 夜雨聆风
夜雨聆风如果明天起,写代码变得和打字一样廉价,什么会变得昂贵?
这不是假设。Kent Beck 最近提出了"编程通缩"理论[1]:当开发成本趋近于零,代码会像互联网时代的内容一样泛滥——商品化代码淹没市场,而精心打造的软件反而愈加珍贵。他用出版业做类比:1995 年出版是稀缺资源,今天人人都能发布内容,但优质内容比任何时候都更值钱。
软件正在经历同样的转折:
• GitHub Copilot 拥有 2000 万用户[2] • Cursor 日活超过 100 万[3] • 85% 的开发者已经在使用 AI 工具(JetBrains 2025 调查[4]) • 41% 的代码由 AI 生成(JetBrains 2025 调查[4]) • Dario Amodei 预测这个数字很快会突破 90%
代码在通缩。但复杂度没有。

这就是第一性原理告诉我们的事情——也是这篇文章要回答的核心问题:当 AI 重塑了软件工程的"怎么做",我们需要重新理解"做的是什么"。
一、回到第一性原理:软件工程的本质是什么
Brooks 的遗产:40 年前的预言
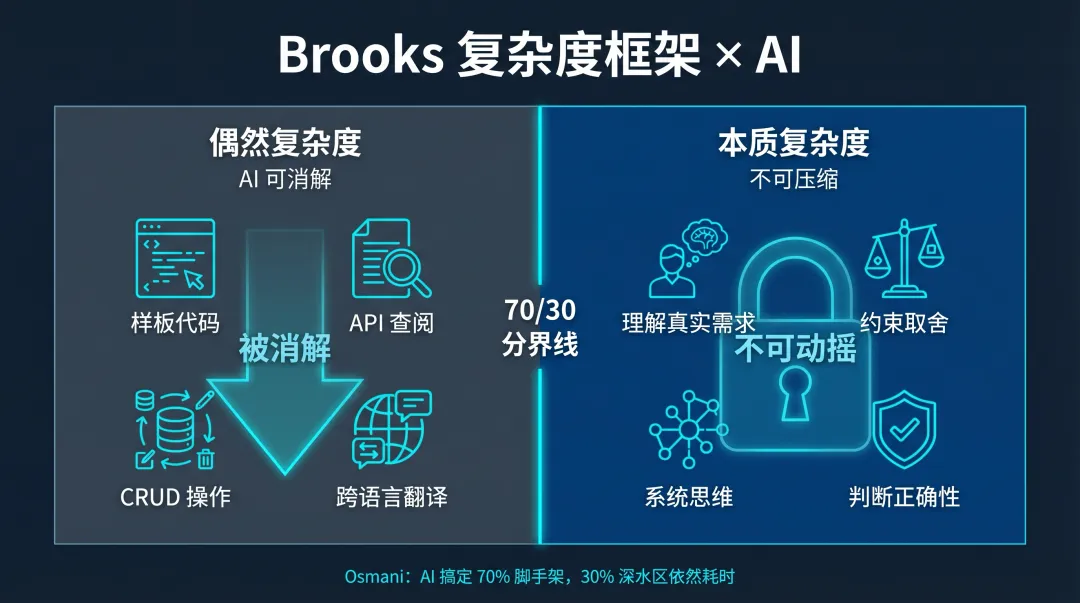
1986 年,Fred Brooks 发表了软件工程史上最有影响力的论文之一——《没有银弹》[5]。他将软件开发的困难分为两类:
• 本质复杂度(Essential Complexity):问题本身的固有难度——理解用户需要什么、建模业务领域、管理概念间的交互关系。这部分复杂度由问题决定,无法被任何工具消除。 • 偶然复杂度(Accidental Complexity):实现过程的附带产物——语法规则、样板代码、构建配置、API 查阅、跨平台适配。这部分复杂度由工具和方法带来,理论上可以被更好的工具消减。
Brooks 的结论是:由于本质复杂度占了软件困难的大部分,没有任何单一技术能在十年内将生产力提升 10 倍。
40 年过去了,这个框架依然是理解 AI 对软件工程影响的最佳透镜。
AI:偶然复杂度的最强消解器
AI 编程工具在偶然复杂度上的消解能力是前所未有的:
• 语法和样板代码:AI 可以瞬间生成任何语言的模板代码,开发者不再需要记忆 API 签名 • 文档查阅:与其翻文档,直接问 AI"这个库怎么用" • 重复性 CRUD:标准的数据库操作、表单验证、REST 端点,AI 生成的质量已经足够好 • 跨语言翻译:从 Python 到 Go、从 React 到 Vue,AI 让语言壁垒近乎消失
Addy Osmani 在 Google 观察到的"70% 问题"[6]精确地描述了这个边界:AI 可以快速产出大约 70% 的代码——脚手架、明显的模式、标准的实现。但剩余的 30%——边缘情况、调试、生产系统集成、安全——和以前一样耗时。
这个 70/30 的分界线,本质上就是 Brooks 的偶然/本质复杂度分界线在 2026 年的投影。
复杂度守恒:被转移而非被消除
这里有一个关键的认知陷阱:AI 消除偶然复杂度,不等于消除复杂度。
一个直接应用 Kolmogorov 复杂度理论的分析[7]指出:AI 工具可以降低表达的复杂度(用 10 页自然语言描述替代 2 万行代码),但无法突破系统描述所需的最小信息量。复杂度被转移了——从编写代码转移到了审查代码、从语法问题转移到了架构问题、从"写不出来"转移到了"分不清对错"。
DORA 2025 报告[8]提供了组织级的证据:采用 AI 工具后,开发者个人产出提升了 21%,PR 合并数量增加了 98%——但组织级的交付指标几乎持平。报告的结论令人警醒:
AI 是一面"哈哈镜",它放大你流水线中已有的好与坏。
Grady Booch 一语中的:
"Fear not, developers. Your tools are changing, but your problems are not."
实操:识别你工作中的本质/偶然复杂度
在你的日常工作中画一条线:
| 需求 | ||
| 设计 | ||
| 编码 | ||
| 维护 |
一个简单的检验标准:如果你能用一句话精确描述预期结果,它大概率是偶然复杂度;如果你需要反复讨论才能定义"正确"是什么意思,它就是本质复杂度。
二、数据真相:感知与现实的 43 个百分点
在讨论"如何应对"之前,我们需要先校准认知。因为关于 AI 编程工具的生产力数据,存在一个惊人的感知-现实鸿沟。
METR 研究:最令人不安的发现
2025 年,METR 组织了迄今最严格的 AI 编程生产力随机对照试验[9]。16 名经验丰富的开源开发者,在他们自己维护的成熟代码库上(平均 10 年历史、100 万行以上代码),分别在有和没有 AI 工具辅助的情况下完成 246 个真实任务。
结果:
• 使用 AI 工具的开发者比不使用的慢了 19% • 实验前,开发者预测 AI 会让他们快 24% • 实验后,开发者仍然相信自己快了 20%
开发者对 AI 效果的主观感受和客观测量之间,存在 43 个百分点的差距。 即使亲身经历了"变慢",他们依然相信自己"变快了"。

这不是个例。McKinsey 2026 年调研[10]也发现了类似的模式:AI 工具在常规编码任务上确实减少了 46% 的时间,但他们特别强调——仅仅提供 AI 工具"并不能真正推动指标",公司必须重新架构整个构建方式。
代码质量:可度量地恶化
CodeRabbit 对 470 个 GitHub PR 的分析[11]揭示了 AI 代码的质量代价:
| 1.7 倍 | |
| 1.75 倍 | |
| 3 倍 | |
| 2.74 倍 | |
| 1.88 倍 |
更令人担忧的是系统性数据[12]:AI 辅助开发者的提交速率是同行的 3-4 倍,但引入安全问题的速率是 10 倍。到 2025 年 6 月,AI 生成代码每月新增超过 10,000 个安全发现——比 2024 年 12 月增加了 10 倍。
Adam Tornhill 的研究进一步揭示了一个非线性效应:LLM 在不健康代码库中的缺陷风险上升 30%,在遗留系统中恶化速度更快。Rachel Laycock 在 ThoughtWorks 2026 年峰会上总结道:
"AI 只是你已有能力的加速器。"好的实践被加速,坏的实践也被加速。
实操:建立你团队的 AI 生产力基准线
不要盲目相信感觉,建立可度量的基准:
第一步:选择度量维度
• 不要只看"代码行数"或"PR 数量"(这些被 AI 通胀了) • 关注:需求到交付的端到端时间、生产环境缺陷率、代码审查返工率
第二步:做对照实验
• 在同类型任务上,对比 AI 辅助和非辅助的完成时间 • 重点关注成熟代码库上的复杂任务(不是绿地项目的脚手架搭建) • 追踪 AI 生成代码在后续 30 天内引发的 bug 和返工
第三步:计算真实 ROI
• 将 AI 工具订阅费、审查时间、额外的 bug 修复时间纳入成本 • 与纯粹的"编码时间节省"做对比 • 你会发现真实的 ROI 远比供应商宣传的保守——但仍然是正的
三、五个关键转变与实操指南

3.1 从"写代码"到"编排代码"
Andrej Karpathy 2025 年提出 vibe coding,一年后自己宣布它"过时了"[13]。关于 vibe coding 引发的开发者社区分裂,可以参考我之前的文章《Vibe Coding 的危与机:AI 编程正在撕裂开发者社区》。他的新框架是 agentic engineering:
"默认不再是你直接写代码,99% 的时间你在编排执行任务的 agent,充当监督者。"
Martin Fowler 在 ThoughtWorks 2026 年峰会[14]上提出了"监督工程的中间循环":在传统的内循环(写代码)和外循环(交付流水线)之间,出现了一个新的工作环节——指导 AI、评估输出、纠正偏差。
但讽刺的是,Karpathy 自己最新的项目是手写的。DHH 也经历了从强硬怀疑者到 agent-first 拥护者的戏剧性转变。这些案例说明:编排和手写不是二选一,而是一个根据场景动态调节的光谱。
实操:3 步转型编排工作流
1. 从"描述需求"开始,而非从"打开编辑器"开始。在写任何代码前,先用自然语言写清楚这段代码要做什么、边界条件是什么、与系统其他部分如何交互。这份"规格说明"既是给 AI 的输入,也是你自己思考的工具。关于规范驱动开发的深入实践,可以参考我之前的文章《AI 编程的下一站:规范驱动开发与 Spec Kit、OpenSpec 对比解析》。 2. 建立"分治-验证-集成"的节奏。将任务分解为 AI 可以独立完成的小块(每块不超过 200 行),逐块生成、逐块审查、逐块测试。不要让 AI 一次生成整个功能模块——那会超出你的审查能力。 3. 保留"手写"的肌肉。至少在核心业务逻辑、安全关键路径和架构决策点上亲自编写。就像飞行员必须保持手动操控能力一样,工程师需要保持"我能不依赖 AI 完成这件事"的能力。
3.2 从"信任默认"到"验证优先"
Kent Beck 在 AI 时代重新发现了 TDD 的价值[15]。他说 TDD 是与 AI 协作的"超能力"——先写测试约束 AI 的输出空间,再让 AI 在约束内生成实现,测试自动验证正确性。
这不是理论上的优雅。Beck 在用 AI 构建 B+ 树库时失败了三次,因为早期的尝试积累了过多复杂度,导致 AI"完全停滞"。成功的第四次,他全程用 TDD 保持代码简洁、复杂度可控。
Martin Fowler 的比喻更直白:
"对待 AI 生成的每一段代码,都要像审查一个很高产但你不能信任任何东西的不靠谱合作者的 PR。"
Stack Overflow 2025 调查[16]也印证了这一点:只有 29% 的开发者信任 AI 输出的准确性(比 2024 年的 40% 进一步下降)。59% 的开发者承认使用自己不完全理解的 AI 代码。这是事故的温床。
实操:AI 代码的验证清单
每次接受 AI 生成的代码前,过一遍这个清单:
• [ ] 我能用一句话解释这段代码的意图吗? 如果不能,不要合并 • [ ] 边界条件被覆盖了吗? AI 擅长 happy path,但经常忽略 null、空集合、并发、超时 • [ ] 有测试吗?测试是我写的还是 AI 写的? 如果 AI 同时生成了代码和测试,测试大概率是同义反复的——它测试的是"代码做了什么"而非"代码应该做什么" • [ ] 安全检查通过了吗? AI 代码的 XSS 漏洞率是人类的 2.74 倍,密钥泄露率翻倍 • [ ] 这段代码在六个月后还能被理解吗? AI 生成的代码可读性问题是人类的 3 倍
核心理念:先定义"正确"是什么,再让 AI 去实现它。 而不是先让 AI 写代码,再试图判断它对不对。
3.3 从 DRY 到"持久层 + 可再生层"
当重写代码的成本趋近于零,架构哲学也需要更新。
Google Cloud 的 Christina Lin 提出:当重构和重写变得廉价,软件从"静态纪念碑"变为"不断再生的有机体"。Denis Urayev 将其概括为从"可复用代码"到"可再生代码"的范式转换。
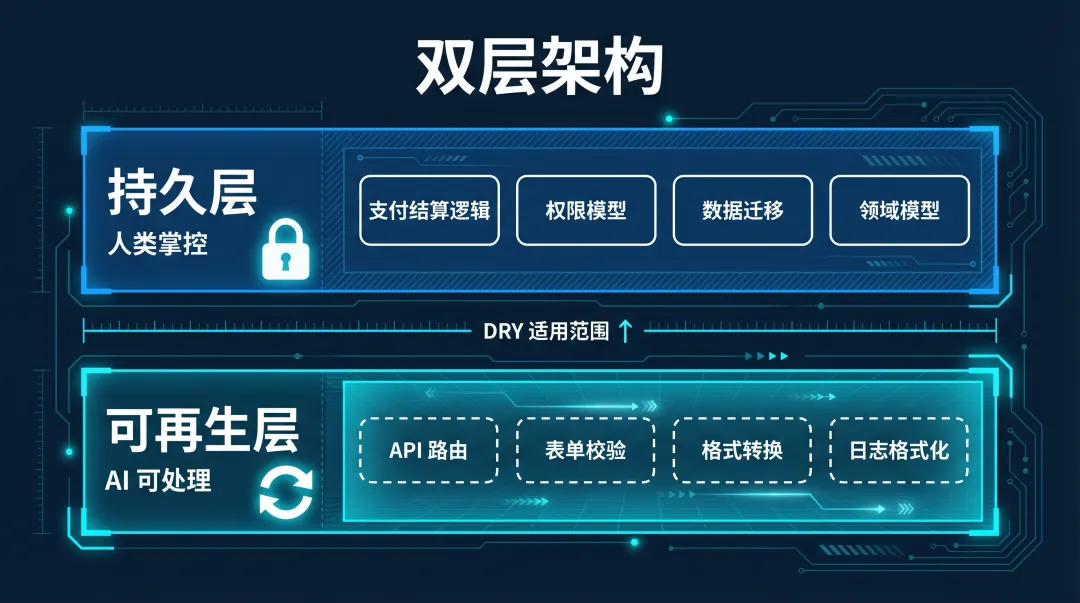
但这不意味着一切都可以随便重写。实际涌现的框架是一个双层架构:
• 持久层(人类掌控):核心业务逻辑、不可变的 API 契约、安全关键路径、数据模型。这些代表了组织知识的结晶,难以被重新生成。 • 可再生层(AI 可以处理):工具函数、适配器、UI 组件、样板代码、格式转换。这些可以按需重新生成,不需要为长期可维护性过度工程化。
DRY 原则并没有过时——在 AI 大量生成重复代码的时代,保持"每一条知识都有唯一权威来源"比以往更重要。但 DRY 的适用范围收缩到了持久层;在可再生层,可读性和可重新生成性比去重更重要。
实操:划分你代码库的持久/可再生边界
问三个问题:
1. 如果这段代码消失了,我能让 AI 在 10 分钟内重新生成一份功能等价的吗? 如果能,它属于可再生层。 2. 这段代码里有没有只存在于团队成员脑子里、不在任何文档中的业务知识? 如果有,它属于持久层。 3. 修改这段代码需要理解系统的多少上下文? 上下文越多,越属于持久层。
3.4 从"语言专家"到"领域专家"
Kent Beck 观察到一个技能价值的根本性转移:
AI 淘汰了曾经高杠杆的技能(语言专精、框架记忆),放大了愿景、策略、任务拆解和反馈循环的价值。
当 AI 可以流利地写任何语言的代码,"我是 Java 专家"或"我精通 React"不再是差异化优势。当 AI 可以秒查任何 API 文档,记忆力不再有溢价。
Addy Osmani 的"70% 问题"揭示了真正的瓶颈所在:AI 搞定了 70% 的脚手架和模式匹配,但剩余 30% 的边缘情况、生产集成和安全加固仍然是深水区。而这 30%,恰恰需要的不是语法知识,而是领域知识——理解支付系统的清算周期、医疗系统的合规要求、金融系统的风控逻辑。
Steve Yegge 的生产力曲线描绘了这个趋势的加速:代码补全带来小幅提升(2023),聊天编程带来约 5 倍提升(2024),Agent 编程再带来约 5 倍(2025)。每一次跃迁都让"写代码"的环节更不值钱,让"理解问题"的环节更值钱。
实操:技能投资组合调整
重新分配你的学习时间:
| 领域知识 | |
| 系统思维 | |
| 精确表达 | |
| 品味与判断 |
3.5 从"个人效率"到"系统效率"
DORA 2025 报告揭示了一个反直觉的事实:AI 让个体更快了,但组织没有更快。
为什么?因为个人效率的提升被其他环节吞噬了:更多的代码意味着更多的审查负担,更快的提交频率带来更多的合并冲突,AI 引入的 bug 增加了后续的修复成本。开发者每人产出的 PR 数量增加了 20%,但每个 PR 引发的事故也增加了 23.5%。
Klarna 是最典型的教训[17]。CEO 最初庆祝公司通过 AI 替代了约 40% 的员工,从 5000 人缩减到约 3000 人。但客户投诉上升、满意度下降、AI 无法处理需要同理心的复杂问题。不到 18 个月,CEO 公开承认"我们走得太远了",开始重新招聘人类员工。
Phodal 将这称为"10 倍悖论":AI 同时放大生产力和风险——"以前做得不好的,有了 AI 加速变得更糟"。
实操:团队级 AI 采纳框架
不要把 AI 工具采纳当成给个人买许可证的事。它需要系统级的规划:
1. 统一审查标准。AI 生成的代码和人类编写的代码,审查标准应该一样——甚至更严格。建立明确的 AI 代码审查指南,包括安全检查、测试覆盖率要求和可读性标准。 2. 投资工程基建。AI 在健康代码库上效果好、在遗留代码库上效果差。优先投资代码健康度(重构、测试覆盖率、文档),这是 AI 时代基础设施的"公路和桥梁"。 3. 保护初级人才管道。当前数据显示入门级招聘下降了 25%[18],70% 的招聘经理认为 AI 可以完成实习生工作。但 Addy Osmani 警告这是"缓慢衰变"——今天不培养初级开发者的公司,5-10 年后就没有高级开发者。刻意为初级工程师设计 AI 辅助下的学习路径,而非用 AI 替代他们的岗位。
四、不同角色的行动清单
初级工程师:在管道危机中生存
1. 打牢基本功,而非依赖 AI 跳过基本功。59% 的开发者在使用自己不理解的 AI 代码。你和他们的区别,就是你是否真的理解底层机制。花时间手写关键算法、理解框架源码、调试 AI 犯的错——这些"低效"的练习正是构建不可替代能力的过程。 2. 发展领域专长,而非追逐语言数量。当 AI 让任何人都能写任何语言的代码,"会写代码"不再是入场券。选一个行业深扎进去——理解业务逻辑、合规要求、用户痛点。领域知识是 AI 时代的护城河。 3. 学会与 AI 协作,但保持批判思维。使用 AI 工具提高效率,但对每段 AI 代码保持"我来证明它是错的"而非"我假设它是对的"的态度。这个习惯会让你在职业生涯中走得更远。
高级工程师:转型为编排者
1. 将你的经验编码为约束。你脑子里那些"这样做会出问题"的直觉,需要变成 AI 可以遵循的规则——测试用例、架构约束、代码审查检查项。Kent Beck 将 TDD 原则编码进了给 AI 的系统提示中,你也应该把你的工程判断编码成约束。关于如何通过 Skills、MCP、Rules、Agents 将工程规范系统化地传递给 AI,可以参考我之前的文章《AI 编程工具的四层能力体系》。 2. 掌握"监督工程"的中间循环。从"我来写代码"转变为"我来指导 AI 写代码、审查 AI 的输出、纠正 AI 的偏差"。这需要新的技能:更精确的需求表达、更快速的代码审查、更系统的验证方法。 3. 主动承担"教学"角色。在初级人才管道收缩的大背景下,Martin Fowler 特别强调高级工程师作为导师的价值。找到你的 AI 辅助下的教学方法——不是教他们怎么写代码,而是教他们怎么思考系统。
技术管理者:避免 DORA 陷阱
1. 度量端到端交付,而非编码速度。DORA 报告最大的教训:个人产出的提升不自动等于组织交付的提升。如果你的度量体系只看"代码产出量",你会得到更多代码、但不一定得到更多价值。关注需求到上线的完整周期、生产环境缺陷率、客户交付价值。 2. 投资工程基建,而非许可证堆叠。给每个开发者买 AI 工具许可证很简单。让你的代码库健康到 AI 能高效工作于其上,才是真正的投资。Adam Tornhill 的数据显示 LLM 在不健康代码库上的缺陷风险上升 30%——你的代码库是否准备好接受 AI 了? 3. 为 Klarna 时刻做准备。不要把 AI 当作裁员工具。Klarna 用血泪教训证明了这条路的终点。用 AI 提升团队的交付能力而非减少团队的人数——重新定义角色,而非消灭角色。
结语:软件工程的不变量
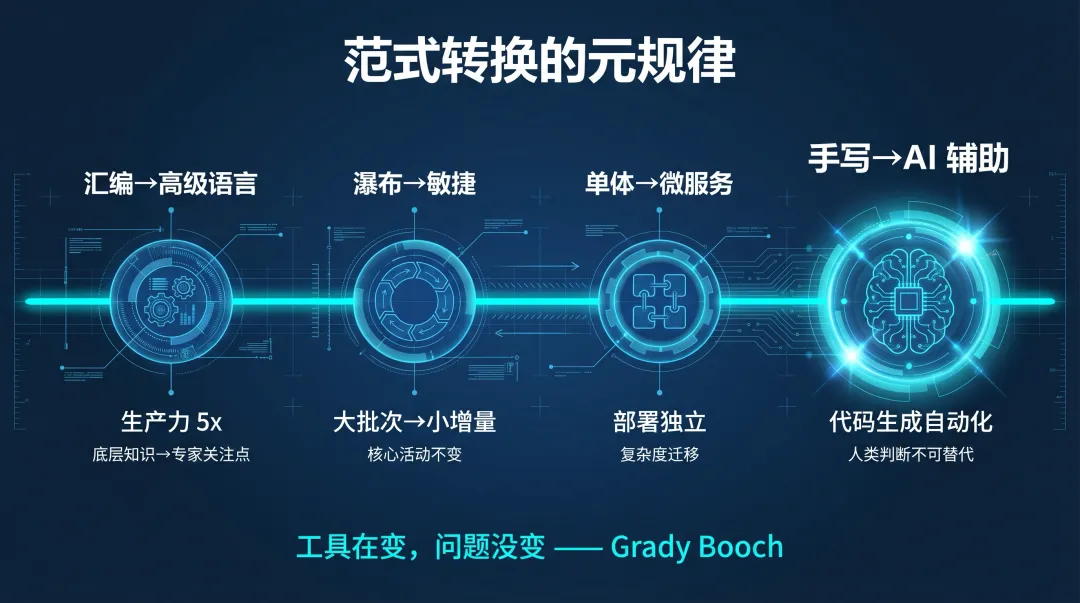
回顾历史上的每一次范式转换,有一个清晰的元规律:
| 手写 → AI 辅助 | 代码生成自动化 | 对本质复杂度的人类判断 |
每次转换都用一种复杂度换另一种,扩展了可尝试的范围,但从未消除对人类判断的需求。
AI 对软件工程的冲击,正在遵循同样的轨迹。它不会让软件工程消失——它会让软件工程重新定义自己。
Grady Booch 说得好:
"Your tools are changing, but your problems are not."
40 年前 Brooks 就看到了这个事实:软件工程的本质不是写代码,而是管理复杂度。 代码只是管理复杂度的手段之一。当 AI 接管了这个手段的大部分,软件工程师并没有失业——他们只是回到了这个职业最初始、最本质的角色:
理解混乱的现实世界,将其转化为有序的系统。
这个能力,从来都不廉价。
引用链接
[1]"编程通缩"理论:https://tidyfirst.substack.com/p/programming-deflation[2]2000 万用户:https://techcrunch.com/2025/07/30/github-copilot-crosses-20-million-all-time-users/[3]日活超过 100 万:https://www.digitalocean.com/resources/articles/github-copilot-vs-cursor[4]JetBrains 2025 调查:https://devecosystem-2025.jetbrains.com/artificial-intelligence[5]《没有银弹》:https://en.wikipedia.org/wiki/No_Silver_Bullet[6]"70% 问题":https://addyo.substack.com/p/the-70-problem-hard-truths-about[7]Kolmogorov 复杂度理论的分析:https://iamsweeper.com/2506-conservation-of-complexity-when-using-ai/[8]DORA 2025 报告:https://dora.dev/research/2025/dora-report/[9]METR 组织了迄今最严格的 AI 编程生产力随机对照试验:https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/[10]McKinsey 2026 年调研:https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/unlocking-the-value-of-ai-in-software-development[11]CodeRabbit 对 470 个 GitHub PR 的分析:https://www.coderabbit.ai/blog/state-of-ai-vs-human-code-generation-report[12]系统性数据:https://labs.cloudsecurityalliance.org/research/csa-research-note-ai-generated-code-vulnerability-surge-2026/[13]一年后自己宣布它"过时了":https://thenewstack.io/vibe-coding-is-passe/[14]ThoughtWorks 2026 年峰会:https://martinfowler.com/bliki/FutureOfSoftwareDevelopment.html[15]重新发现了 TDD 的价值:https://newsletter.pragmaticengineer.com/p/tdd-ai-agents-and-coding-with-kent[16]Stack Overflow 2025 调查:https://survey.stackoverflow.co/2025/ai[17]Klarna 是最典型的教训:https://www.fastcompany.com/91468582/klarna-tried-to-replace-its-workforce-with-ai[18]入门级招聘下降了 25%: https://spectrum.ieee.org/ai-effect-entry-level-jobs
