 夜雨聆风
夜雨聆风工具系统:AI是怎么"决定做什么"的
文 | 30天进阶第24天
Day23我们拆解了记忆系统——CLAUDE.md和memory如何让AI"记住"你的偏好和项目背景。但光"记住"不够,AI还要做事。
你说"帮我修一下这个Bug",AI要读文件、搜代码、改文件、跑测试。这些动作不是AI"自己"完成的——它只能生成文字。每一个和真实世界的交互,都是通过"工具"实现的。
今天我们深潜工具系统:AI怎么决定该调用哪个工具?SKILL怎么被发现和触发?MCP工具怎么扩展AI的能力边界?以及——怎么让AI的工具选择更精准?
一、工具的本质——AI的"手和脚"
Day21我们建立了一个核心认知:模型只能生成文字。 它不能读文件、不能执行命令、不能搜索代码。所有和外部世界的交互,都依赖工具。
但这里有一个很多人忽略的关键区分:AI不是"使用"工具,而是"请求"工具执行。
一个常见误解: "AI读了这个文件" → 让人以为AI直接操作了文件系统实际发生的事: 第1步:模型生成一段结构化输出 → {"tool": "Read", "path": "src/Login.tsx"} 第2步:Claude Code收到这段输出 → 解析出这是一个Read工具调用请求 第3步:Claude Code在你的机器上执行读取操作 → 实际读取文件内容 第4步:文件内容作为"工具结果"返回给模型 → 模型继续推理全程中,模型没有直接接触你的文件系统它只是"请求"了一次操作,Claude Code代理执行理解了这个机制,就能明白三个关键事实:
工具描述决定AI的选择。 AI是根据每个工具的文字描述来决定调哪个工具的。描述写得差,AI就会选错工具。
工具执行有权限控制。 Claude Code可以在执行前拦截请求——这就是Day25要讲的安全机制。AI"想"调工具不一定能调成。
工具结果消耗上下文。 每次工具调用的结果都会追加到上下文中。读一个500行的文件,就是500行的上下文开销。
所以,AI选择调用哪个工具,本身就是一次推理行为。这个选择的质量,取决于每个工具的描述有多清晰。写好工具描述,就是在帮AI做出更好的决策。
二、原生工具全景:每个工具的"性格"
Claude Code内置了一组原生工具,每个工具有自己擅长的场景和"性格"。理解这些性格,能帮你预测AI的行为——也能帮你在写SKILL时更好地引导AI。
文件操作三件套
Read——好奇心强的观察者。 它的工作就是"看"。支持读文件、读图片、读PDF、读Jupyter Notebook,还支持按行号范围读取(避免一次性读大文件浪费上下文)。
Edit——精准的外科医生。 它通过"字符串替换"的方式修改文件——找到旧字符串,替换成新字符串。不是重写整个文件,是精确修改。这意味着Edit操作很安全,只改你指定的部分。
Write——全新开始的建筑师。 它创建新文件或完全覆盖已有文件。注意:对已有文件,Claude Code的系统提示词明确告诉AI"优先用Edit而非Write"——因为Write会覆盖全部内容,风险更大。
搜索双子星
Grep——内容搜索专家。 基于ripgrep实现,搜索文件内容。支持正则表达式、文件类型过滤、上下文行数显示。
Glob——文件发现者。 按文件名模式查找文件。当你不知道某个文件在哪里时,Glob负责找到它。
这两个工具有个有趣的设计:Claude Code的系统提示词里明确写着"不要用Bash来执行grep或find命令,用Grep和Glob工具"。 为什么要这么强调?
为什么系统提示词禁止用Bash代替Grep/Glob:1. 权限控制 Grep和Glob工具有内置的权限和安全检查 Bash里执行grep/find绕过了这些检查2. 输出格式 Grep/Glob返回结构化结果,模型容易解析 Bash的grep输出是纯文本,模型要额外推理来理解3. 性能和稳定性 Grep/Glob针对大型代码库做了优化 Bash的find在大目录下可能卡住或输出过多4. 上下文效率 Grep/Glob可以控制返回条数(head_limit) Bash的grep一不小心就返回上千行,撑爆上下文万能钥匙
Bash——强大但危险的万能工具。 能执行任何Shell命令:跑测试、安装依赖、Git操作、调用CLI工具。但正因为什么都能做,它也是最容易出问题的——一个rm -rf就能让你很不开心。
扩展能力
Agent——分身术。 可以启动一个子Agent去执行独立任务。适合并行处理,比如"一边分析API层代码,一边分析数据库层代码"。
WebFetch/WebSearch——互联网入口。 WebFetch抓取指定URL的内容,WebSearch执行网络搜索。两者让AI能获取外部信息。
AI的工具选择决策树
当你给AI一个任务,它内部的决策逻辑大致如下:
| 你说的话 | AI的推理 | 选择的工具 |
|---|---|---|
工程实践中,把每个工具理解成一个有"性格"的角色会很有帮助——Read好奇、Edit精准、Bash万能但危险。理解这些性格,能帮你预测AI的行为模式,也能在CLAUDE.md里更精准地引导工具偏好。
三、SKILL的发现与触发机制
SKILL是你为Claude Code写的"自定义能力包"。但AI怎么知道什么时候该触发你的SKILL?
答案是:description匹配。
SKILL在系统提示词中的存在方式
Day21讲过,系统提示词里有一个"可用工具列表"。你的SKILL在这个列表里是怎样的?
SKILL在系统提示词中的形态:你安装了3个SKILL: - code-review - daily-report-generator - gold-priceAI在系统提示词中看到的(仅元数据): Available skills: - code-review: 执行基于项目规范的结构化代码审查... - daily-report-generator: 生成每个工作日的日报... - gold-price: 查询实时黄金价格...注意:AI只看到name和description SKILL.md的正文内容此时没有被加载 references/目录的文件更不会被加载这就是Day23讲的Progressive Disclosure在工具层面的体现——SKILL以最小的元数据存在于系统提示词中,只有被触发时才加载完整内容。
触发流程:从你的一句话到SKILL激活
当你说一句话,AI的决策流程是这样的:
用户输入:"帮我review一下这个PR的代码"AI内部推理过程: 1. 读取你的消息 2. 对照所有可用工具(原生工具 + SKILL + MCP) 3. 判断: - "review代码"匹配到了code-review SKILL的描述 - 描述里说"当用户提交代码审查请求时"——完全匹配 4. 决策:调用Skill工具,参数为"code-review"触发后发生什么: → Claude Code加载code-review/SKILL.md的完整内容(L2层) → SKILL.md中的指令和流程注入到当前上下文 → AI按照SKILL.md定义的规则执行代码审查 → 如果SKILL.md引用了references/文件,按需加载(L3层)三层加载的实际工作方式
| 层级 | 内容 | 加载时机 | 大小 |
|---|---|---|---|
为什么description是你写的最重要的200个字
description直接决定了SKILL能不能被正确触发。看两个对比:
模糊的description——触发不了,或者乱触发:
name: code-reviewdescription: 代码审查工具问题:- "代码审查"太笼统——用户说"看看这段代码写得对不对"会触发吗?- 没有明确的触发场景——什么情况下该用?什么情况下不该用?- 和原生工具重叠——AI可能直接用Read读文件而不是触发这个SKILL精确的description——该触发时触发,不该触发时不触发:
name: code-reviewdescription: > 当用户提交代码审查请求、要求review代码、 或讨论代码质量改进时,提供基于项目规范的 结构化代码审查,包含可读性、严谨性、扩展性三维评估优势:- 明确的触发条件:"代码审查请求""review代码""代码质量"- 说明了不同于Read的独特价值:"结构化""三维评估"- AI能清楚区分:用户是想"看看代码"(用Read) 还是想"审查代码质量"(用这个SKILL)/skill-name:显式触发的捷径
如果你不想依赖AI的匹配判断,可以直接用/code-review显式触发SKILL。这跳过了匹配过程,直接加载SKILL。
什么时候用显式触发?当你的SKILL名称短、意图明确、不想赌AI的匹配准确率时。比如/daily-report生成日报、/gold-price查金价——这些场景用显式触发更直接。
💡 关键洞察:SKILL发现本质上是一个匹配问题。你的description就是"搜索关键词",AI拿用户输入去匹配。像写SEO一样写description——触发词丰富、场景明确、和其他工具有清晰区分。
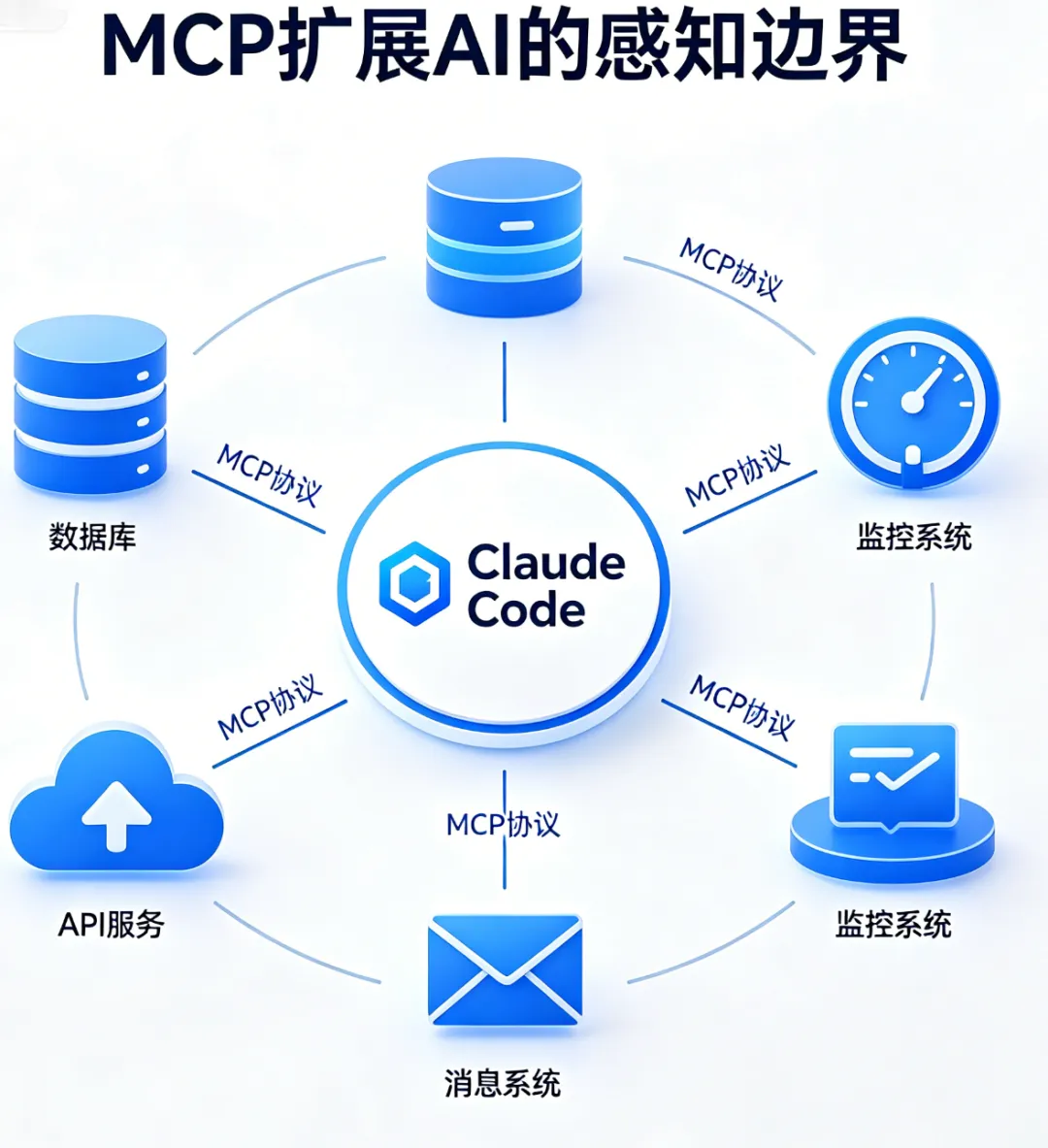
四、MCP工具:连接外部世界
原生工具让AI能操作本地文件和命令,SKILL让AI获得特定领域的知识和流程。但还有一大类事情它们做不了——访问外部系统。
查数据库、调内部API、读监控数据、发消息通知——这些需要MCP工具。
MCP工具是什么
MCP(Model Context Protocol)工具是通过MCP Server注册到Claude Code中的外部工具。你可以把MCP Server理解为一个"翻译官"——它把外部系统的能力翻译成Claude Code能理解的工具格式。
MCP工具的工作流程:你配置了一个数据库查询的MCP Server: → Claude Code启动时,连接MCP Server → MCP Server告诉Claude Code:"我提供了这些工具" - db-query: 执行SQL查询,参数{sql: string, database: string} - db-tables: 列出所有表,参数{database: string} → 这些工具被注册到系统提示词的工具列表中之后,AI使用MCP工具的方式和原生工具完全一样: 用户:"查一下orders表最近一周的数据" AI推理:需要查数据库 → 选择db-query工具 AI输出:{"tool": "db-query", "sql": "SELECT...", "database": "prod"} Claude Code:将请求转发给MCP Server MCP Server:执行查询,返回结果 Claude Code:将结果返回给AI AI:继续推理,告诉你查询结果MCP工具的注册方式
MCP工具通过配置文件注册。两种常见方式:
项目级配置(.mcp.json放在项目根目录,团队共享):
# .mcp.json 示例{ "mcpServers": { "db-tools": { "command": "node", "args": ["./mcp-servers/db-server.js"], "env": { "DB_HOST": "localhost" } } }}用户级配置(~/.claude/settings.json,个人使用):
# settings.json 中的MCP配置{ "mcpServers": { "monitoring": { "command": "python", "args": ["/path/to/monitoring-mcp-server.py"] } }}AI眼中的MCP工具
对AI来说,MCP工具和原生工具没有本质区别。它看到的都是:
| 要素 | 原生工具(如Grep) | MCP工具(如db-query) |
|---|---|---|
AI做工具选择时,对两者一视同仁——都是根据描述来判断该不该用。这意味着MCP工具的描述质量同样至关重要。
MCP工具的设计原则
写MCP工具时,三个原则能让AI用得更好:
原则一:描述要具体,不要泛泛。
差的描述: "查询数据" → AI不知道查什么数据、怎么查、返回什么格式好的描述: "在MySQL数据库中执行只读SQL查询, 返回JSON格式的查询结果。 适用于数据分析和问题排查, 不支持写操作(INSERT/UPDATE/DELETE)" → AI清楚知道能力边界和使用场景原则二:参数Schema要完整。 AI需要知道该传什么参数、什么类型、什么是必填的。参数定义不清楚,AI就会传错参数或漏传参数。
原则三:返回值要有意义。 AI拿到工具返回值后还要继续推理。如果返回的是一堆无结构的文本,AI理解起来就费劲。结构化的JSON返回值,AI处理效率高得多。
换个角度理解,MCP不只是"连接外部工具"——它在扩展AI的感知边界。每个MCP工具就是一种新的"感官",让AI能触达它原本接触不到的系统。实际用下来会发现,MCP工具描述的精准程度,直接决定了这个"感官"的灵敏度。
五、让AI做出更好的工具选择
理解了工具的运作机制后,来看一个实际问题:AI有时候会选错工具。
比如,你说"查一下这个接口的调用链路",AI可能用Grep去搜代码里的函数调用关系(能找到但不完整),而不是用你配置的trace-query MCP工具去查真实的调用链路。
选错工具的三个根因
根因一:描述模糊,AI无法区分。 当多个工具的描述都包含"查询"两个字,AI就很难判断该用哪个。就像招聘时收到50份"全栈工程师"的简历——头衔一样,你根本分不清谁擅长什么。
根因二:缺少上下文,AI不知道哪个更合适。 AI不知道你的项目里"查调用链路"这件事应该用什么工具,因为没有人告诉它。
根因三:工具数量太多,选择困难。 当可用工具从10个增加到50个,AI的选择准确率会下降。这不是模型的问题,是信息过载的问题——可选项太多时,任何决策者都会变差。
四个优化策略
策略一:写有区分度的描述。
不要只写工具"能做什么",更要写它"和其他工具有什么不同"。
改进前(三个工具描述看起来很像): grep-tool: 搜索代码内容 code-search-skill: 搜索代码 trace-query-mcp: 查询代码调用关系改进后(每个工具有清晰的定位): grep-tool: 在本地文件中按正则表达式搜索文本内容 code-search-skill: 基于语义理解搜索代码,支持"找到所有处理用户认证的逻辑"这类自然语言查询 trace-query-mcp: 查询线上真实的RPC调用链路和耗时数据,用于性能排查和故障定位策略二:用"反向触发"明确边界。
在描述中写明"这个工具不适用于什么场景":
trace-query-mcp的描述: "查询线上真实的RPC调用链路。 注意:如果用户只是想看代码中的函数调用关系, 请使用Grep搜索代码,不要使用本工具。 本工具用于查询生产环境的实际请求链路。"这就像在简历上写"我擅长后端微服务,不做前端页面切图"——让HR(AI)能快速排除不匹配的选项。
策略三:在CLAUDE.md中设置工具偏好。
CLAUDE.md是AI的"入职培训",你可以在里面明确写工具使用规则:
# CLAUDE.md中的工具偏好配置## 工具使用规则- 查询数据库:使用db-query MCP工具,不要用Bash执行mysql命令- 查看监控数据:使用monitoring MCP工具,不要尝试curl API- 搜索代码内容:优先用Grep工具,不要用Bash执行grep命令- 查询线上调用链路:使用trace-query MCP工具- 查看代码中的函数调用关系:使用Grep搜索代码这个策略非常有效——因为CLAUDE.md在每次对话的系统提示词中都会出现,AI每次做决策都能看到这些规则。
策略四:精简工具列表。
这是最反直觉但最有效的策略:减少可用工具数量。
工具数量 vs 选择准确率:5个工具 → AI几乎不会选错10个工具 → 偶尔混淆相似工具20个工具 → 需要在CLAUDE.md中引导50个工具 → 即使引导也经常选错实践建议:- 定期清理不再使用的MCP工具- 一个功能不要注册多个相似工具- 实验性工具用完就移除,不要长期挂着- 功能有重叠的工具,合并成一个怎么判断AI的工具选择质量
一个实用技巧:开启extended thinking(扩展思考)观察AI的决策过程。 在AI调用工具之前,它的思考过程会展示"我为什么选这个工具"。如果你发现AI的推理逻辑有偏差,说明工具描述或CLAUDE.md的引导需要优化。
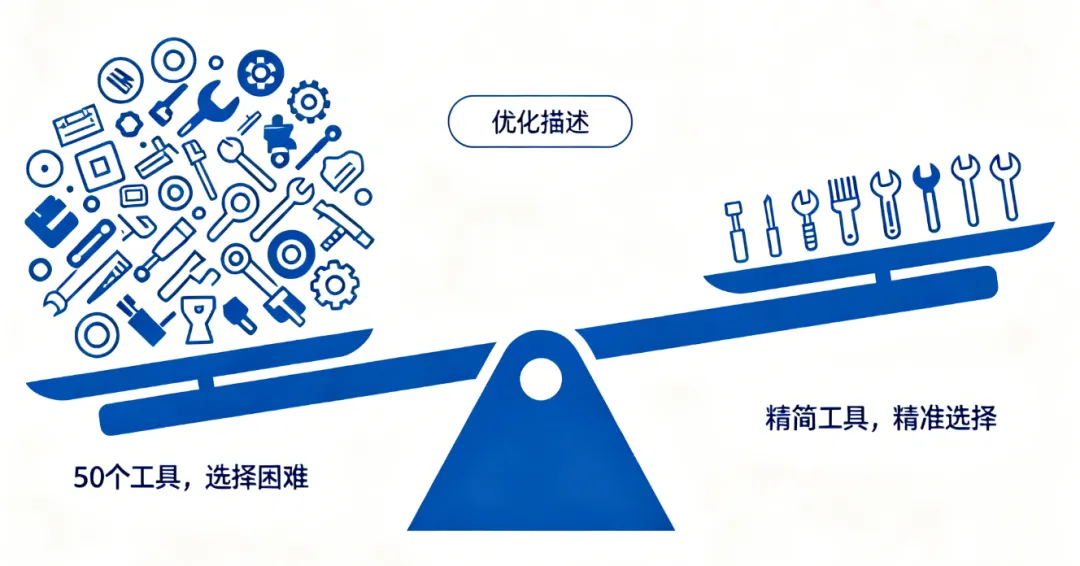
💡 关键洞察:工具选择就像招聘——当你有50个头衔相似的候选人时,岗位描述最清晰的那个会被选中。保持工具列表精简、描述锐利,是提升AI工作质量最直接的手段。
六、结语
今天的核心认知可以归结为一条:AI选择工具的质量,取决于工具描述的质量。 不管是原生工具、SKILL还是MCP工具,在AI眼里都是"名称+描述+参数"的组合——描述写得好,AI就用得准;工具列表精简,选择就更精确。
这里面有一个反直觉的结论:更少的工具往往带来更好的结果。与其给AI一百个工具,不如给它十个描述精准的。
不过,工具选得再准,还有一道关要过——AI想调用工具,Claude Code不一定让它执行。明天Day25聊安全与权限机制,这是让AI"放手做事"同时"保持可控"的关键一环。
