 夜雨聆风
夜雨聆风未来已来,只需一句指令,养龙虾专栏导航,持续更新ing…
本文适配2026.4.11+版本
想象一下:你的 AI 助手就像一位朋友,刚认识时彼此陌生,但随着时间推移,他逐渐记住了你的喜好、习惯和重要细节——这正是「梦境」功能的魔力所在。
一、为什么需要「梦境」功能?
1.1 AI 的「健忘症」困境
传统 AI 助手面临一个根本性问题:会话结束后,所有上下文烟消云散。这导致两种极端情况:
| 过度保守 | ||
| 过度囤积 |
梦境(Dreaming) 正是为解决这一痛点而生——它不是简单的存储扩容,而是模拟人类睡眠记忆巩固机制的智能筛选系统。
💡 注:就像人类通过睡眠整理白天学到的知识,重要的记忆被强化,琐碎的细节被过滤,AI 也需要这样一个"休息整理"的过程。
二、梦境的核心原理:三阶段睡眠周期
OpenClaw 的梦境系统借鉴了神经科学的睡眠理论,将记忆整理分为三个严格顺序执行的阶段:

2.1 阶段详解
| Light(浅睡) | |||
| REM(快速眼动) | |||
| Deep(深睡) |
关键机制:只有深睡阶段会实际修改长期记忆。前两个阶段仅生成"强化信号",用于提升候选条目在深睡阶段的评分权重。
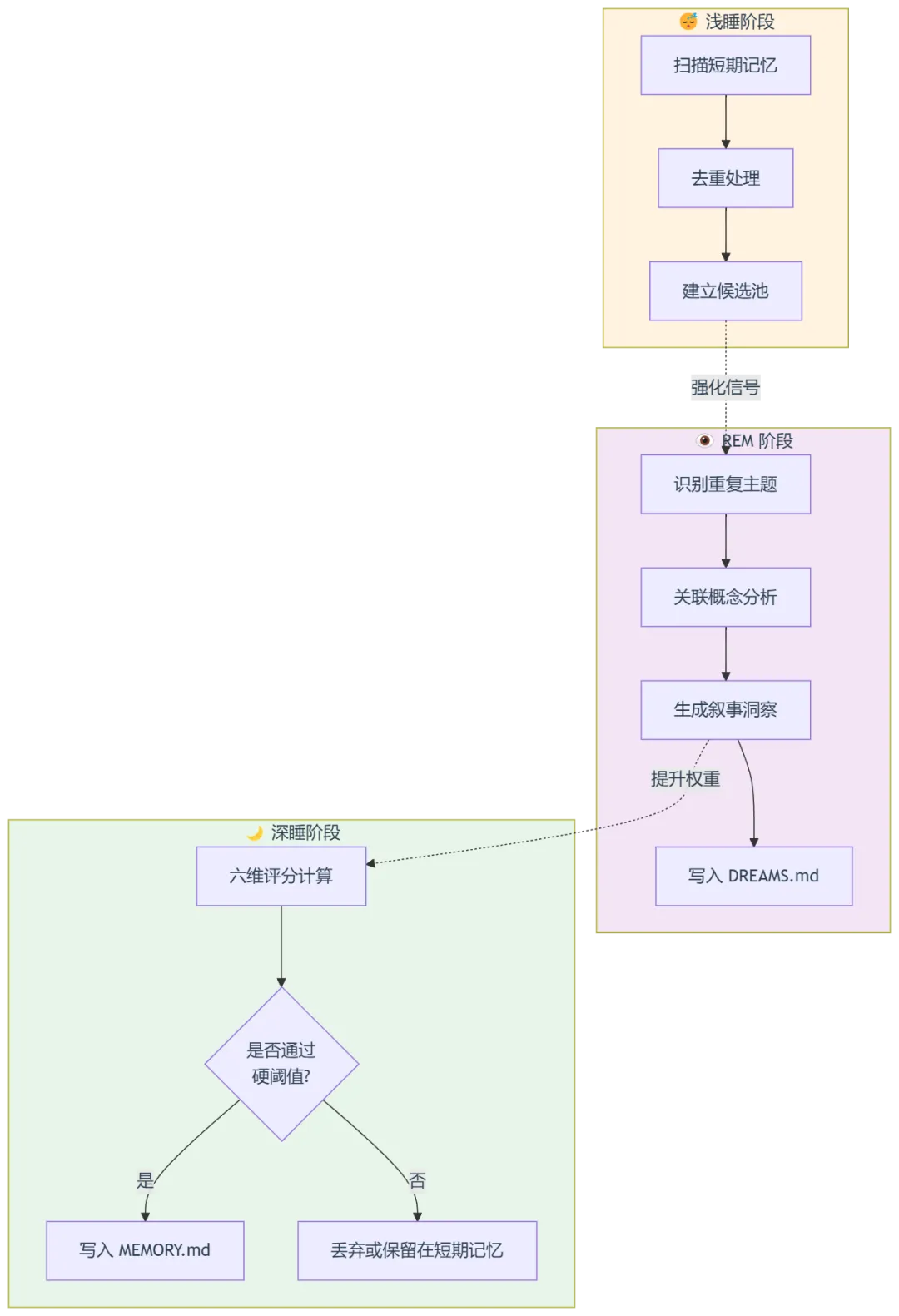
2.2 六维评分算法
深睡阶段采用证据驱动的加权评分模型决定记忆去留:
| Relevance(相关性) | |||
| Frequency(频率) | |||
| Query diversity(查询多样性) | |||
| Recency(时效性) | |||
| Consolidation(巩固度) | |||
| Conceptual richness(概念密度) |
评分计算流程:

晋升门槛:候选需同时满足三个硬阈值:
minScore ≥ 0.8(默认,可调整) minRecallCount ≥ 3次 minUniqueQueries ≥ 3个不同查询上下文
⚠️ 重要说明 minScore 可在 0.6~0.85 之间调整,但官方文档明确指出这些阈值是内部实现细节,不暴露为用户配置项。如需调整,只能通过 CLI 命令的命令行参数临时覆盖。
三、开启梦境:配置与命令
3.1 重要修正:默认关闭,需显式开启
实际情况:梦境是实验性功能,默认禁用(
enabled: false),必须手动启用。
3.2 三种开启方式
方式一:配置文件(推荐用于生产环境)
在 openclaw.json 中添加:
{"memory": {"dreaming": {"enabled": true,"frequency": "0 3 * * *","timezone": "Asia/Shanghai"}}}
关键参数说明:
enabled | false | true/false) | |
frequency | "0 3 * * *" | ||
timezone |
⚠️ 注意:
mode(如 core/rem/deep)不是配置项,phase policy 是内部实现细节,不暴露为用户配置。
方式二:聊天命令(适合快速体验)
/dreaming on | ||
/dreaming off | ||
/dreaming status | ||
/dreaming help |
⚠️ 注意:梦境没有"模式"概念,三个阶段是自动顺序执行的内部流程。
方式三:CLI 工具(适合脚本化与预览)
# 🔍 预览哪些候选会被晋升(干运行,不实际写入)openclaw memory promote# ⚠️ 实际应用晋升(谨慎使用)openclaw memory promote --apply# 🔧 限制数量 + 设置临时阈值openclaw memory promote --limit 10 --min-score 0.75# 🧠 解释特定查询的晋升逻辑openclaw memory promote-explain "部署工作流"# 📊 查看详细状态openclaw memory status --deep# 🌙 预览 REM 反思(不写入任何内容)openclaw memory rem-harness# 📋 预览 REM 反思 + JSON 输出openclaw memory rem-harness --json
四、输出产物:梦境日记与长期记忆
4.1 DREAMS.md(人类可读的梦境日记)
每次梦境周期结束后,系统自动生成叙事性总结,例如:
## 🌙 Dream Diary — 2026-04-12 03:00 UTC### 周期概览- 扫描信号:47 条短期记忆- REM 洞察:识别出 3 个重复主题(API 设计、性能优化、团队扩展)- 晋升记忆:5 条进入 MEMORY.md### 关键发现"你近期频繁讨论 GraphQL 与 REST 的权衡,特别是在微服务边界场景下。这看起来是一个持续的技术决策过程,已记录相关偏好。"### 晋升条目摘要1. [技术偏好] 倾向 GraphQL 用于 BFF 层,REST 用于服务间通信2. [项目背景] Q2 重点:支付网关重构(提及 5 次,跨 3 个会话)3. [团队信息] 后端团队计划扩展至 8 人(来自 4 月 10 日对话)
设计意图:DREAMS.md 纯粹是透明度工具,供用户审查 AI 的"思考过程",不参与实际推理。
历史回放(backfill)功能:
# 预览历史文档的 REM 分析结果memory rem-harness --path <file-or-dir> --grounded# 将历史分析写入 DREAMS.md(可逆)memory rem-backfill --path <file-or-dir># 将历史分析暂存到短期记忆池memory rem-backfill --path <file-or-dir> --stage-short-term# 回滚已写入的 REM 分析memory rem-backfill --rollback
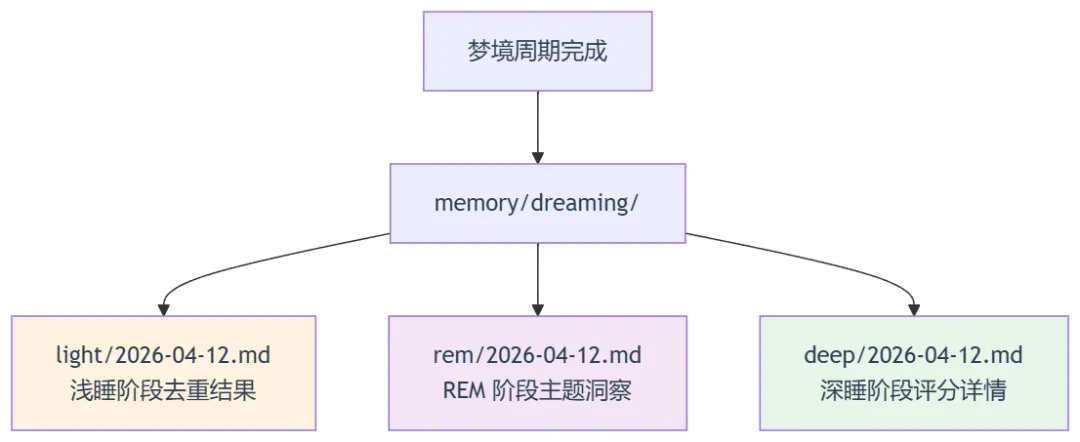
4.2 阶段报告文件
除了 DREAMS.md,系统还会在 memory/dreaming/<phase>/YYYY-MM-DD.md 生成每个阶段的详细报告:
4.3 MEMORY.md(机器可用的长期记忆)
晋升后的记忆以结构化格式追加,供后续会话加载:
- **用户技术栈偏好** [晋升分数:0.82, 首次:2026-04-08, 最后:2026-04-12]- 前端:React + TypeScript,偏好函数组件与 Hooks- 后端:Node.js/NestJS,考虑迁移至 Go 微服务- 数据库:PostgreSQL 主库,Redis 缓存层,评估 TiDB 分片方案
五、实操指南:调优与排错
5.1 判断晋升是否过度/不足
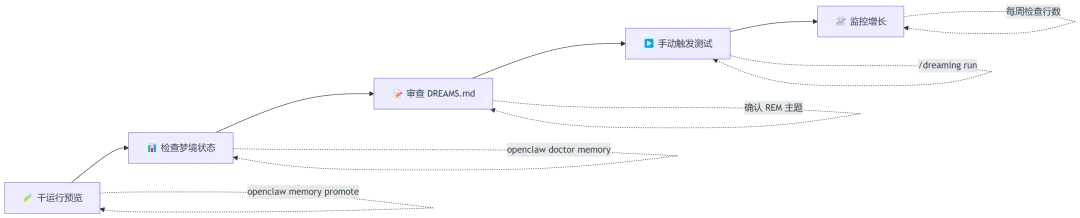
5.2 预览与调试流程
推荐的安全测试流程:
Gateway Dreams UI 功能:
显示当前启用状态 展示各阶段计数和受管 Cron 任务 显示短期、已扎根、信号、今日晋升数量 显示下次计划运行时间 可展开的梦境日记阅读器
5.3 与手动记忆管理的对比
适合启用梦境的场景:
✅ 无专职人员维护记忆文件 ✅ 会话频率高,手动整理成本大 ✅ 需要"渐进式了解用户"的伴侣型 Agent
建议禁用梦境的场景:
❌ 已有严格的手动记忆审核流程 ❌ 对记忆准确性要求极高(如医疗、法律) ❌ 需要区分战略决策与战术细节(当前评分模型无法区分)
替代方案:混合模式——启用梦境但延长运行频率(如 0 0 * * 0 每周一次),仅捕获最强信号,人工审核后手动写入 MEMORY.md。
六、架构定位:梦境 vs 其他记忆系统
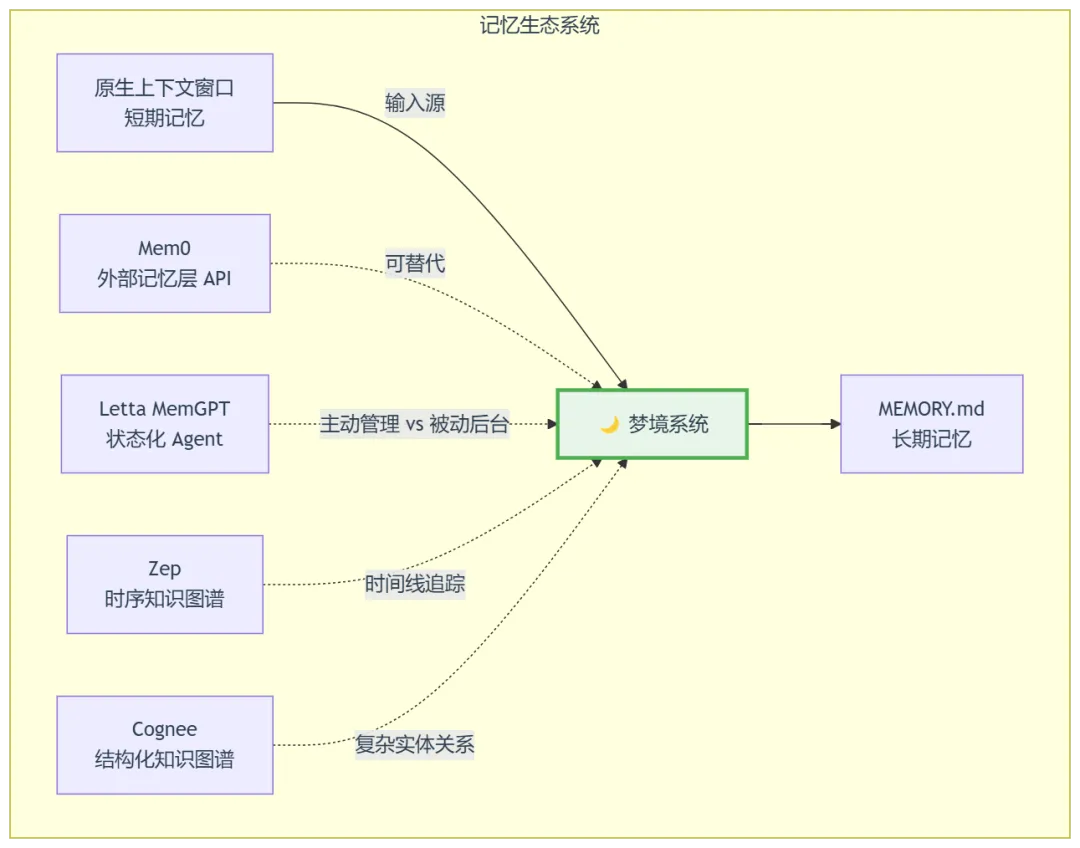
核心差异:梦境是整合机制而非存储层,它运行在现有架构之上,解决"什么值得记住"的筛选问题。
七、总结与最佳实践
7.1 核心要点回顾
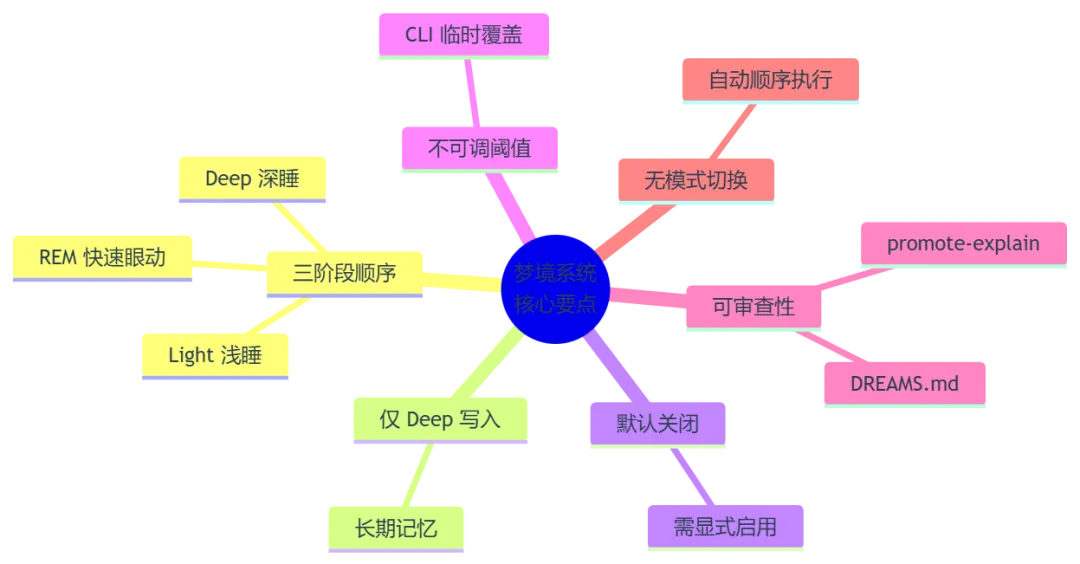
7.2 快速检查清单
已备份现有 MEMORY.md( cp MEMORY.md MEMORY.md.backup)已在配置中设置 enabled: true已运行 openclaw memory status --deep确认状态正常已查看 openclaw doctor memory确认 Cron 任务已注册已运行一次 openclaw memory promote预览效果已检查 DREAMS.md 输出是否符合预期
📌 最后提醒:梦境系统是一个需要耐心调优的功能。建议从小规模测试开始,逐步调整至最适合你工作流的配置。记住,最好的 AI 记忆管理是让你感觉不到它的存在,却能在关键时刻提供恰到好处的上下文支持。
