 夜雨聆风
夜雨聆风大家好这是open claw实战系列的第二篇,和大家一起探讨下怎么实现互联网研发团队的自动化工作流程。我们基于"多Agent协作架构"与"一人公司"等成功实践,为你拆解一套可直接复用的互联网产品研发自动化方案。核心是组建一支专业分工、流程闭环的AI研发团队,实现从需求到部署再到数据驱动的完整迭代。
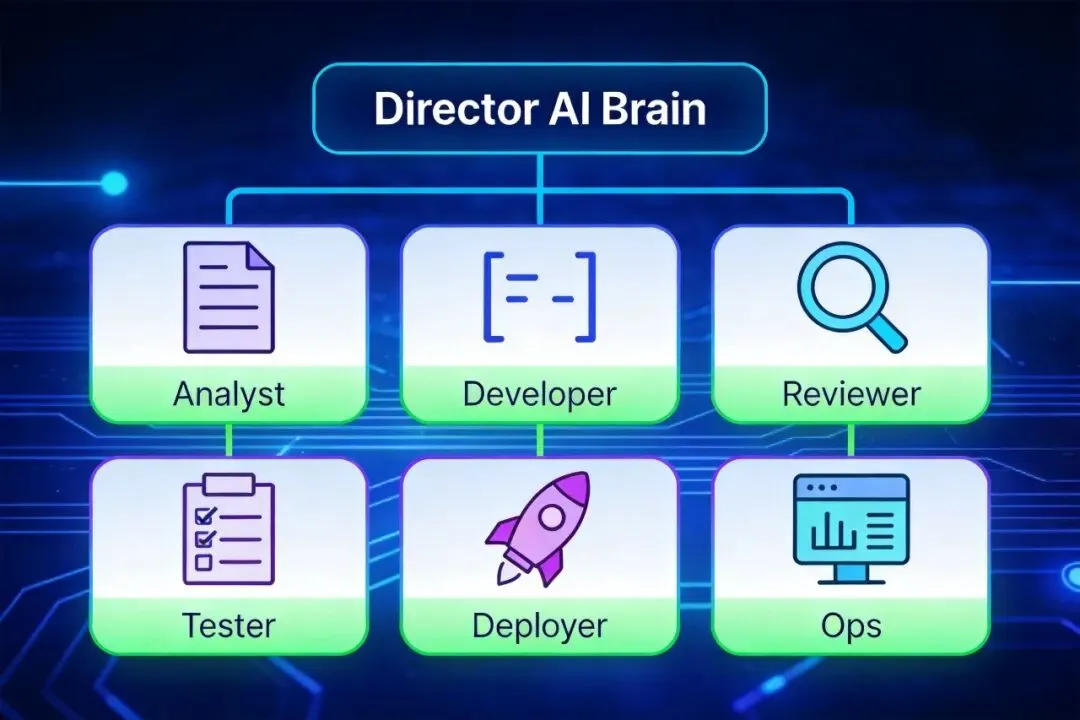
一、多Agent角色分工设计(研发团队架构)
借鉴"OpenClaw多Agent协作架构"中的三层模型,组建一支覆盖产品研发全周期的虚拟团队:
架构优势:遵循"单一职责"原则,每个环节由专业Agent处理,避免上下文污染,并通过并行提升效率。
二、核心业务流程与协作设计
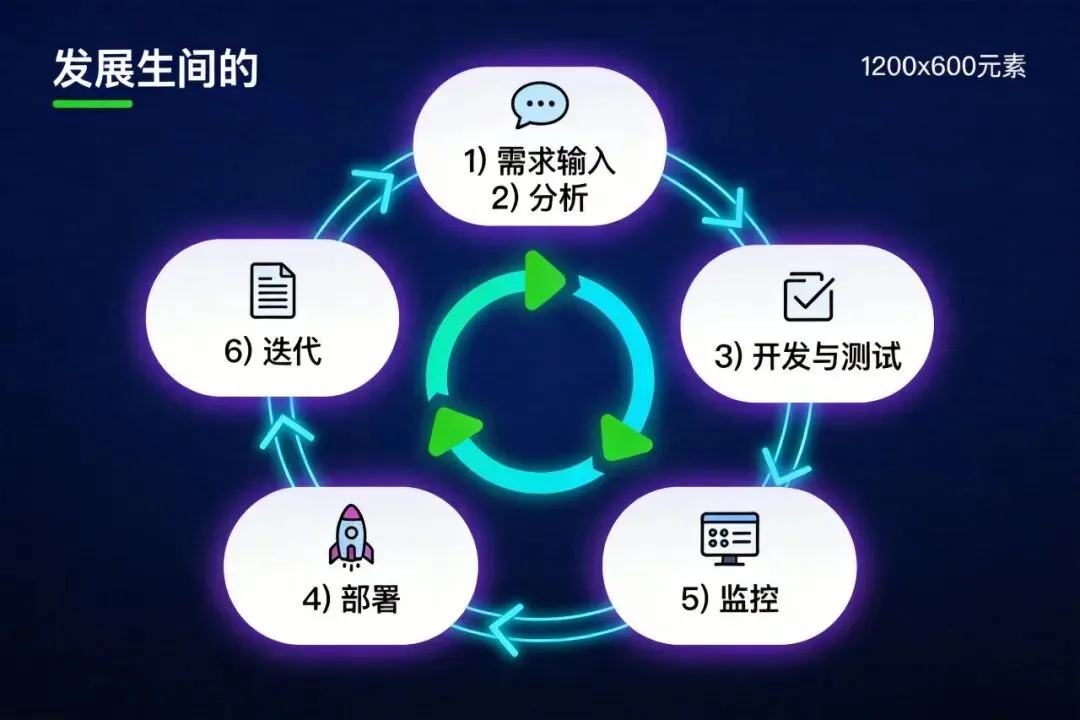
设计一个从需求触发到上线迭代的自动化闭环流程:
需求输入:你在飞书群@ director:"开发一个用户登录功能,支持邮箱密码和GitHub OAuth,包含JWT刷新机制。"需求分析与拆解: director调用analyst生成PRD文档(sessions_spawn),并基于PRD将任务拆解为开发、审查、测试子任务。并行开发与测试: director并行调用developer(编码)、reviewer(代码审查)、tester(编写测试用例)。三者通过共享工作区目录(如~/.openclaw/shared/code/)交换代码与文档。集成与部署: director汇总结果,调用deployer执行部署脚本,将代码部署到测试或生产环境。监控与反馈: opsAgent通过定时任务监控应用日志、业务指标(如日活、错误率),收集用户反馈,生成运营日报。数据驱动迭代: director定期(如每周)读取ops的报告和MEMORY.md中的历史问题,发起新一轮迭代任务,形成闭环。
协作核心:利用OpenClaw的 sessions_spawn 进行任务派发,通过共享目录和 **announce**回传机制实现信息同步。
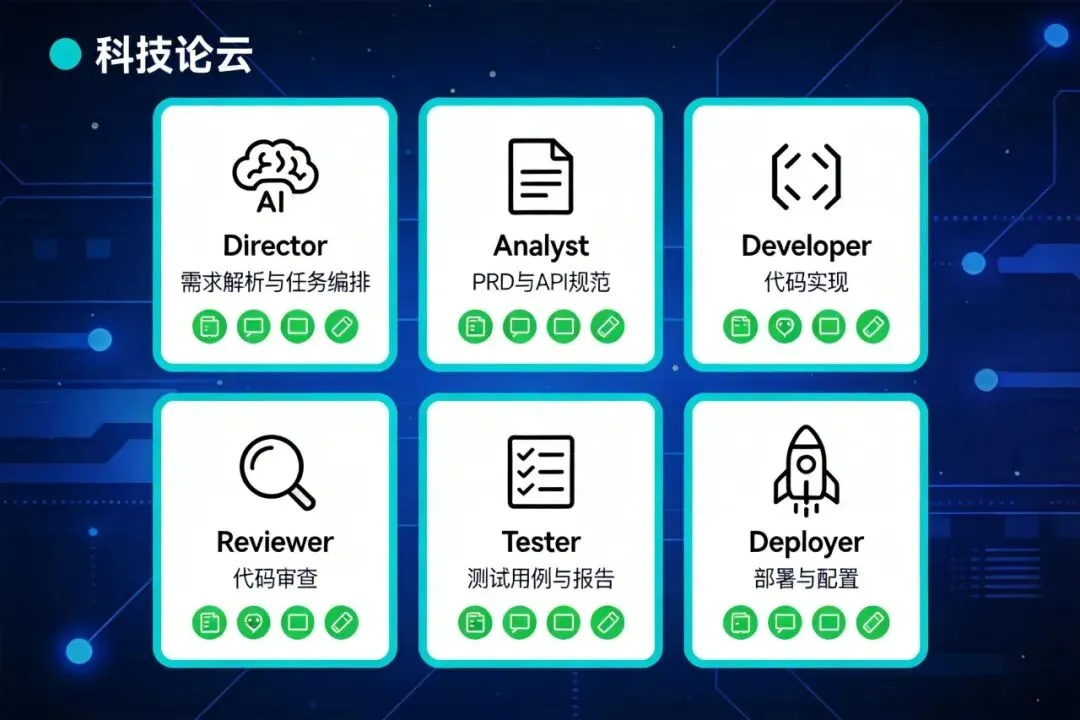
三、各角色核心工作步骤与Skill推荐
总指挥 Director
核心工作:需求解析、任务编排(DAG建模)、资源调度、结果聚合。 Skill推荐:无需特定Skill,其核心能力是调用子Agent。在 openclaw.json中配置subagents相关参数。关键配置: subagents.allowAgents列表需包含所有执行角色;model可配置为claude-sonnet-4-5以节约成本(相比Opus降低成本80%)。
需求分析师 Analyst
核心工作:将自然语言需求转化为结构化的PRD和API规范。 Skill推荐:可配置 web-search技能进行竞品调研。
开发工程师 Developer
核心工作:根据PRD实现代码。可进一步细分为 frontend-developer和backend-developer。Skill推荐: code-interpreter(执行代码)、git(版本控制)。可为其配置专用模型链,如在openclaw.json的agents.developer.model中绑定deepseek-coder。
代码审查员 Reviewer
核心工作:审查代码质量、安全性、性能。 Skill推荐: code-review类社区技能,或依赖其模型本身的能力。
测试工程师 Tester
核心工作:生成测试用例、执行测试、输出报告。 Skill推荐: test-runner(社区技能),或配置其调用exec工具运行项目自身的测试套件。
运维工程师 Deployer
核心工作:执行部署脚本,配置环境。 Skill推荐: shell-exec(核心)。关键安全配置:在其TOOLS.md中严格限制exec权限,仅允许运行特定的部署脚本目录。
运营监控 Ops
核心工作:定时抓取日志、监控API、分析业务数据。 Skill推荐: log-analyzer、metrics-fetcher等监控类技能,或配置其调用内部监控系统API。
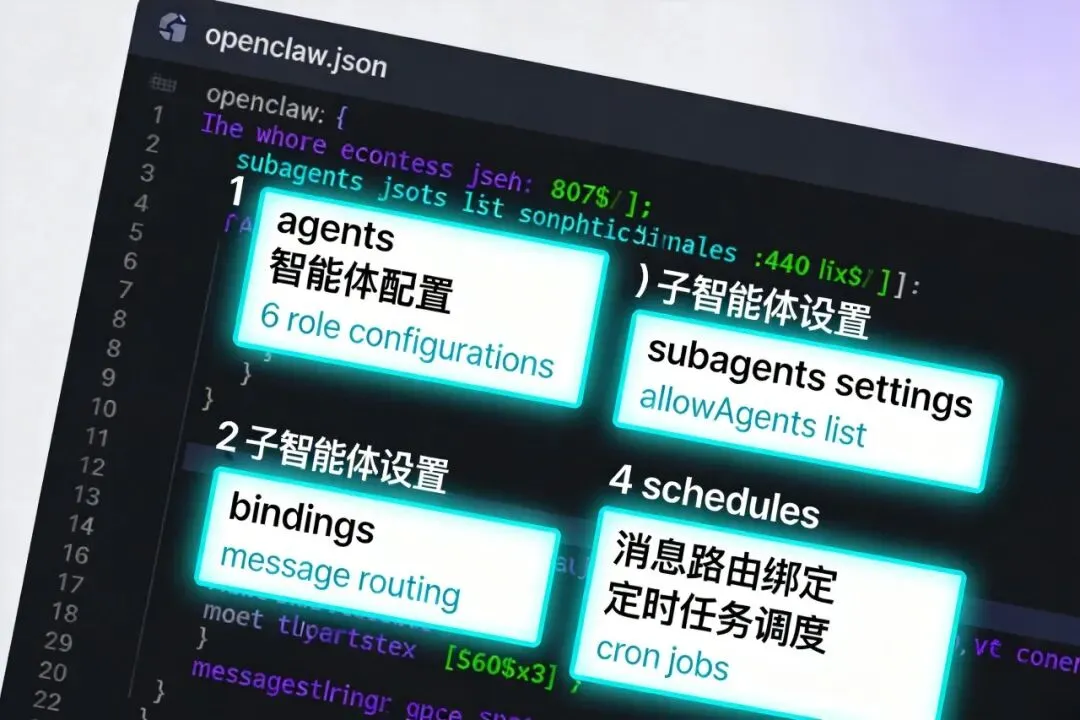
四、OpenClaw关键配置详解(实战要点)
全局配置 (openclaw.json) – 研发团队版
{
"agents": {
"list": [
{
"id": "director",
"name": "项目总监",
"default": true,
"workspace": "~/.openclaw/workspace-director",
"agentDir": "~/.openclaw/agents/director/agent",
"subagents": {
"allowAgents": ["analyst", "developer", "reviewer", "tester", "deployer", "ops"],
"maxSpawnDepth": 2,
"maxConcurrent": 8,
"model": "anthropic/claude-sonnet-4-5",
"runTimeoutSeconds": 900
}
},
{
"id": "developer",
"name": "开发工程师",
"workspace": "~/.openclaw/workspace-dev",
"agentDir": "~/.openclaw/agents/developer/agent",
"model": { "primary": "deepseek/deepseek-coder" }
}
// ... 类似配置analyst, reviewer, tester, deployer, ops
],
"defaults": {
"memorySearch": {
"extraPaths": ["~/.openclaw/shared"]
}
}
},
"bindings": [
// 飞书产品需求群绑定到director
{
"agentId": "director",
"match": { "channel": "feishu", "peer": { "kind": "group", "id": "product-dev-group" } }
}
],
"schedules": [
// 每日运营数据巡检
{
"name": "每日运营巡检",
"schedule": { "kind": "cron", "expr": "0 9 * * *" },
"payload": {
"kind": "agentTurn",
"message": "收集昨日产品运营数据(DAU、错误率、关键业务指标),生成日报并预警异常。",
"agentId": "ops"
}
}
]
}
灵魂与行为配置 (SOUL.md, AGENTS.md, TOOLS.md)
**SOUL.md**** (以Director为例)**:定义其"严谨、注重流程、风险意识强"的性格,明确"以交付可用软件为第一目标"。**AGENTS.md**** (核心)**:为每个Agent编写"岗位说明书"。例如Director的AGENTS.md需明确"标准新功能开发流程":1) 调用analyst(600s超时) 2) 调用developer(900s超时) 3) 并行调用reviewer和tester 4) 聚合结果交付。**TOOLS.md**** (安全关键)**:遵循"权限最小化"原则。例如deployer的TOOLS.md只允许exec特定目录下的部署脚本;developer的TOOLS.md可允许write代码目录但禁止exec生产环境命令。
记忆系统与共享知识库
分层记忆: MEMORY.md:存储团队级知识,如"登录功能常见陷阱"、"某云服务部署最佳实践"。~/.openclaw/shared/:团队共享目录,存放PRD、代码、测试报告、部署脚本等所有中间产物。各Agent独立的 memory/目录:存储角色专属经验,如reviewer记忆"常见的代码坏味道"。
防失忆配置:在 openclaw.json的agents.defaults.compaction中启用memoryFlush,确保关键决策在会话压缩前被写入记忆文件。
定时任务 (schedules 与 HEARTBEAT.md)
**schedules**:用于驱动核心跨角色流程,如"每日运营巡检"、"每周五自动生成产品迭代周报"。**HEARTBEAT.md**:用于各角色自检。例如ops的HEARTBEAT.md可设置每30分钟检查一次服务健康度。方案对比: schedules由Gateway统一调度,更适合跨Agent协作的定时任务;HEARTBEAT.md更轻量,适合角色内部状态检查。两者可结合使用。
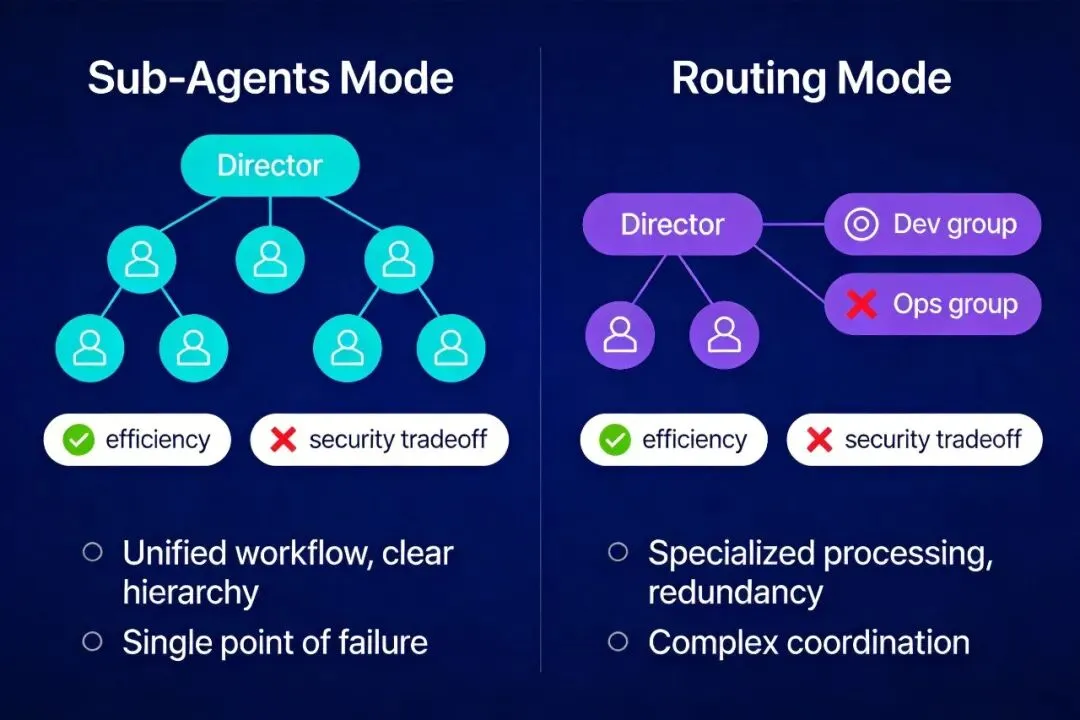
五、不同协作模式方案对比
根据知识库,研发协作主要有两种模式:
实战建议:研发主流程采用 Sub-Agents模式,由director统一调度。同时,可以为deployer和ops配置独立的飞书运维群(Routing模式),用于接收和处理紧急告警,实现安全隔离。
总结与启动建议
这套系统的本质是将软件工程的最佳实践(如敏捷、DevOps)AI化、自动化。启动关键:
从核心链路开始:先配置 director、analyst、developer三个角色,跑通"一句话需求生成PRD和示例代码"的最小闭环。逐步加入质量保障:加入 reviewer和tester,建立代码质量关卡。最后实现部署与监控:配置 deployer和ops,完成从开发到上线的最后一公里,并建立数据反馈环。安全与审核:生产环境部署、敏感操作务必设置人工审核节点, deployer的权限必须受到最严格限制。
通过以上配置,你可以将OpenClaw从一个对话助手,升级为一个能够理解需求、编写代码、测试部署、监控迭代的自动化研发组织,真正实现一人驱动一个产品从零到一的完整生命周期。
