 夜雨聆风
夜雨聆风还在被 Schema 变更搞得焦头烂额?
还在为每张表需要一个同步任务资源发愁?
本文带你用一个 YAML 文件,搞定万表实时入湖。
当你管理上千条同步链路时,你在管理什么?
数据团队有一条不成文的规律:同步任务的数量,永远比业务表增长得快。
一个 50 张表的业务系统,需要 50 条同步链路把数据搬进数据湖,这看起来还能接受。但当你的公司有 10 个业务线、200 个数据库实例、10000 张表时——你在维护的就不再是"同步任务",而是一个令人窒息的运维负担。
我们见过太多这样的场景:凌晨 2 点,上游加了一个字段,50 个同步任务集体报错,值班工程师逐个修;新业务上线要加 30 张表,等同步链路配完部署好,已经过去两天;每个任务独占计算资源,2000 个任务的资源开销里,60% 跑的是空转的空闲期。
这不是某个团队的问题,而是同步模式本身的问题。"一张表一个任务"的模式,在规模化的那一刻就注定崩溃。运维复杂度随表数量线性增长只是表象,更深层的问题是:Schema 变更时大面积报错、资源因任务隔离而大量浪费、新表接入需要人工介入整个流程。
有没有一种方案,能用一个作业同步成千上万张表?经过生产验证,Flink CDC 的 YAML API[1] 是这个问题的一个解法。
01
声明式同步:一个 YAML 的表达力
1.1 从"怎么做"到"要什么"
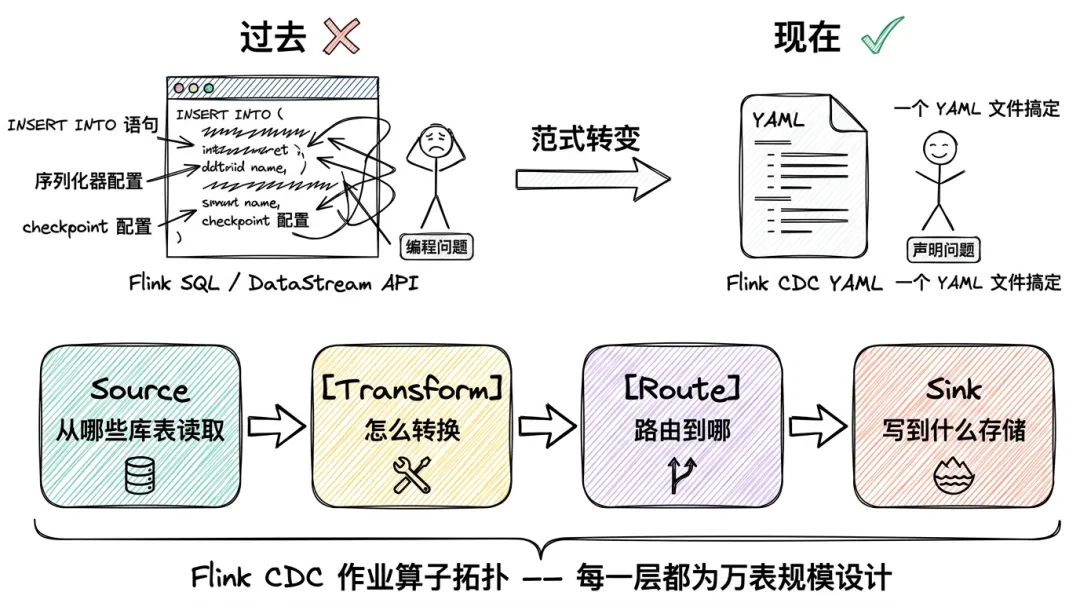
过去,我们用 Flink SQL 或 DataStream API 告诉系统"怎么做"同步——写 INSERT INTO 语句、定义序列化器、配置 checkpoint,每个同步链路都需要独立的作业定义。Flink CDC YAML 把数据同步从"编程问题"变成了"声明问题"。你只需要告诉四件事:Source → Transform → Route → Sink,Flink CDC 就能对应自动生成的对应的Flink 作业。:

这四件事情描述的是:从哪些库表读取、怎么转换、路由到哪、写到什么存储——全部在一个 YAML 文件里声明。
正则匹配,而非逐一列举: 一行 tables: order_db_[0-9]+.orders_\.* 替代 1000 行配置。当业务侧新增 order_db_5.orders_202604 时,Pipeline 自动发现并纳入同步。需要注意:CDC YAML 中的 . 是普通字符,匹配 Database 和 Table 之间的点分隔符;如需作为正则元字符,需转义为 \.。
动态路由,而非手动映射:分库分表是业务系统的常规操作,但对数据湖来说,800 张分表在湖里就应该是一张 ods_orders:
route:- source-table: order_db_[0-9]+.orders_[0-9]+sink-table: datalake.ods_orders
Route 还支持正则捕获组替换和 replace-symbol 整库同步,不再需要中间层 ETL 脚本做合并。
Schema Evolution,而非报错中断:当上游执行 ALTER TABLE ADD COLUMN 时,Pipeline 感知 DDL 事件并自动同步到下游。Pipeline 提供五种 Schema 变更模式,适应不同的数据一致性要求:
LENIENT(默认) | 宽容处理:删除列置为 nullable,不发送删表/清空表事件,保证同步不中断 |
EVOLVE | 严格同步所有变更,下游不支持则作业报错 |
TRY_EVOLVE | 尽量同步,失败不报错,但可能丢列或截断 |
IGNORE | 完全忽略 Schema 变更 |
EXCEPTION | 收到变更直接抛异常 |
此外,Sink 模块支持 include.schema.changes 和 exclude.schema.changes 参数,精细控制接收的变更类型——例如只同步建表和列相关事件,但排除删列。
内置 Transform,同步即加工:字段过滤、计算列追加、分区键设定,一次同步完成 ODS 层的基本加工:
transform:- source-table: order_db_[0-9]+.orders_\.*projection: \*, DATE_FORMAT(create_at, 'yyyyMMdd') AS ptfilter: status <> 'DELETED'primary-keys: id, ptpartition-keys: pt
Transform 还支持元数据列——直接引用源表的库名、表名甚至操作类型。结合 __data_event_type__ 和 SOFT_DELETE 转换器,可以将物理删除转为逻辑删除,保留删除记录:
transform:- source-table: db.tblprojection: \*, __data_event_type__ AS op_typeconverter-after-transform: SOFT_DELETE
1.2 一个生产级 YAML 长什么样
下面是一个经过生产长期验证的完整作业,展示如何用一个作业同步多个库的多张表到 Paimon [2] 数据湖:
source:type: mysqlhostname: example.comport: 3306username: cdc_usernamepassword: cdc_passwordserver-id: 5400-5500tables: order_db_[0-9]+.orders_\.*scan.incremental.snapshot.chunk.size: 8096scan.emit.create-table-events.in-batch.enabled: trueinclude-comments.enabled: truescan.incremental.snapshot.unbounded-chunk-first.enabled: truescan.only.deserialize.captured.tables.changelog.enabled: truetransform:- source-table: order_db_[0-9]+.orders_\.*projection: \*, DATE_FORMAT(create_at, 'yyyyMMdd') AS ptfilter: status <> 'DELETED'primary-keys: id, ptpartition-keys: pttable-options: bucket=-2route:- source-table: order_db_[0-9]+.orders_[0-9]sink-table: datalake.ods_ordersdescription: "订单分表合并"- source-table: order_db_[0-9]+.order_items_[0-9]+sink-table: datalake.ods_order_itemsdescription: "订单明细分表合并"sink:type: paimonname: Paimon Sinkcatalog.properties.metastore: restcatalog.properties.uri: dlf_uricatalog.properties.warehouse: your_warehousecatalog.properties.token.provider: dlftable.properties.deletion-vectors.enabled: truepipeline:name: orders-to-datalakeparallelism: 4
Source 配置说明:
table-name支持使用正则表达式一次性匹配多库多表。请注意 CDC YAML 中的
.是普通字符,用于匹配 Database 和 Table 的点分隔符。如需要将其作为正则表达式元字符使用则需要进行转义(\.)。scan.emit.create-table-events.in-batch.enabled控制每个快照分片大小。过大的分片大小可能导致读取单个分片时 TaskManager 节点内存不足。
过小的切片大小可能导致分片数量膨胀,导致负责管理分片元数据的 JobManager 节点内存不足。
如果您使用的是阿里云实时计算 Flink 服务,则可以额外配置
scan.emit.create-table-events.in-batch.enabled参数以便批量处理建表事件,避免初始化阶段花费过多时间。
Transform 配置说明:
projection:支持对字段进行重命名、裁剪,以及根据给出的表达式追加计算列filter:行级过滤,过滤掉不需要的数据primary-keys和partition-keys:设置对应表的主键和分区键table-options:设置 Paimon 表的元数据信息
Route 配置说明:
将分库分表路由到统一的湖表,实现多张分库分表到一张下游湖表的合并
Sink 配置说明:
table.properties.deletion-vectors.enabled启用删除向量以提升写入性能。catalog.properties.uriPaimon湖表使用的是阿里云提供DLF[4] catalog。
使用的优化参数:
server-id: 5400-5500:万表场景下,单个 server-id 会成为瓶颈,指定范围让 CDC 自动分配
scan.incremental.snapshot.unbounded-chunk-first.enabled: true:优先处理无界分片,规避 TaskManager OOM
scan.only.deserialize.captured.tables.changelog.enabled: true:反序列化前按表名过滤,万表场景显著降低 CPU 开销
table.properties.deletion-vectors.enabled: true:Paimon 删除向量,避免 Merge-on-Read 合并开销
如果你使用阿里云实时计算 Flink[3],还可以通过 using.built-in-catalog 直接复用平台上已经创建 Catalog,省去手写连接属性:
source:type: mysqlusing.built-in-catalog: mysql_rds_catalogsink:type: paimonusing.built-in-catalog: paimon_dlf_catalog
02
为什么是 Paimon:端到端的深度集成
为什么重点讲 Paimon 作为 Sink?因为 Flink CDC Pipeline 和 Paimon 之间不只是"数据源→目的地"的简单对接,而是一种端到端的深度耦合——这种耦合是"万表入湖"方案成立的前提。
你不能指望手动创建 10000 张 Paimon 表,Pipeline 在首次同步时根据上游表结构自动在 Paimon 中建表,这就是前提,但这只是开始。
更关键的是 Schema Evolution 的端到端集成。Flink CDC 感知到 DDL 变更后推送到 Paimon,Paimon 作为流式数据湖格式原生支持 Schema 变更的持久化——追加新列无需重写历史数据文件。这意味着"上游加字段,下游自动同步"不再是需要人工介入的故障场景,而是一个静默完成的日常操作。
除此之外,深度集成还体现在:Transform 中的 primary-keys 和 partition-keys 直接控制 Paimon 表的主键和分区策略,无需 Sink 端重复配置;table-options(如 bucket=-2 即 Postpone Bucket Mode)直接透传为 Paimon 表属性;Paimon 的删除向量与 CDC 的更新/删除事件天然配合——CDC 产生删除事件时,Paimon 通过删除向量标记删除,避免 Merge-on-Read 的合并开销。
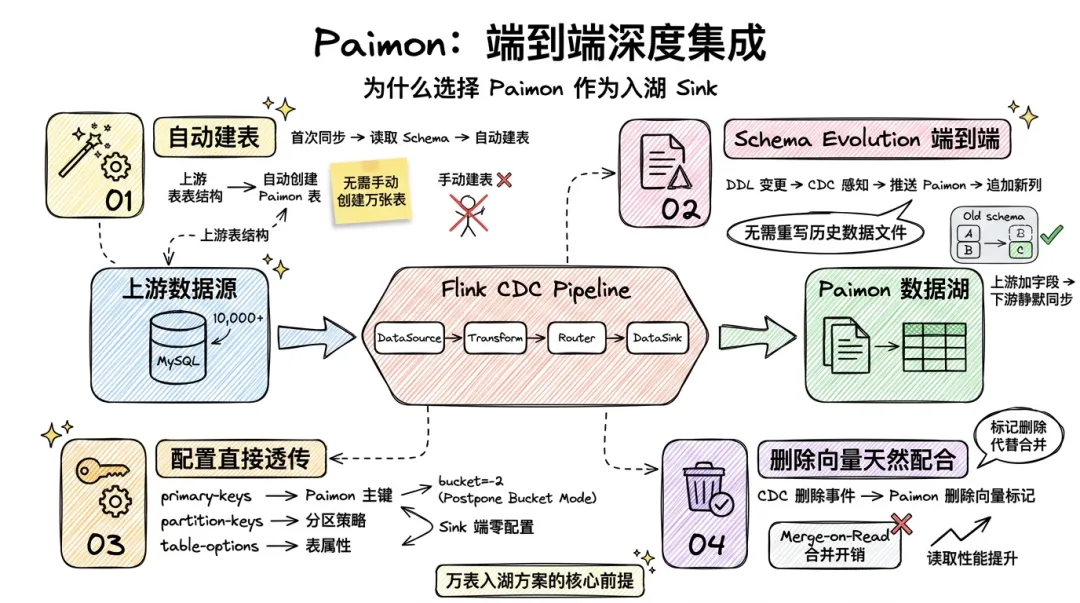
这套端到端的深度集成,是 Paimon 作为 Flink CDC 最佳数据湖搭档而非其他存储的核心理由。
03
面向 AI 设计的同步框架
到这里为止,我们讨论的都是 Flink CDC Pipeline 作为同步框架的技术能力。但 YAML 声明式 API 还带来了一个容易被忽视、却在 AI 时代意义深远的优势:它是面向 AI 可操作的设计。
3.1 面向 AI 可操作的设计
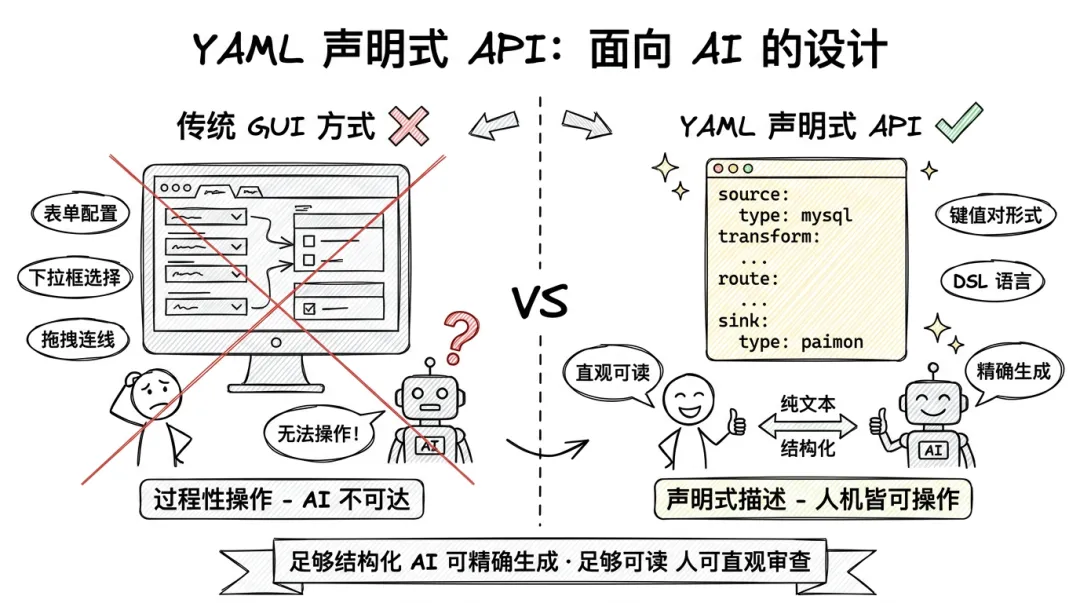
传统的 GUI 数据同步产品,用户需要通过大量表单、下拉框、拖拽操作来配置同步链路。这些操作本质上是过程性的——你需要一步步告诉系统"先选这个、再填那个、然后勾选这个"。这种交互模式对人来说已经够繁琐了,对 AI 来说更是不可操作:一个下拉框选了什么值,AI 怎么知道?一个拖拽连线连到了哪里,AI 怎么表达?
YAML 声明式 API 天然解决了这个问题。它是一个纯文本、结构化的描述——Source 是什么、Transform 规则是什么、Route 规则是什么、Sink 是什么,全部以键值对的形式存在。这种形式既能被人类读写,也能被 AI 直接理解和生成。你可以把 Flink CDC 的 YAML 看作一种 DSL——它足够结构化,AI 可以精确生成;又足够可读,人可以直观审查。
3.2 AI 开发入湖作业实践
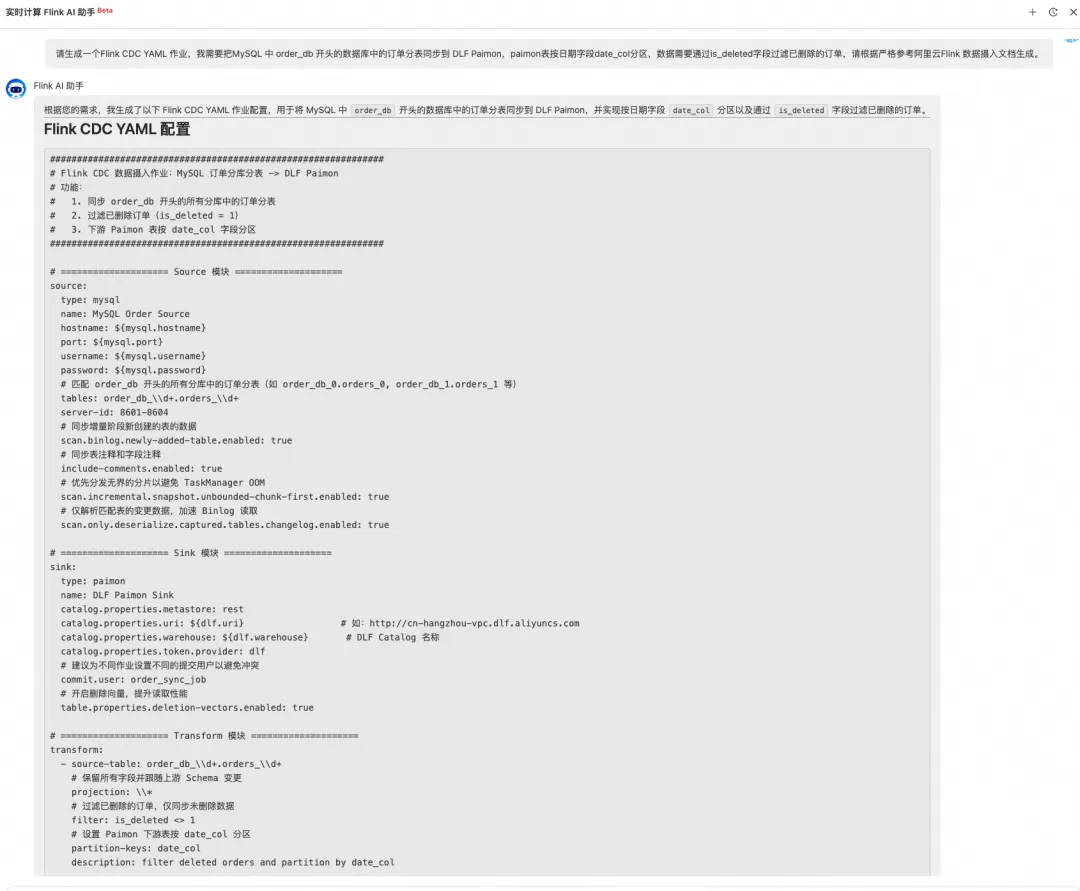
基于此,阿里云实时计算 Flink 提供了 AI 助手能力:在控制台右下角点击悬浮按钮,即可打开 AI 助手,用自然语言描述你的同步需求——例如"请生成一个Flink CDC YAML 作业,我需要把MySQL 中 order_db 开头的数据库中的订单分表同步到 DLF Paimon,Paimon 表按日期字段 date_col 分区,数据需要通过 is_deleted 字段过滤已删除的订单,请根据严格参考阿里云 Flink 数据摄入文档生成"——AI 助手会直接生成完整的 YAML 配置。你只需要检查、微调、部署即可。
当然,你也可以使用其他模型或 AI 工具生成 YAML 作业,下面是笔者用 Qoder 生成的 YAML 文本,使用的提示词完全一样。
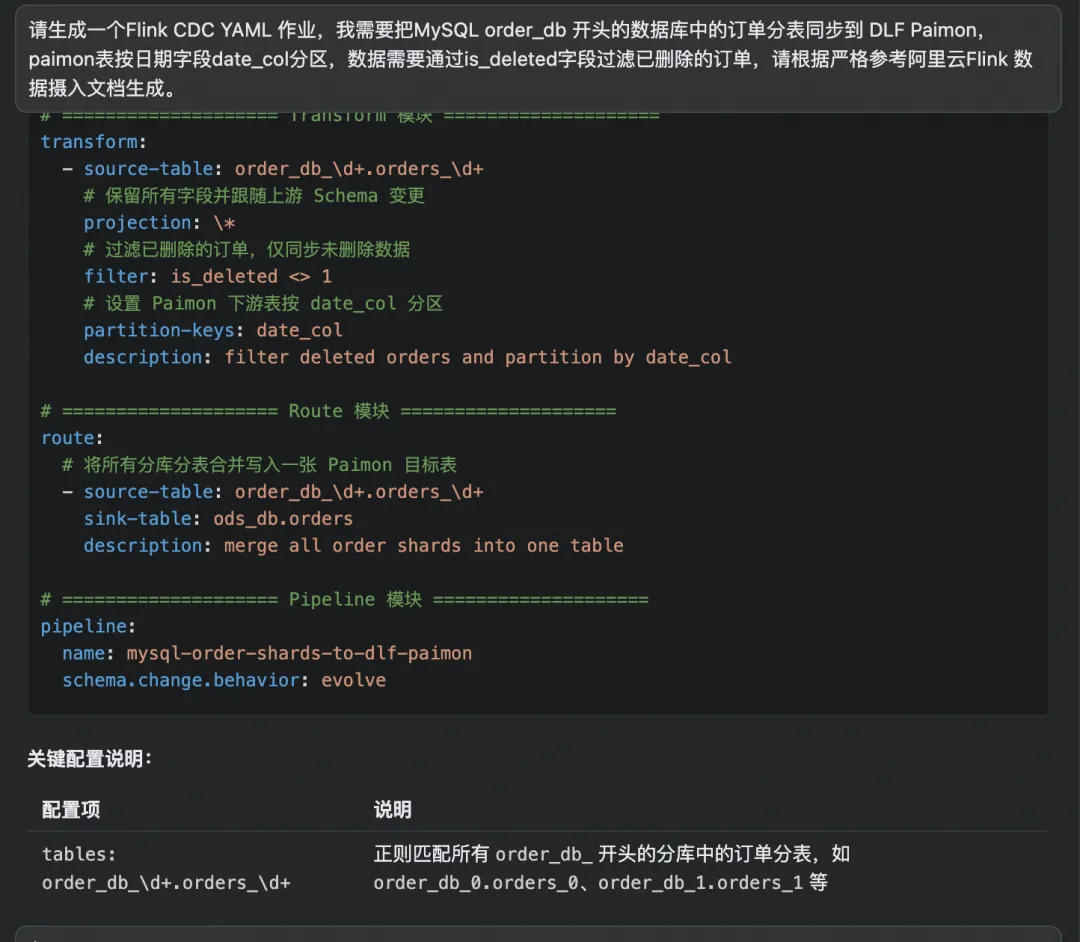
这不只是一个便捷功能,而是声明式 API 与生成式 AI 的一种深度契合:当你的配置本身就是结构化文本时,AI 就能端到端地参与从需求到配置的整个过程。反过来想——如果同步框架的配置是 GUI 表单,AI 连输入框都填不了,更别说生成一整套同步方案了。从这个角度看,YAML 声明式 API 不只是"比 GUI 更方便",而是为 AI 时代的同步工具设定了一个基本前提:配置必须是机器可读可写的,人才能从繁琐的配置工作中解放出来。
注: 实时计算Flink AI 助手还处于beta公测中,模型生成内容的准确性和完整性无法保证,仅供您参考。其他AI 模型和工具生成的YAML文本也仅供参考,使用前建议对比官方文档核对后上线。
04
万表规模下的生产实践
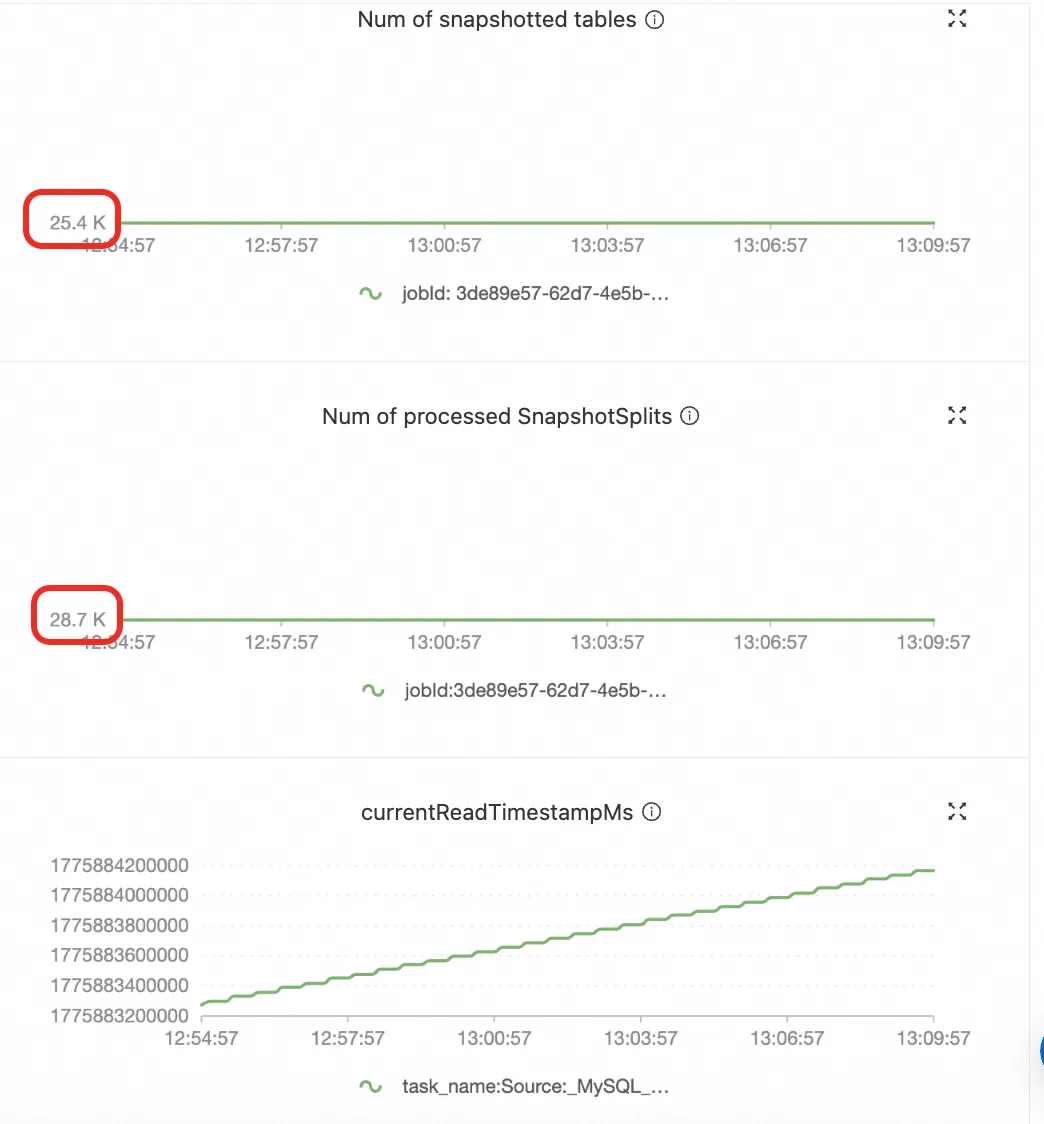
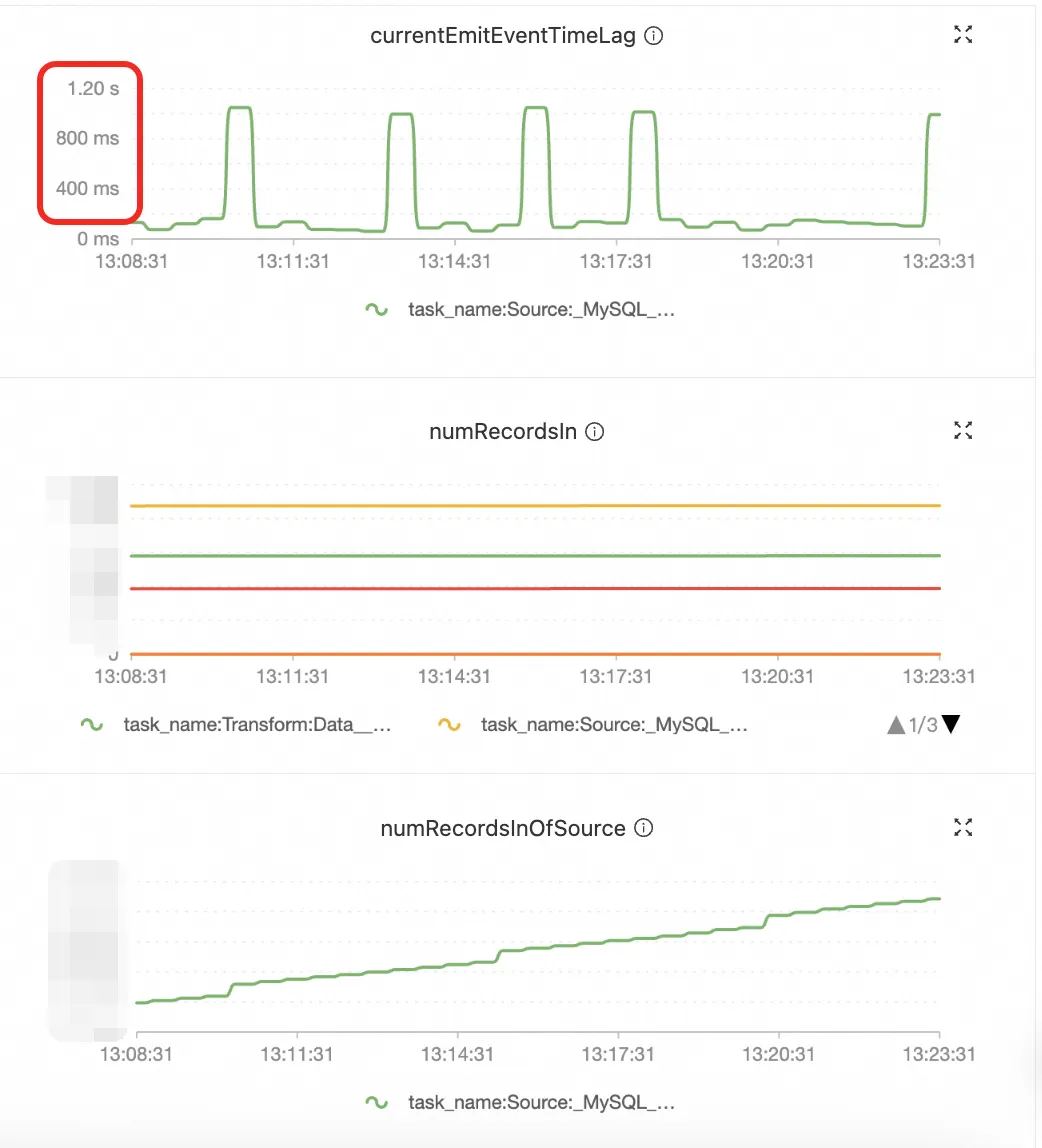
前面讲的都是在理想配置下 Pipeline 能做什么,但实际生产中,当一个作业的表数量超过 5000 之后,很多在百表规模下不成问题的事情开始随量增长而质变,变成一个个技术硬约束。这一节我们分享下,在规模上来之后我们踩过的坑和对应的优化,下图为阿里云实时计算 Flink 线上作业部分指标截图,该作业同步25000+表,数据延迟稳定在秒级,已稳定运行1年多。
 |  |
4.1 MySQL CDC 优化
source:# 适当调大 chunk 大小scan.incremental.snapshot.chunk.size: 80960# 批量下发建表事件scan.emit.create-table-events.in-batch.enabled: true# 支持动态读取作业运行阶段创建的新表scan.binlog.newly-added-table.enabled: true
Chunk 大小建议 8096~80960,过小会导致切片过多,过大会占用过多内存。
批量下发建表事件,避免表结构协调耗时过长。
配置动态新增表功能,避免增加分表时需要重新配置作业。
4.2 Paimon Sink 优化
sink:# 建议为不同作业设置不同的提交用户以避免冲突commit.user: order_sync_job# 开启删除向量,提升读取性能table.properties.deletion-vectors.enabled: true
建议为不同作业设置不同的提交用户以避免多作业或多客户端提交冲突。
批开启删除向量,提升湖上数据分析时的读取性能。
4.3 Schema Evolution 优化
Flink CDC Pipeline 原生支持 Schema Evolution,当上游表结构变更时, 作业支持下述DDL自动处理
新增列 | 自动同步至下游,Paimon 表新增对应列 |
修改列类型 | 支持兼容的宽类型变更(如 INT → BIGINT) |
删除列、清空表、删除表 | 默认(Lenient 模式),忽略破坏性表结构变更事件,也支持手动启用。 |
pipeline:# 自动同步安全的表结构变更,建议使用schema.change.behavior: LENIENT# 根据资源调整并发度parallelism: 8
建议使用 LENIENT(宽容)模式,自动同步安全的表结构变更
并发度根据 Source 端数据库承受能力和 Flink 集群资源综合评估。
4.4 作业管理和升级
1. 配置版本化:将 YAML 文件纳入 Git 管理,变更可追溯
2. 平滑升级:通过 Savepoint 实现作业升级,保证数据消费不重不漏。
如果您在进行跨版本升级,则可能需要额外传递 allow-nonRestored-state 参数来忽略部分不兼容的算子状态。
4.5 常见问题
(1)Source 分片大小与内存问题
scan.incremental.snapshot.chunk.size 同时影响 TaskManager 和 JobManager 的内存消耗,但方向相反:
分片太大 → 读取单个分片时 TaskManager 内存不足
分片太小 → 分片数量膨胀,JobManager 持有的分片元数据把内存撑爆
经验值是 8000~16000 之间取平衡,具体取决于单行数据宽度。窄表可以适当调大,宽表偏向 8000。修改分片大小后需要无状态重启作业才能生效——Savepoint 恢复不会重新分片。
(2)初始化阶段的建表风暴
在万表场景下,Pipeline 启动时需要为每张表向 Sink 端发送建表事件。如果不加控制,5000 多个建表事件集中下发,Schema 协调阶段耗时极长。开启 scan.emit.create-table-events.in-batch.enabled: true 后,建表事件从逐个同步发送改为批量异步发送。在阿里云实时计算Flink的线上作业测试中,初始化耗时从 45 分钟缩短到 8 分钟。
(3)Transform 和 Route 的匹配规则差异
这是一个容易让人困惑的设计:Transform 是"首匹配",Route 是"全匹配"。Transform 规则从上到下匹配,第一条命中就生效,后续规则不再检查。Route 规则则不同——所有匹配的规则都会生效。如果你只想匹配第一条 Route 规则,需要显式配置 route-mode: FIRST_MATCH。建议:在写 Transform 时,把所有针对同一组表的操作合并到一条规则里,而不是拆成多条依赖匹配顺序。
(4)资源规划参考
数据规模 | 并行度 | JM 内存 | TM 内存 | 说明 |
1000 表 | 2~4 | 2GB | 8GB | 适合验证和小规模业务 |
5000 表 | 4~8 | 4GB | 16GB | 中等规模,需关注 JM 内存 |
10000+ 表 | 8~16 | 8GB | 32GB | 建议开启批量优化参数 |
这些数字不是绝对值,只是我们针对客户作业 pattern 总结的经验值,建议先以小规模试跑,逐步扩容。
(4)监控与运维
在作业上线后,需要重点关注四个核心指标,并建议针对这四个指标配置告警。
指标 | 关注点 | 告警建议 |
currentEmitEventTimeLag | 数据延迟 | > 5min |
checkpointDuration | Checkpoint 耗时 | > 3min |
numRecordsIn / numRecordsOut | 吞吐量 | 突降 50%+ |
numberOfFailedCheckpoints | Checkpoint 失败数 | > 3 |
动态加表是最实用的运维能力之一:开启 scan.binlog.newly-added-table.enabled: true 后,作业运行期间新增的表(只要匹配 tables 正则)会自动纳入同步——业务侧新加表,数据团队不需要介入。
写在最后
从"一对一"到"一对多",表面上是配置方式的变化,本质上是数据同步范式的转变:从命令式地告诉系统"怎么做",到声明式地告诉系统"我要什么"。
这种转变在 AI 时代尤为重要。 当 LLM 遇到 GUI 配置界面,它只能模拟人类"点击按钮序列"——这种方式难以审计、无法版本化、错误不易追溯。而当同步逻辑是一个 YAML 文件时,AI 可以直接理解需求、生成配置、审查语义、修改参数——整个过程可追溯、可回滚、可测试。声明式配置是 AI 与基础设施之间的"自然语言接口",而 GUI 很难成为这个接口。
这带来的不只是运维效率的提升。当你的同步逻辑可以用一个 YAML 文件完整描述时,它就变成了一个可以被版本管理、Code Review、自动化测试的工程资产——而不是散落在调度系统里的 2000 个独立作业。
Flink CDC 与 Paimon 的深度集成,让这套方案在万表规模下经过了生产验证:自动建表、Schema Evolution 端到端贯通、删除向量优化、声明式 Transform——这些不是独立的特性,而是一个完整的技术栈在协同工作。如果你正在被大规模同步入湖的问题困扰,建议的路径是:
需求描述给你的 AI 模型或 阿里云 Flink AI 助手,生成一个简单 CDC YAML 作业
参考 Flink CDC 开源社区文档或阿里云 Flink 数据摄入文档,验证作业逻辑是否符合预期
按照需求扩大同步表的范围,按文中给出的资源规划调整作业资源
根据作业运行指标和业务特性,配置业务所需的监控告警
如果以上提到的能力想进行试用,可以直接在阿里云上搜索相关产品
阿里云 Flink 数据摄入:云上全托管Flink CDC,在开源内核的基础上,通过插件化开发提供更多增值服务,提升易用性并降低开发运维门槛。https://help.aliyun.com/zh/flink/realtime-flink/getting-started/quick-start-for-data-ingestion-yaml-jobs
阿里云DLF:云上全托管Paimon,提供智能湖表优化、智能存储分层、存储指标可观测、快照版本回溯等能力。https://www.aliyun.com/product/dlf
阿里云Flink AI 助手:基于大语言模型(LLM)构建的智能开发工具,旨在降低Flink开发的门槛,协助用户完成从 SQL/YAML 代码生成、逻辑解释到故障诊断的全流程工作。https://help.aliyun.com/zh/flink/realtime-flink/user-guide/flink-ai-assistant-beta
参考文档:
[1] Flink CDC 开源社区文档:https://nightlies.apache.org/flink/flink-cdc-docs-stable/
[2] Apache Paimon 开源社区文档:https://paimon.apache.org/docs/master/
[3] 阿里云 Flink 数据摄入官方文档:https://help.aliyun.com/zh/flink/realtime-flink/developer-reference/data-ingestion-development-reference/
[4] 阿里云 DLF 官方文档:https://help.aliyun.com/zh/dlf/dlf-2-0/product-overview/what-is-data-lake-formation

欢迎加入“Flink CDC 社区交流群”群的钉钉群号: 80655011780


Flink Forward Asia 2026 将于 6 月 26 至 27 日在深圳举行,现面向全球征集议题。活动聚焦实时计算与 AI 的融合,欢迎开发者与 AI 从业者提交创新思路与实践经验。议题将经过专业评选委员会审核,提交截止日期为 5 月 29 日。参会嘉宾可免费报名,获取技术前沿与行业动态。期待您的参与,期待您的参与,共同探索实时 AI 的未来!
PC 端:https://asia.flink-forward.org/shenzhen-2026
打开 FFA 2026 官网,点击「议题征集」或者「参会」
移动端:扫描下方二维码或点击文末「阅读原文」
 (扫描二维码,提交议题) |
(扫码即刻抢占席位) |




 点击「阅读原文」跳转 FFA 2026官网提交议题或报名 ~
点击「阅读原文」跳转 FFA 2026官网提交议题或报名 ~
