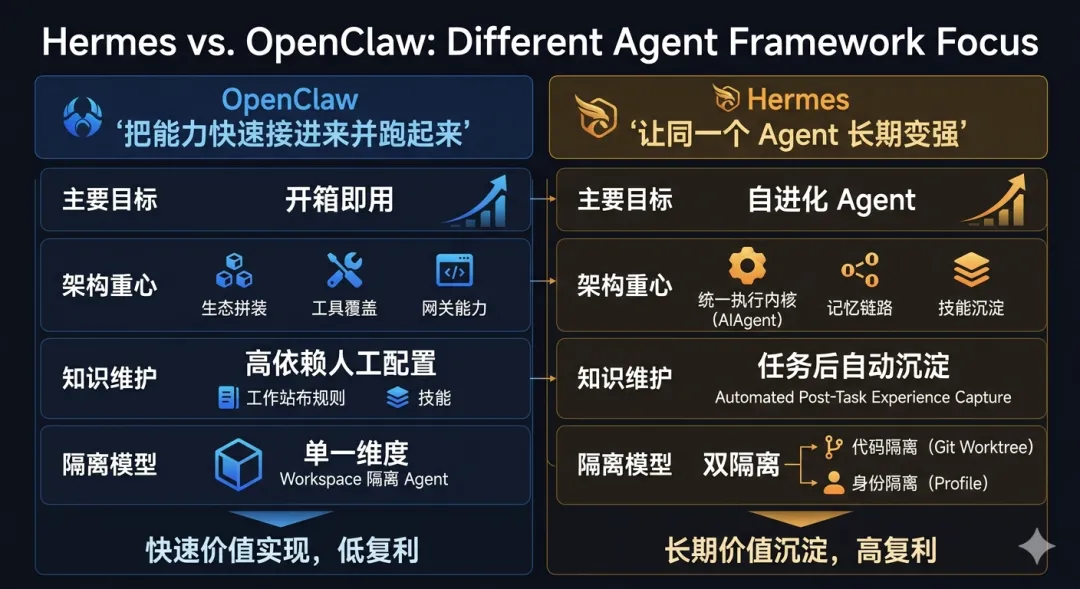
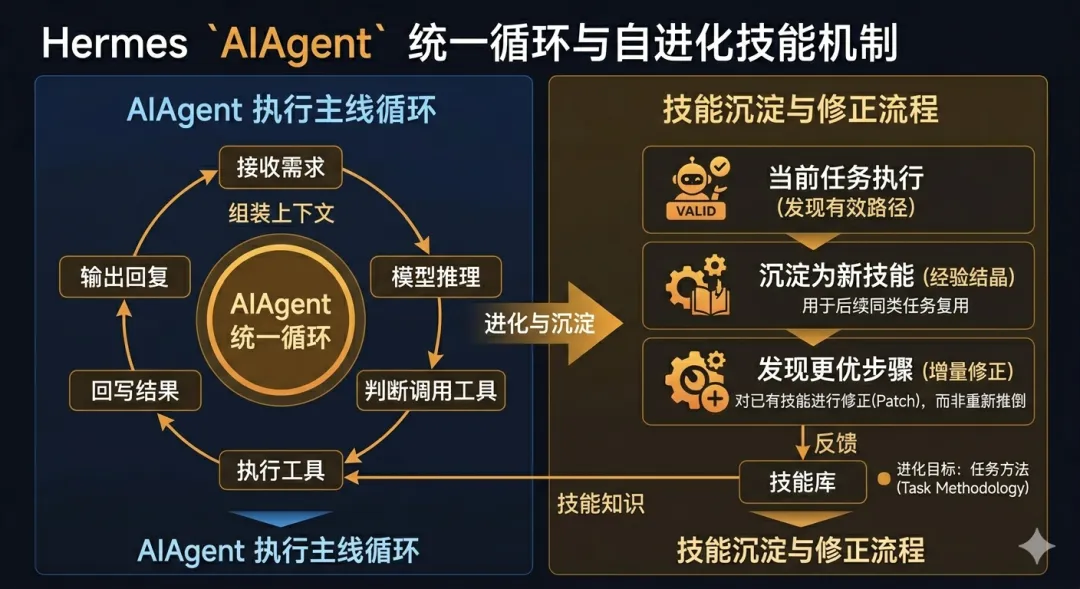
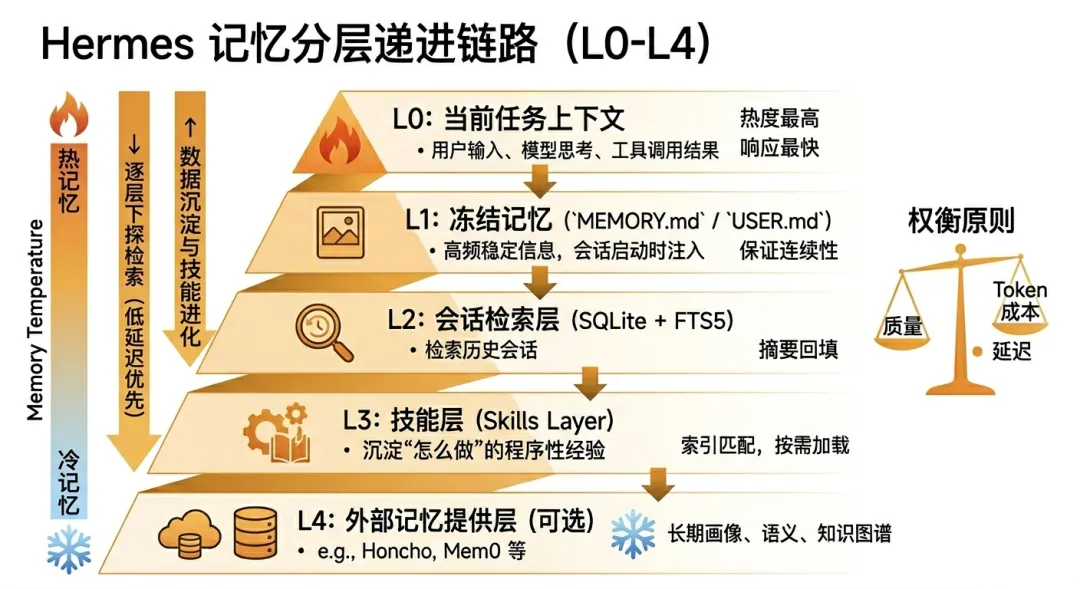
Hermes / OpenClaw:我现在的粗浅对比很多人会把 Hermes(/ˈhɜːrmiːz/,常读“赫尔蜜兹”)和 OpenClaw 放在一起比较,我自己看下来,这个比较角度是对的。 因为两者都能做 Agent,都能接工具、接平台、帮你完成任务,但它们优化的“第一目标”并不一样。如果用一句话概括: OpenClaw 更像“把能力快速接进来并跑起来”的框架,Hermes 更像“让同一个 Agent 长期变强”的框架。换个更常见的说法,Hermes 可以归到“自进化 Agent(Self-Evolving Agent)”这一路: 不是每次任务做完就归零,而是把执行过程里的有效方法沉淀成可复用经验,再在后续任务里持续修正和强化。下面我先从对比视角把差异讲清楚,再讲它具体是怎么做到的。第一,架构重心不同。 OpenClaw 的优势在网关能力、生态拼装和工具覆盖;Hermes 的优势在统一执行内核(`AIAgent`)、记忆链路和技能沉淀。 前者更像先把“能做的事”铺开,后者更像先把“同一件事越做越好”打穿。第二,知识维护责任不同。 OpenClaw 体系下,很多高质量效果依赖你写好 workspace 规则、选好 skills、持续维护;Hermes 也支持手动配置,但更强调任务后自动沉淀经验,尽量降低“人肉维护成本”。第三,隔离模型不同。 OpenClaw 常见做法是用 workspace 来隔离不同 agent;Hermes 这边更像“双隔离”:代码层用 git worktree 隔离改动,agent 状态层用 profile 隔离配置、记忆、会话、技能和网关进程。 所以 Hermes 不是没有隔离,而是把隔离拆成了“代码隔离 + 身份隔离”两个维度。差异讲完之后,再看 Hermes 的内部链路就更容易理解了。Hermes 的执行主线是一个统一循环(`AIAgent`): 接收需求 -> 组装上下文 -> 模型推理 -> 判断是否调用工具 -> 执行工具 -> 回写结果 -> 输出回复。 CLI、消息网关、定时任务、编辑器接入,基本都复用这条主线。这个设计的价值是能力一致,行为可预期。另外一个容易被忽略、但很关键的点是:Hermes 的 skill 不是“装完就不变”的。 它会在任务执行中把有效路径沉淀成技能,在后续同类任务里继续复用;如果新一轮执行出现了更优步骤,系统会对已有技能做增量修正(patch),而不是每次推倒重来。 这也是我为什么会把它归到“自进化 Agent”路线:它在进化的不是聊天语气,而是任务方法本身。再往下看,记忆在 Hermes 里不是附加功能,而是核心机制。 如果按 L0-L4 看它的记忆链路,大概是这样:L0:当前任务上下文 当前轮次的用户输入、模型思考、工具调用结果,热度最高、响应最快。L1:冻结记忆(`MEMORY.md` / `USER.md`) 高频稳定信息,每次会话启动时作为快照注入,保证偏好和关键事实连续。L2:会话检索层(SQLite + FTS5) L1 不够时,从历史会话里检索相关内容,再做摘要回填当前任务。L3:技能层(Skills) 沉淀“怎么做”的程序性经验。一般先做索引匹配,命中后再按需加载完整技能内容。L4:外部记忆提供层(可选) 比如 Honcho、Mem0 等,用于更重度的长期画像、语义记忆或知识图谱能力补充。这条链路的关键不是“层数多”,而是分层递进: 先用成本低、延迟低、稳定性高的层,不够再逐层下探。这样才能在长期使用里同时兼顾质量、延迟和 token 成本。回到最开始和 OpenClaw 的对比,我的结论是:如果你要的是“快速接入、多平台、多工具、开箱就能跑”,OpenClaw 的路径很直接。 如果你要的是“同一个 Agent 跑久了越来越懂你、重复任务越做越稳”,Hermes 这套执行内核 + 记忆链路会更有复利。
 夜雨聆风
夜雨聆风