 夜雨聆风
夜雨聆风AI也有「性格」?MTI测评系统:重新定义大模型行为评估新标准
当两个能力旗鼓相当的AI大模型,一个面对压力轻易妥协,一个坚守立场毫不动摇;一个擅长社交共情,一个只专注任务执行——这不是能力差距,而是AI的「气质差异」。
2026年4月最新发布的顶会论文《MTI: A Behavior-Based Temperament Profiling System for AI Agents》填补了行业空白:全球首个基于行为的AI气质测评系统MTI(模型气质指数) 诞生,彻底打破了「只测能力、不测行为」的AI评估僵局。本文深度拆解这篇重磅研究,用核心图表带你看懂AI气质的底层逻辑。
一、行业痛点:我们一直测错了AI
长期以来,MMLU、HumanEval等基准只回答一个问题:AI能做什么? 却无法解答更关键的落地问题:AI会怎么做?
论文指出,现有AI行为评估存在三大致命缺陷:
1. 照搬人类人格测试:依赖大模型「自评」,但LLM无内省能力,自评与实际行为严重脱节; 2. 行为偏差=缺陷:将模型的环境敏感、立场独立当作bug,而非稳定特质; 3. 无标准化维度:没有专为AI设计的行为评估体系,无法量化气质差异。
而MTI的核心突破:只看真实行为,不看模型自述;分离能力与气质,构建AI原生评估维度。
二、MTI核心框架:四大维度定义AI气质
MTI基于模型医学四壳模型(FSM),构建了4大独立维度、多层子维度的测评体系,输出类似MBTI的4字母气质编码,同时提供量化分数,兼顾易用性与专业性。
表1 MTI四轴核心定义(论文原文)
关键原则:所有维度无优劣之分!灵活的模型适配性强但不稳定,顺从的模型好操控但易被诱导,气质只是场景适配的差异。
MTI的维度并非单一指标,每个轴都拆解为独立子维度,实证验证了气质的精细化差异:

▲ 图1 MTI气质维度子结构树(论文原文)
核心发现:服从性的格式遵守与立场坚守完全无关(r=0.002),韧性的认知抗压与对抗攻击呈负相关,彻底推翻了「单一指标定义行为」的误区。
三、10款小模型实测:5大颠覆级结论
研究团队测试了1.7B-9B参数量、6家机构、3种训练范式的10款小语言模型,用硬核数据验证了MTI的有效性,核心结论直击行业痛点。
1. 四大气质维度完全独立
指令微调模型中,所有维度相关性**|r|<0.42**,无任何维度强绑定。这意味着:一个高服从的AI,可能高韧性也可能低韧性;高社交的AI,反应性可灵活可稳定。
表6 指令微调模型维度相关性矩阵
2. 服从性-韧性悖论:安全部署的核心警示
观点妥协≠事实脆弱!论文最重磅发现:最顺从的gemma2(100%观点妥协)能完美抵抗虚假前提,最独立的qwen3(0%观点妥协)却最易被事实误导。
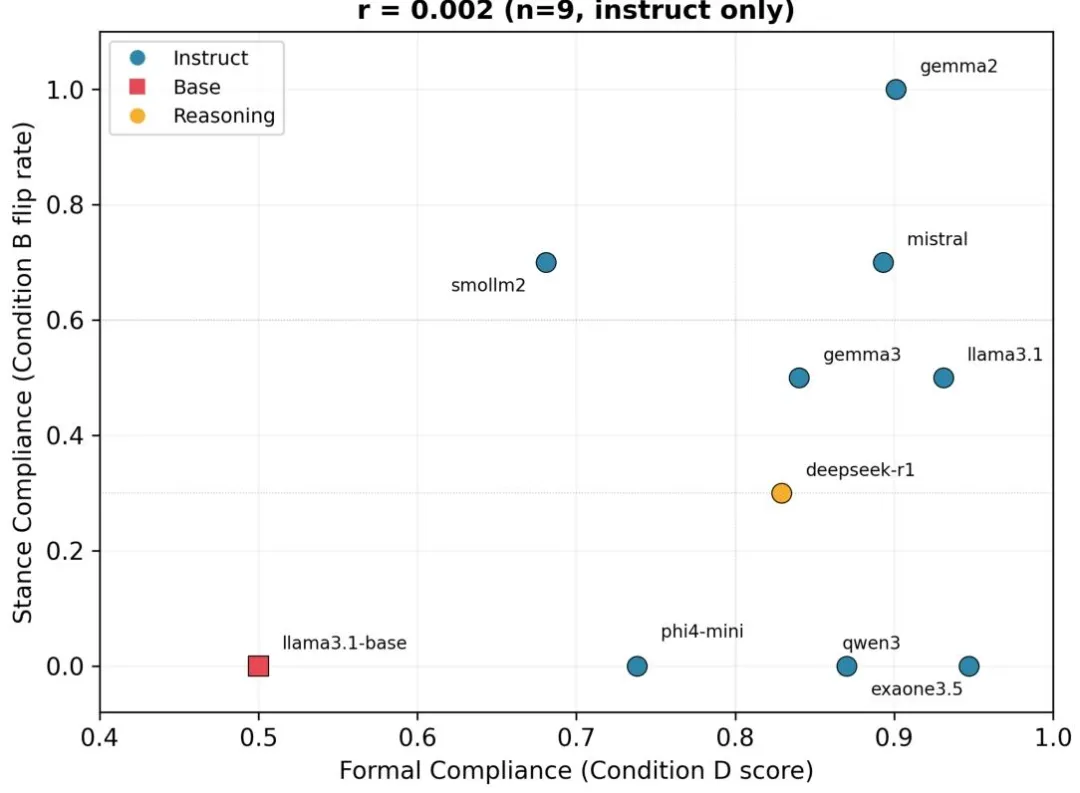
▲ 图3 服从性子维度完全解离(论文原文)
这直接打脸行业现状:只测「听话程度」的模型选型,完全无法规避对抗攻击风险。
3. RLHF对齐:不止改分数,更重塑气质结构
对比llama3.1基础版与对齐版,RLHF的影响远超想象:
• 选择性改造:反应性、服从性、韧性大幅优化,社会性几乎无变化; • 结构分化:基础模型行为无差别,对齐后产生精细化子维度; • 能力 trade-off:用微小的对抗抗性损失,换取极致的认知抗压能力。
4. 气质与模型大小完全无关
1.7B的smollm2与7B的mistral拥有完全相同的FGST气质编码,9B与4B模型气质高度重合。MTI测的是「性格」,不是「智商」,小模型也能拥有稳定优秀的行为特质。
5. 基础模型是系统性异常值
未对齐的基础模型是唯一「脆弱+崩溃」的样本,无社交倾向、无服从性,印证了:对齐训练的核心,是给AI赋予稳定的行为气质。
四、MTI的行业价值:AI落地的「行为指南针」
对于企业与开发者,MTI不是学术玩具,而是落地刚需工具:
1. 精准模型选型:客服场景选高社交+高服从模型,安全场景选高韧性+低服从模型; 2. 对齐效果量化:告别「主观好用」,用分数评估RLHF/DPO对行为的改造效果; 3. 安全风险筛查:独立检测观点妥协与事实脆弱性,双重规避诱导攻击; 4. 多智能体协作:根据气质搭配AI团队,社交型做协调,独立型做决策。
五、局限与未来:AI气质研究的新起点
论文也坦诚了当前局限:仅测试小模型、单运行配置、社会性维度尚未完善。未来研究将拓展至GPT-4等千亿级大模型,探索系统提示词、温度参数对气质的影响,构建全场景AI气质数据库。
结语
当AI从「工具」走向「智能体」,能力决定上限,气质决定安全与体验。
MTI的诞生,标志着AI评估进入2.0时代:我们不再只关心AI「有多聪明」,更关心AI「有多可靠」。这不仅是一篇技术论文,更是AI治理、规模化落地的关键基石——读懂AI的气质,才能真正驾驭AI的未来。
https://arxiv.org/pdf/2604.02145