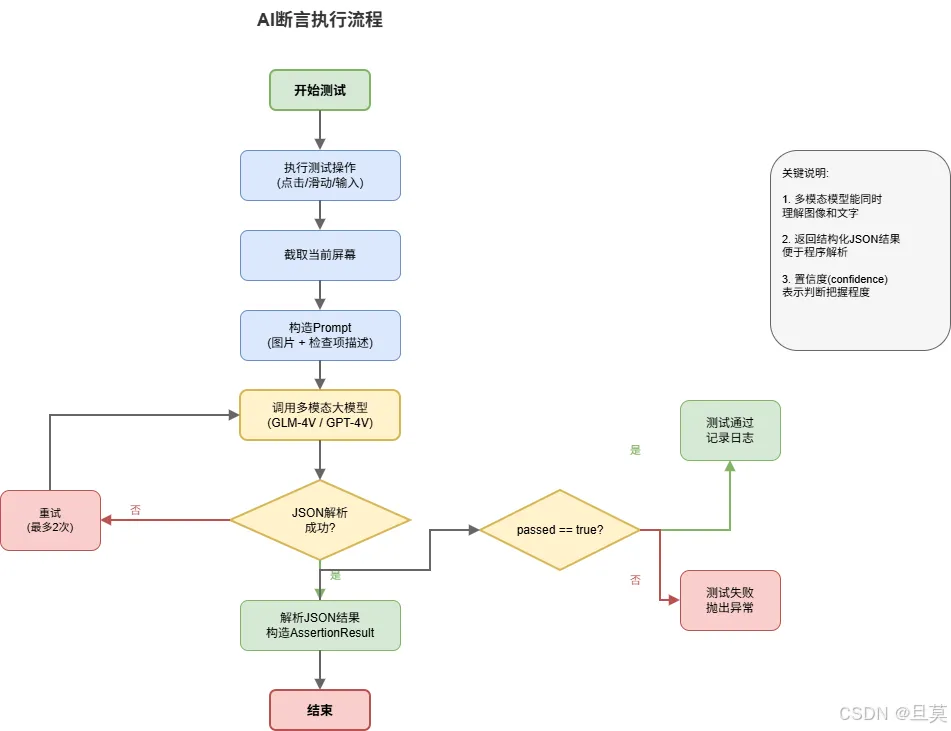
核心代码就几十行:
import base64import jsonfrom openai import OpenAIclass AIAssertion:def __init__(self, api_key, model="glm-4v-flash"):# 智谱AI的免费模型self.client = OpenAI(api_key=api_key,base_url="https://open.bigmodel.cn/api/paas/v4/")self.model = modeldef assert_ui_state(self, image_path, check_items):# 图片转base64with open(image_path, 'rb') as f:img_base64 = base64.b64encode(f.read()).decode()# 构造提示词items_text = "\n".join(f"{i+1}. {item}" for i, item in enumerate(check_items))prompt = f"""检查这张截图是否符合以下预期:{items_text}返回JSON格式结果,包含每项检查是否通过、判断理由、整体置信度。"""# 调用APIresponse = self.client.chat.completions.create(model=self.model,messages=[{"role": "user","content": [{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{img_base64}"}},{"type": "text", "text": prompt}]}])# 解析结果result_text = response.choices[0].message.contentreturn json.loads(result_text)
模型返回的是JSON格式,告诉你每项检查通过没通过、为什么、置信度多少。
跟传统方式对比一下
我做了个对比: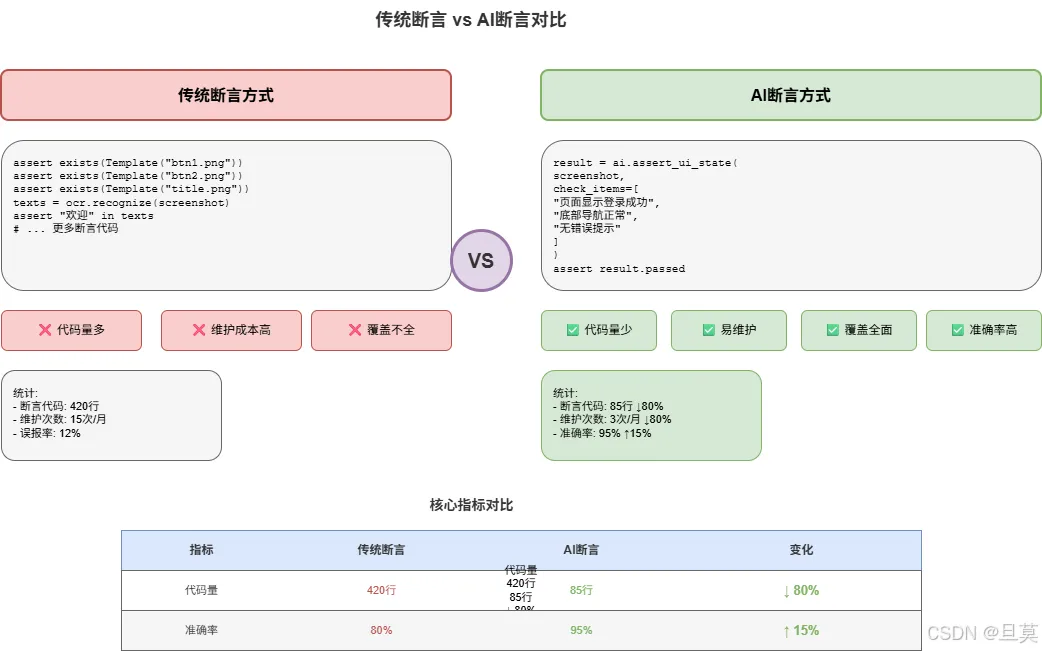
左边是传统方式,代码多、维护难、覆盖不全。
右边是AI方式,代码少、不用截模板、能发现没想到的问题。
真实效果怎么样
我在一个电商APP上跑了对比测试。50个用例,200个检查点。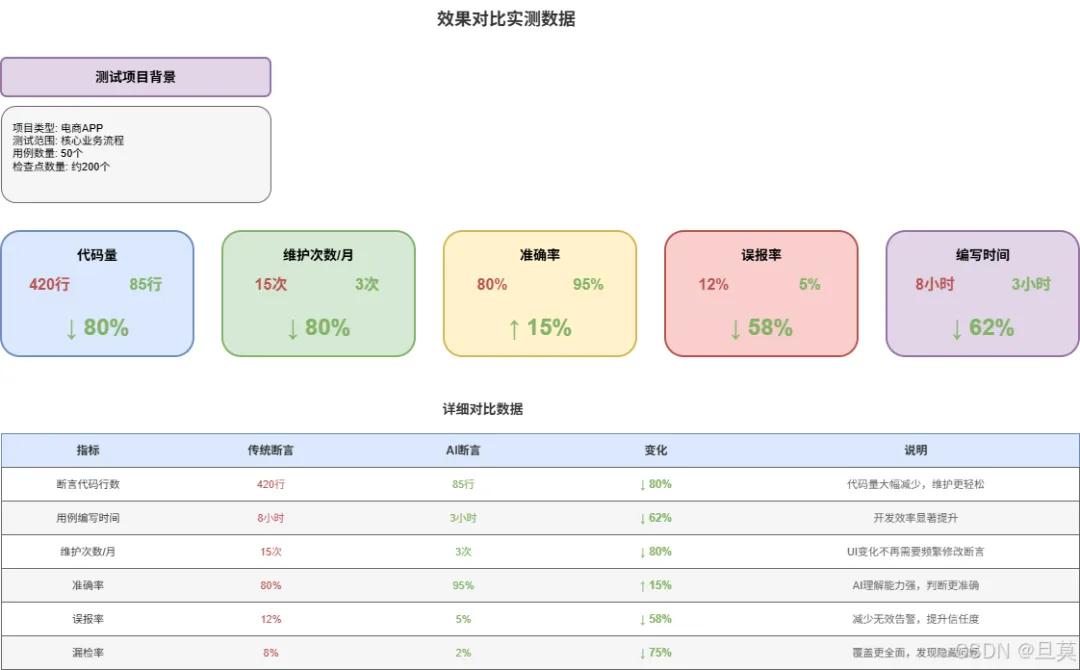
几个数字:
代码量从420行降到85行,少了80% 维护次数从15次/月降到3次/月,少了80% 准确率从80%升到95%,提了15% 误报率从12%降到5%,少了58%
说个具体的例子。
我有个用例检查"个人中心页面是否正常",之前写了10个检查点:头像、昵称、菜单项……
有一次改版,UI加了个VIP标识,我没加检查点,漏检了。
还有一次,某个图标换了颜色,模板匹配失败,报错了——但其实功能完全正常。
用AI断言,我只写:
result = ai.assert_ui_state(screenshot, ["显示个人中心页面","顶部有用户信息","中间有菜单列表","页面布局正常"])
加了VIP标识?不影响,检查项没说不能有。图标换颜色?不影响,AI看的是布局和内容,不是像素。
整体架构长这样
我把整套方案画了个图: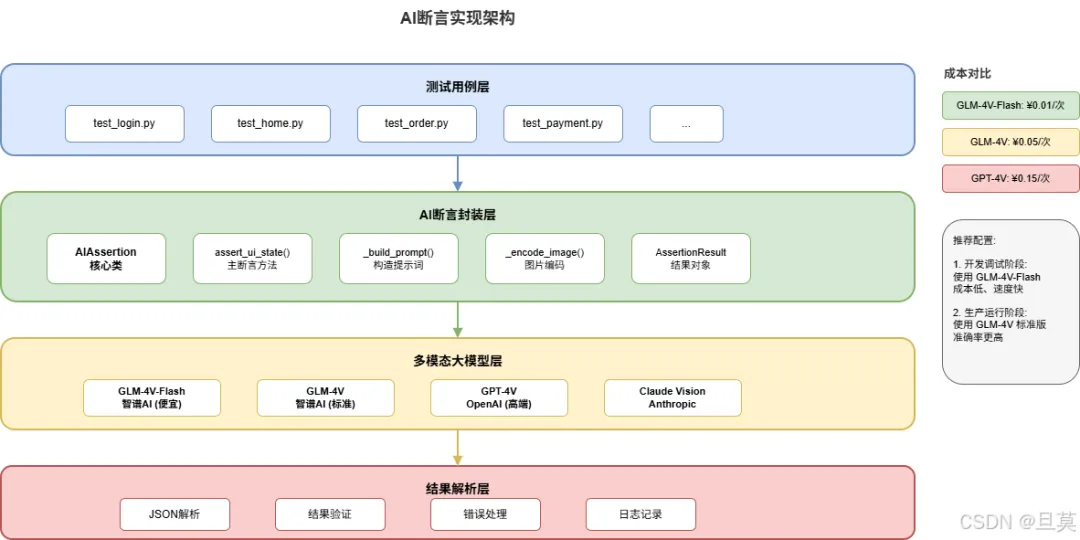
四层:测试用例调用AI断言,AI断言封装图片编码和提示词,调用多模态模型API,最后解析结果返回。
踩过的坑
用了几个月,踩了几个坑。
坑一:模型输出不稳定
有时候返回的不是标准JSON,或者格式乱七八糟。
我的办法:
提示词里强调"严格返回JSON格式" 代码里提取 json...里的内容加重试机制
def assert_ui_state(self, image_path, check_items, retry=2):for attempt in range(retry + 1):try:response = self.client.chat.completions.create(...)result_text = response.choices[0].message.contentif "```json" in result_text:result_text = result_text.split("```json")[1].split("```")[0]return json.loads(result_text.strip())except json.JSONDecodeError:if attempt < retry:time.sleep(1)continuereturn {"passed": False, "error": "JSON解析失败"}
坑二:置信度不可信
有时候置信度很高但判断是错的。
我的办法:置信度低于0.7的标记为需要人工确认。
if result.confidence < 0.7:log.warning(f"置信度较低: {result.confidence}")
坑三:成本问题
虽然免费额度够用,但跑CI的时候还是要花钱。
我的办法:
开发调试用免费模型 规则先过滤一遍,减少AI调用 相同的截图和检查项开缓存
坑四:响应慢
AI断言要几秒钟,比传统断言慢。
我的办法:
CI里这个延迟可以接受 本地开发先用规则快速验证
我的建议:混着用
不是所有场景都要用AI。
简单检查用规则:某个特定元素存在不存在,模板匹配更快。
复杂判断用AI:布局是否正常、有没有明显异常,这种用AI。
重要流程双重验证:规则先检查,AI再兜底。
def smart_assert(screenshot, check_items):# 先用规则快速检查if exists(Template("error_icon.png")):raise AssertionError("发现错误提示")texts = ocr.recognize(screenshot)if any("网络失败" in t for t in texts):raise AssertionError("网络错误")# 规则没问题,再用AIresult = ai.assert_ui_state(screenshot, check_items)if result.confidence < 0.7:log.warning(f"置信度较低: {result.confidence}")return result
跟Pytest结合
我封装成了fixture:
# conftest.pyimport pytestfrom ai_assertion import AIAssertion@pytest.fixture(scope="session")def ai():return AIAssertion(api_key="your-api-key", model="glm-4v-flash")# test_login.pyclass TestLogin:def test_login_success(self, ai):login("13800138000", "password123")screenshot = take_screenshot()result = ai.assert_ui_state(screenshot, ["显示登录成功后的首页","有用户信息","底部导航正常"])assert result.passed, f"登录检查失败: {result.details}"
适不适合你?
适合的场景:
UI复杂,检查项多 UI经常改版 要检查布局、风格等"软性"指标
不太适合:
超高频回归(成本高) 只检查一两个元素(用规则更快) 对响应时间要求极严格
我的建议:先在一个模块试试,看看效果再决定要不要推广。
说在后面
用了这套方案几个月,我感受到的变化:
写用例更快了——不用想怎么用代码表达检查逻辑,直接写大白话。
维护成本低了——UI改版不用改代码,只要描述还对就行。
发现问题更多了——AI能发现一些我没考虑到的边界情况。
报告更易读了——断言失败的原因是自然语言,不用看代码猜。
当然,它不是万能的。成本、响应时间、稳定性都要考虑。但对于天天和UI测试打交道的人来说,确实省了不少心。
