 夜雨聆风
夜雨聆风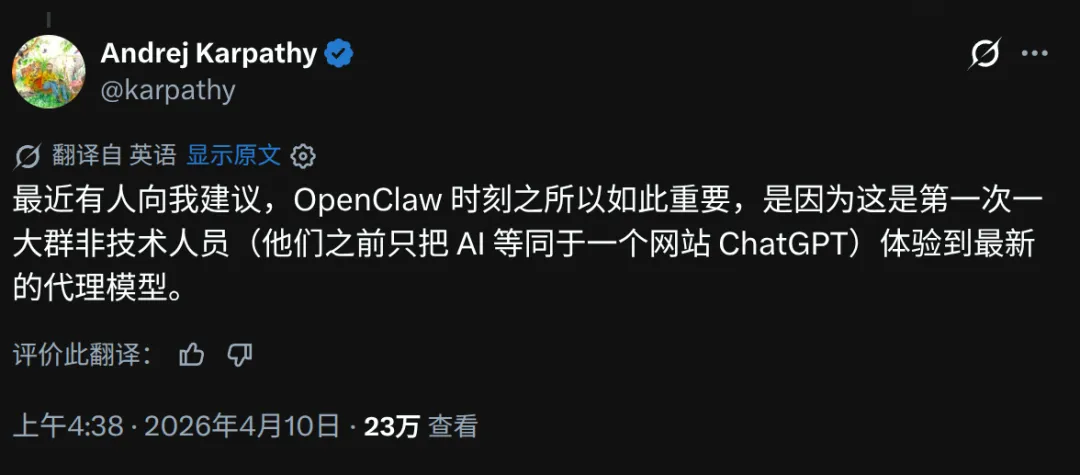
这轮 AI 争论里,最容易误导人的地方,不是观点太多,而是很多人拿错了样本,还以为自己看见了全貌。
如果你最近还在用免费聊天框测试 AI,大概率会得到一个并不离谱、但已经严重过时的结论:它偶尔聪明,偶尔胡说,能帮你润色改写、查资料、做摘要,但距离真正稳定地承担工作,似乎还差得很远。这个印象并不是假的。问题在于,它越来越像一个流量入口,而不是能力上限。
真正值得警觉的变化,已经不在“它回答得像不像人”,而在“它能不能把一段工作接过去,并且闭环做完”。Andrej Karpathy 点破的正是这个认知断层。大众还在围观聊天机器人答错了什么,前沿模型已经在编程、研究、数学和自动化流程里,开始接任务、拆步骤、调工具、跑验证、再根据反馈迭代。你如果只盯着聊天层,就会低估这一轮 AI 对效率结构的冲击。
很多人今天说“AI 没那么神”,说的其实是一个被压缩过成本、被限制过权限、被简化过边界的产品层。另一批人说“AI 已经能改写专业工作流”,说的则是更贵、更强、更接近真实生产环境的 agentic 层。两边都没有完全说错,但看见的不是同一种东西。问题不在谁乐观谁悲观,而在谁真正进入了新的工具层。
如果把当下的大模型产品看成一座城市,免费聊天入口更像临街商场,谁都能进,热闹、显眼、体验也足够顺滑;而真正改变生产率的地方,已经转移到了楼上的办公系统里。你要在那里看它如何接入文件、终端、代码库、文档、测试环境和反馈循环,才能理解为什么有些人会突然觉得,自己过去熟悉的工作节奏正在被重新定义。
这也是为什么过去一年,最陡峭的进步并没有先体现在“更会聊天”上,而是先体现在“更会做事”上。
对效率最敏感的人,其实最早能感到这件事。因为效率不是一个抽象口号,效率是任务是否真的往前推进,是原来要半天的事情现在能不能缩到一小时,是原来需要来回切换五六个工具、反复复制粘贴、手动校对、人工补洞的流程,今天能不能压缩成一个连续动作。聊天机器人再聪明,如果只能停留在建议层,它对工作流的改变依然有限;可一旦模型开始具备“行动能力”,价值密度就完全不同了。
所谓行动能力,不是多生成几段漂亮文字,而是它开始接收目标,然后持续往结果走。它会读上下文,理解约束,拆分任务,调用环境,产出中间结果,接受反馈,再继续修正。过去大家讨论的是“回答质量”,现在真正的竞争点正在转向“任务闭环能力”。这一步一旦成立,工具的身份就变了。它不再只是助手,而更像一个可调度、可验证、可复用的执行单元。
为什么这类能力会先在技术场景里爆发?Karpathy 其实给出了很清楚的解释。
第一,是因为技术任务更容易被验证。代码能不能运行,测试能不能通过,漏洞有没有复现,数学推导是不是一致,这些都能形成比较明确的反馈信号。一旦反馈足够明确,模型就更容易被训练到有效方向上。相比之下,很多通用写作、闲聊、泛咨询任务虽然也能做,但什么叫“更好”往往很主观,很难像测试通过那样给出硬反馈,所以进步感就没有那么剧烈。
第二,是因为这类任务离商业价值更近。企业愿意为能直接节省研发时间、缩短交付周期、降低人力成本的系统付更高价格,也愿意把最强的模型、更深的权限和更多的组织资源放到这些场景里。于是最贵的能力、最强的优化、最密集的产品迭代,自然优先流向高价值的 B2B 生产系统,而不是平均分配给所有免费入口。
这会带来一个很现实的后果:大众对 AI 的直观印象,越来越不能代表 AI 的前沿能力。
很多人还在用“它连这个都答错”来判断整轮技术浪潮,但真正决定产业节奏的地方,已经转移到了另一个平面。那里的问题不是“像不像一个聪明聊天机器人”,而是“能不能稳定地接入流程、执行动作、产出结果、承受验证”。当工具开始下场干活,讨论方式就必须跟着升级。你不能再只问它会不会说,而要问它会不会做、能做多深、做到哪一步还可靠。
这也是过去一年为什么越来越多一线用户反复提到 Codex、Claude Code 这类 agentic 工具。它们最关键的变化,不是比旧聊天框更会表达,而是能更自然地接收目标、理解工程上下文、执行多轮任务,并把结果带回给你。对真正拿工具干活的人来说,这种差别不是“小优化”,而是工作方式的分水岭。
一旦你从这个角度看问题,就会发现这轮效率革命最先重写的,往往不是创造性的顶层判断,而是大量中间层动作。
过去一份完整任务里,真正耗时间的往往不是最后那个结论,而是前面长长一串机械但必须做的步骤:搜集资料、整理上下文、写初稿、比对版本、查错漏、补格式、跑回归、重构旧结构、生成脚本、转译文档、复核结果。每一步单看都不算高难,但串起来就是大量时间和注意力的消耗。agentic 模型最先接管的,恰恰就是这些可拆解、可验证、可多轮迭代的中间层。
这件事对效率工具的意义非常大。因为它意味着未来真正有价值的,不再只是一个“单点能力很强”的功能,而是一个能接进闭环的系统。单点功能当然还有市场,比如写摘要、做翻译、改文案、提取结构;但真正会把产能拉开差距的,是谁能把这些能力串成一条可执行的工作流,让任务从输入一路走到验收。
换句话说,接下来大家比的不是谁多了一个 AI 按钮,而是谁先把 AI 放进了流程骨架里。
这也是很多人容易忽略的地方。工具升级从来不只是界面升级,真正的效率提升也从来不只是“更快生成点什么”。真正的跃迁发生在流程被重写的时候。你开始不再自己执行每一个中间动作,而是把目标、约束、验收条件和关键边界交给系统,让系统去跑第一轮、第二轮、第三轮,然后你把时间用在判断优先级、修正方向和做最终拍板上。
这会直接改变个人的产能上限。
原来一个人一天能推进的任务数量,是被大量碎片化步骤锁死的。你明明知道哪些事情值得做,但总被“太花时间”卡住:文档要补、旧代码要清、流程要重构、自动化要接、测试要跑、研究材料要先铺底。现在一旦 agent 能把这些中间层动作压缩掉,很多原本只能排进“以后再说”的事情,会第一次进入可执行区间。
这里最关键的变化,不是省几分钟,而是让以前根本做不起的事情开始做得起。一个人可以同时推进更多实验,一个小团队可以在不扩编的情况下承接更复杂的项目,一些长期被拖延的流程优化终于有了落地条件。对真正关心效率的人来说,这不是体验升级,而是杠杆升级。
当然,这里也有一个必须说清楚的误区:前沿 agentic 模型变强,不等于所有场景都同样成熟,更不等于随便接上去就能稳定出结果。
Karpathy 的观察恰恰提醒我们,提升是分布不均的。它在技术型、可验证、高价值任务里最陡,在泛化问答和开放式表达里则往往表现为渐进式改善。这意味着你的方法也必须跟着变。不要再拿一个弱反馈、低权限、浅上下文的使用方式,去判断一个强反馈、高权限、深上下文系统的潜力。观察样本错了,结论就一定错。

对个人来说,最危险的不是不会用 AI,而是一直用聊天层样本来推断 agent 层趋势。你看到的是它偶尔失误,别人看到的是它已经能稳定吃下一段流程;你拿免费入口判断生产工具,别人拿闭环执行判断未来分工。久而久之,差距就不再是工具偏好,而会变成行动速度、试错频率和结果积累的差距。
对团队来说,最值得重新审视的也不是“要不要接入 AI”这种口号,而是哪些流程已经适合被重新设计。凡是任务目标清晰、上下文能组织、验收标准可描述、结果能验证的地方,都值得重做一遍。代码重构、测试回归、文档整理、研究辅助、安全排查、运维脚本生成,这些都不是遥远的未来,而是已经能够反复试验的现实战场。
真正的门槛,也不再只是会不会写提示词,而是能不能把任务讲清楚、把边界讲清楚、把验证机制搭清楚。因为当模型开始执行,人的核心价值会从“亲自完成每一步”转向“定义目标、组织上下文、校验结果、承担责任”。这并没有让人退出系统,反而抬高了对任务设计能力的要求。
所以今天最值得更新的,不是对 AI 的情绪,而是对效率的理解。
过去很多人把效率工具理解为加速器,默认它只是把原有动作做快一点。现在更准确的理解应该是:前沿 AI 正在变成一种新的流程基础设施。它先在少数高价值、强反馈场景里长出牙齿,然后再逐步向外扩散。等到更多人意识到这不是“聊天更聪明”而是“系统能行动”时,很多先行者已经把工作流重写了一轮。
这也是为什么所谓的认知断层,不只是舆论层面的分歧,而是一种真实的机会分层。有人还把 AI 当成一个偶尔有用的对话窗口,有人已经把它当成可接入流程的半自动执行层。前者看到的是玩具属性,后者看到的是生产属性。前者在比较回答质量,后者在衡量闭环能力。它们不是同一种竞争。
如果一定要把今天这件事压缩成一句话,那就是:AI 的分水岭,已经不是它会不会回答,而是它能不能持续行动。
免费层、旧模型和轻量聊天入口,仍然会长期存在,因为那是大众接触 AI 的入口,也是产品做普及的必要层。但真正值得紧盯的变化,已经发生在更深的地方。谁能让模型在真实环境里理解目标、接入工具、执行流程、验证结果并持续修正,谁就更可能定义下一阶段的效率标准。
所以真正该问的问题,不是“AI 到底有没有那么厉害”,而是“你今天观察的 AI,停留在哪一层”。
如果你看的还是聊天层,你看到的会是一个时灵时不灵的助手。
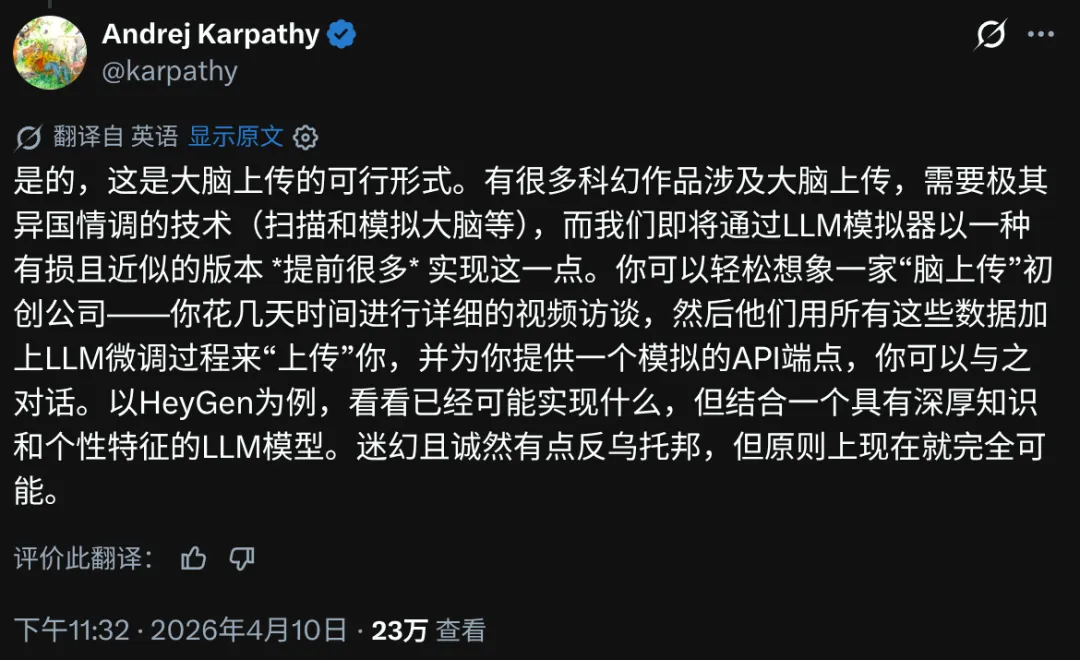
如果你已经进入 agent 层,你看到的会是一整套正在重新定价时间、重写分工、压缩中间成本的生产系统。
而这两者之间的距离,正在迅速变成新的效率鸿沟。
ChatGPT Plus订阅优惠使用方法,参考: 2026 保姆级教程:国内如何注册并升级 ChatGPT Plus(全流程图解)
