夜雨聆风
夜雨聆风🧠一、记忆黑科技:从失忆小白到超强“最强大脑”
AI 时代!人人都在深耕 AI 安全,你缺的就是这关键一步!🚀
AI 正重塑安全边界,与其在门外徘徊,不如直接掌握主动权!

千万别以为给大模型塞一个超长的 Prompt(提示词),它就能永远记住你的要求!随着聊天轮次变多,AI 会像金鱼一样“只有七秒记忆”,甚至开始胡言乱语。在这次泄露的 Claude Code 源码中,最先惊艳技术圈的就是它一套堪称“黑科技”的记忆管理模式。这套模式直接决定了 AI 到底是越用越懂你,还是越用越智障。这五个模式是一个层层递进的完美闭环,彻底粉碎了 AI 的失忆魔咒!
📌 1. 持久化指令文件(Persistent Instruction File)
大家是不是经常遇到这种崩溃场景:每次新建一个对话,都要重新告诉 AI“我是用 Python 3.10 开发的”、“我的变量命名要用严格的小驼峰格式”、“测试代码统统放在 tests 文件夹下”。如果你不教,它在第五次独立对话里依然会犯第一次一模一样的蠢错!大模型的上下文隔离特性,导致它每次都在“重新做人”。

这个模式的精髓在于:绝对不要把规则塞在你的剪贴板里,把它像写代码一样固化在项目代码库里! Claude 引入了一个持久化的项目级配置文件,每次新会话开始时,系统会自动去底层读取它。这个文件里写死了项目的构建命令、测试跑法、架构红线等一切不可越界的规矩。
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
📌 2. 作用域上下文组装(Scoped Context Assembly)
刚才说的“一本员工手册走天下”只适合单体架构的小团队。但如果你的代码库是个极其庞大的巨无霸项目,或者是个既有前端(Vue/React)又有后端(Java/Go),甚至还有底层 C++ 的混合架构呢?一个通用的规则文件根本不够用,甚至会产生极其严重的规则冲突。

这个模式用了一招非常聪明的“动态加载”与“按需挂载”:把指令文件拆散到不同层级(比如组织级、用户级、项目根目录、父子目录)。AI 逛到哪个文件夹,就自动加载哪个文件夹专属的规矩! 配合类似编程语言中 Import 的引用语法,把巨大的规则文件切成无数个精准的小块。
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
📌 3. 分层记忆(Tiered Memory)
如果一个 AI 把所有看过的内容、改过的 Bug、查过的文档都死记硬背下来,最后它的脑子绝对会变成一团乱麻。这不仅极其浪费 API 的 Token 算力(也就是疯狂烧钱),还会因为上下文太长导致核心关键信息被彻底淹没,引发大模型界极其著名的“Lost in the Middle”(中间注意力迷失)现象。

Claude 泄露代码证实了极其精妙且等级森严的**“三层记忆设计”**,堪比计算机底层的 CPU 缓存架构:
1. 常驻核心(L1 Cache):一个极其克制、绝对不超过 200 行的超浓缩核心索引,永远驻留在上下文里,绝不踢出。 2. 按需加载(L2 Cache):当 AI 处理特定模块任务时,才把相关的具体文件和历史设定调入内存。 3. 冷备归档(L3 Storage):完整的长篇对话历史直接作为静态文件保存在电脑硬盘上,只有在 AI 觉得必须翻旧账时,才会通过向量搜索去获取。
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
📌 4. 梦境整合(Dream Consolidation)
这就是传说中最让人惊艳的“AI 垃圾回收”机制!哪怕有了分层记忆,时间一长,AI 的脑子里依然会堆满重复的废话,过时的旧事实还会和新情况互相打架,导致逻辑链条断裂。

最让技术圈震惊的是,泄露代码里居然藏着一个名叫 autoDream(自动做梦)的高级模式!它利用 AI 空闲的时间(通过后台静默进程),偷偷给自己进行“做梦洗脑”:审查海量记忆、清理重复冗余项、删掉互相打架的矛盾点、重新压缩越来越臃肿的记忆索引。 另一位逆向工程大神甚至扒出了它底层包含整整 8 个严密的记忆管理阶段和过滤网!
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
📌 5. 渐进式上下文压缩(Progressive Context Compaction)
大家一定有过这种极其抓狂的体验:和 AI 聊了 50 轮之后,它突然弹出一个血红的报错“超过最大上下文窗口限制”,然后当场死机罢工!如果你为了省事,直接用代码截断最早的聊天记录,AI 又会瞬间变得断片,连一开始的目标都忘了。

Claude 采用的是极其残暴但效果极佳的四层渐进式压缩策略,像榨汁机一样把上下文压干:
1. 近期轮次:原汁原味,连一个标点符号和一个空格都不放过。 2. 较旧轮次(HISTORY_SNIP):启动轻度提炼,丢弃寒暄废话,提取关键动作。 3. 老旧轮次(Microcompact):严重缩水,只保留核心实体和最终结果的大意。 4. 远古轮次(CONTEXT_COLLAPSE / Autocompact):极其激进的疯狂折叠,直接把一万字的长篇大论降维打击成几个干瘪的关键词标签。
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
🚀二、工作流大爆发:打破单线程魔咒的“协同术”
这一章的主题只有一个字:拆! 很多半吊子开源 AI 框架最大的通病,就是让同一个通用大模型把“读代码、写代码、查文档、跑测试、修复报错”全搅和在同一个对话框里干,这叫灾难级大乱炖,产出的代码质量绝对稀烂。优秀的智能体架构必须在工作流上实现物理级别的隔离和多线程并行。
📌 6. 探索-计划-行动循环(Explore-Plan-Act Loop)
无数老程序员都被 AI 坑过:给 AI 发个新功能需求,它连项目长啥样、到底用了什么框架都没看清,直接上去就是一顿猛如虎的修改!结果自然是把代码改得稀巴烂,漏掉了无数隐蔽的底层依赖项。
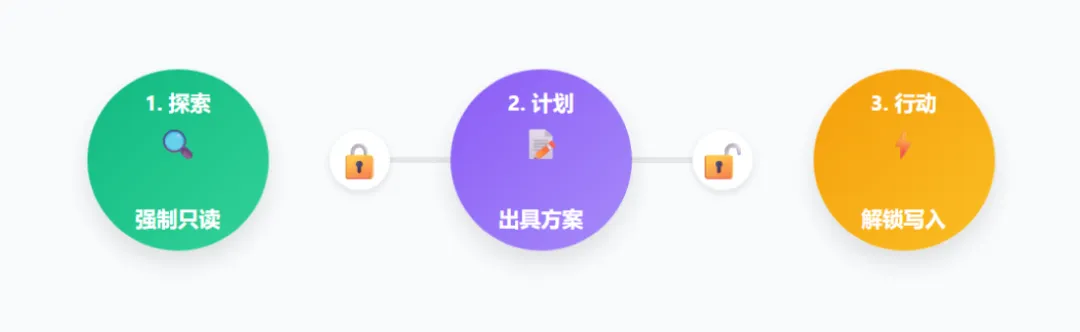
这个模式用强硬的手段规定了权限严格递增的“三步走”铁律:
• 探索阶段(Explore):AI 的手脚被死死捆住,只能看!只准执行读取文件、全局搜索字符、绘制文件目录树,绝不允许碰任何写入操作! • 计划阶段(Plan):AI 必须先写出一份详尽的修改方案,跟用户对齐思路。 • 行动阶段(Act):只有当你点头确认了方案,它才会被系统解锁“写入和修改代码”的危险工具权限。
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
📌 7. 上下文隔离的子智能体(Context-Isolated Subagents)
如果让同一个 AI 实体从头干到尾,它的短期对话框里会塞满前期的研究废稿、无数次疯狂报错的日志、乱七八糟的测试结果… 等它真正开始静下心来写核心业务代码时,它的注意力机制(Attention)已经被早期的垃圾信息彻底污染了,导致写出来的代码频频犯蠢,甚至把报错日志写进代码里。
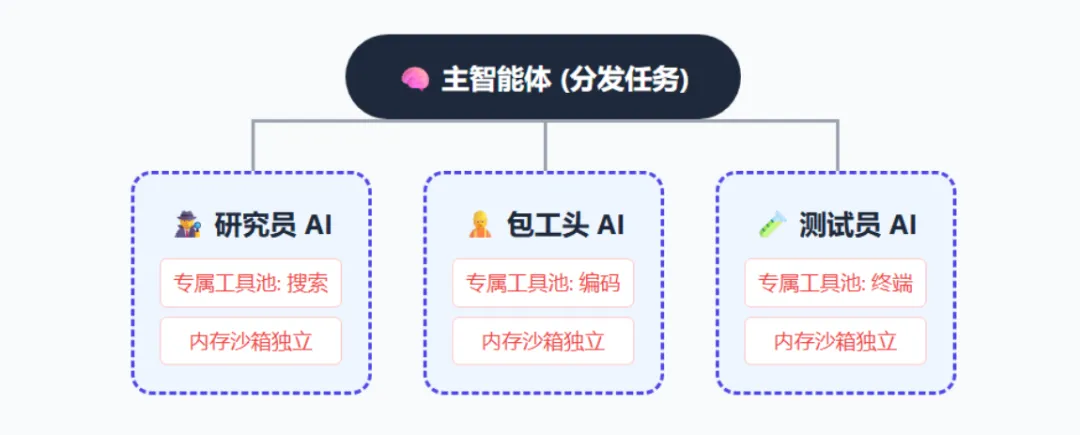
这个模式简直是神来之笔:直接召唤“影分身”!系统会在后台静默运行多个完全独立、互不干扰的子智能体。每个子智能体都有专属的系统提示词(System Prompt)、独立的内存沙箱和截然不同的工具池。比如,“研究员 AI”哪怕把天说破也拿不到修改代码的权限;“包工头 AI”绝对跑不了删除文件的终端命令。大家各司其职,互不污染。
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
📌 8. 分叉-合并并行(Fork-Join Parallelism)
当前所有大模型最蠢的一点就是它只能“单 গঠন串行吐字”。如果任务是把 20 个毫无关联的旧版配置文件升级到新版,它必须像老黄牛一样一个一个排队改。这在讲究绝对效率的工程世界里是绝对不可忍受的。
Claude 的底层架构毫不客气地使用了高级并发机制:同时克隆出多个子智能体,在独立的 Git Worktree(工作树)里同时开工! 最牛的是,父智能体之前耗费巨资攒下的上下文缓存状态,这 20 个克隆子智能体可以直接免费共享复用,让原本极其昂贵的 Token 成本瞬间约等于零!所有分身干完之后,再统一执行合并提交。
| 💡 秒懂解析 | |
| ✅ 绝佳场景 | |
| ⚠️ 致命死穴 |
🔥三、核心起底!直击大模型工具与权限的“致命死穴”
🎯 【Agent 安全防护】
当大模型被赋予了操作系统的底层工具权限,它究竟是如虎添翼的效率利器,还是随时可能“删库跑路”的定时炸弹?如何通过渐进式的权限收缩与暴力的红绿灯风控系统,把极易发疯的 AI 死死锁进安全沙箱中?
想要洞察大模型工具调用与权限风控的核心破解之法?👉 立即加入 Oxo AI Security 知识星球,解锁本章节完整的源码级深度解析!星球内部为你准备了海量独家干货
• 📚 AI 文献解读:最前沿的 LLM 安全论文深度剖析。 • 🐛 AI 漏洞情报:第一时间掌握主流大模型的 0-day 漏洞与越狱方式。 • 🛡 AI 安全体系:从红队攻击到蓝队防御的全方位知识图谱。 • 🛠 AI 攻防工具:红队专属的自动化测试与扫描工具箱。
🚀 立即加入 Oxo AI Security 知识星球,掌握AI安全攻防核心能力!