 夜雨聆风
夜雨聆风
目标只有一个:
先验证你的 Mac 能否稳定、干净、可回退地跑本地模型。
你这一步不要装 OpenClaw,也不要装多个模型。Ollama 官方支持 macOS Apple Silicon,Mac 上原生用 Metal,不需要额外 GPU 配置;macOS 下载安装要求是 macOS 14 Sonoma 或更高。
第一阶段的成功标准
做完这一步,你只检查 4 件事:
能正常安装 Ollama
能成功拉起一个模型并对话
连续测试十几轮不崩
不满意时能删模型,必要时能完整卸载
Ollama 官方 CLI 提供了运行、列出、停止、删除模型这些命令;默认本地 API 在 http://localhost:11434/api。
你这一阶段的推荐选择
先装哪个模型
我建议你先用:
ollama run qwen3:4bOllama 官方库里有 qwen3:4b,这是个适合先做本机测试的小规格起点。
为什么先用它:
体量比 8B 更稳
更适合你 16GB 内存先试水
中文日常体验通常更容易接受
出问题时排查更简单
先不要上 8B。
等 4B 稳了,再决定要不要升到 qwen3.5:4b或 8B。Ollama 官方库里也有 qwen3.5:4b。
第一阶段:详细执行步骤
第 0 步:先做准备
0.1 检查 macOS 版本
在 Mac 左上角:
苹果菜单 → 关于本机
确认系统是 macOS 14 Sonoma 或更高。Ollama 官方下载页要求如此。

0.2 留出磁盘空间
Ollama 官方提醒,模型会额外占用很多空间,可能从几十 GB 到更多,所以你至少要留出一块可用空间。第一阶段虽然只装一个小模型,但也别把磁盘压太满。
0.3 新建一个“养虾日记”文件夹
先别急着装,先建目录。你后面出问题才能回溯。
建议在桌面建一个文件夹:
OpenClaw-Shrimp-Diary里面先建两个文件:
01-安装日志.md02-测试记录.md你今天先记一条:
# 2026-04-15 第一阶段开始设备:MacBook Pro M1 Pro / 16GB目标:只安装 Ollama + Qwen 4B原则:不装 OpenClaw,不装第二个模型第 1 步:安装 Ollama
Ollama 官方在 macOS 上推荐的方式是:下载 ollama.dmg,拖到 Applications。首次启动时,它会检查 ollama命令是否在 PATH 中,如果没有,会提示创建 /usr/local/bin链接。
界面安装
打开 Ollama 官方 macOS 下载页
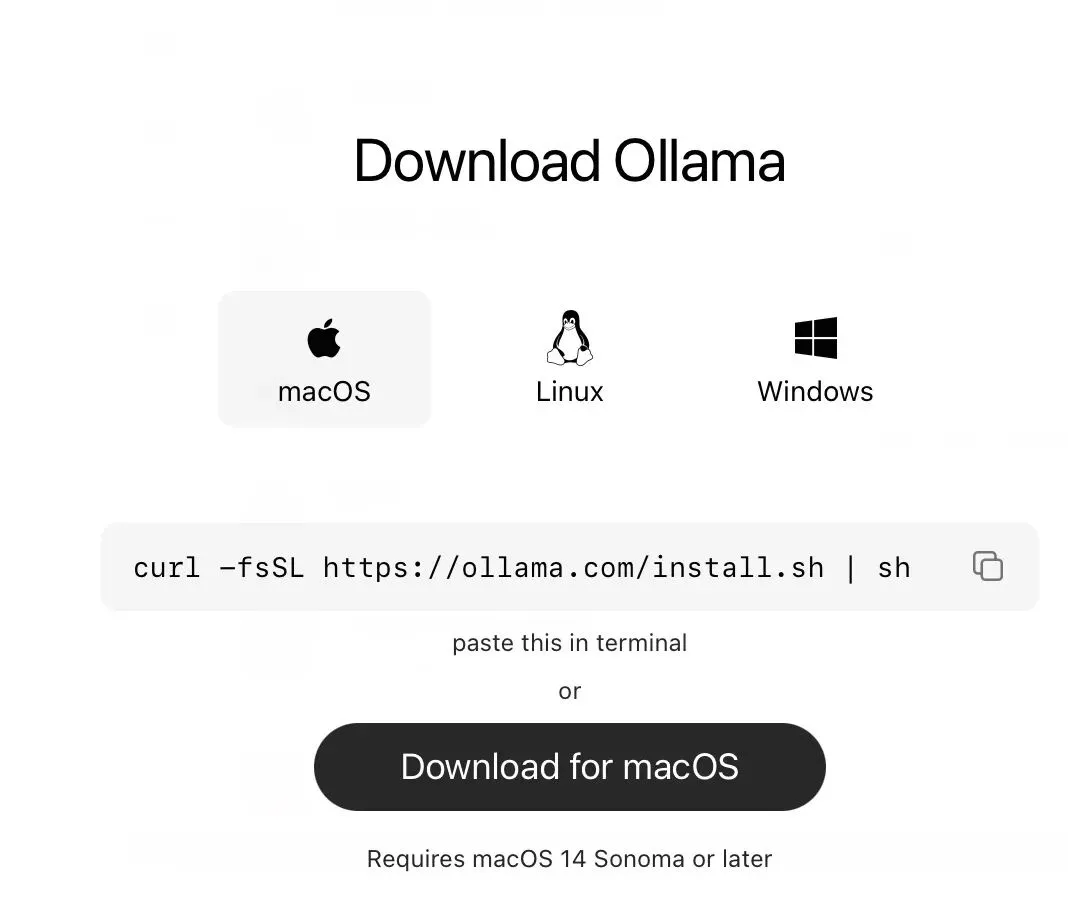
下载 macOS 安装包
双击 .dmg
把 Ollama拖到 Applications
第 2 步:确认 Ollama 装好了
打开 Terminal,输入:
ollamaOllama 官方 quickstart 说明,直接运行 ollama会打开交互菜单,可以快速进入 Run model、Launch tools 等入口。

如果这一步成功,说明:
App 装好了
CLI 已经可用
PATH 大概率正常
如果提示
command not found
先做这两件事:
退出 Terminal 重新打开
再执行一次:
ollama
如果还不行,通常是第一次启动时没有成功建立 /usr/local/bin链接。你可以重新打开 Ollama App,再看是否弹出授权提示。这个行为来自官方 macOS 文档说明。
第 3 步:拉取并运行第一个模型
现在只跑一个模型:

ollama run qwen3:4b这是官方库里的模型名。
第一次运行时,它会先下载模型,然后进入交互式对话。
你应该看到什么
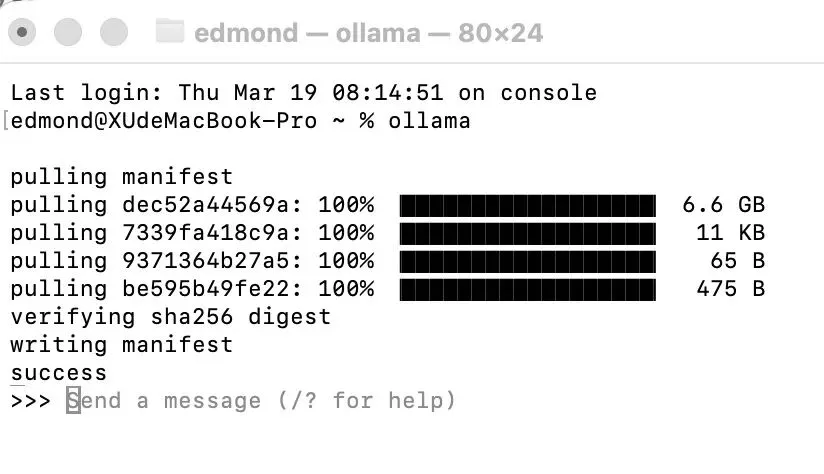
大概会发生两件事:
先下载模型
下载完成后进入聊天界面
然后你输入:
请用中文做一个自我介绍,并告诉我你适合做什么、不适合做什么。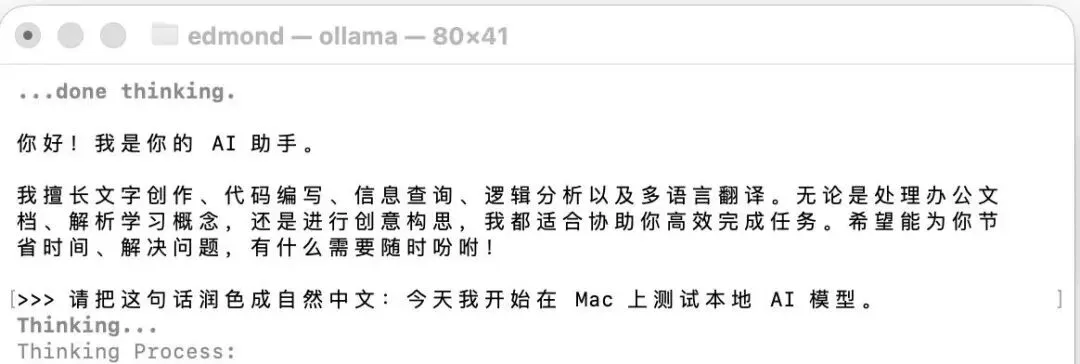
再问第二句:
请把下面这句话润色成自然中文:今天我刚开始在 Mac 上搭建本地 AI 环境。
再问第三句:
请给我一个“养虾日记”的 Markdown 模板,要简单,适合每天记录。
第四句:请用 5 条列出在 M1 Pro 16GB 上本地运行模型时要注意什么。
为什么先测这四句
因为这四句能快速测出:
中文自然度
指令跟随能力
实用性
速度是否能接受
第 4 步:做稳定性测试
请把上面的回答再压缩成更简洁的版本。

它持续输出内部过程文字,而且不是偶发,是稳定出现。
