 夜雨聆风
夜雨聆风最近有很多关于名人的skills,比如费曼、芒格、马斯克、乔布斯、张雪峰等等。这些skills通过一些结构化的认知框架来尝试全方面重塑这个人的认知、讲话逻辑和风格等等,效果非常不错,仿佛提取了这个人的灵魂在和你对话。

张雪峰.skills
那么这套逻辑是否能用LLM来模拟每个人呢?
假设我们将自己的一些生平写的文字、说的话全部去总结,得到一堆类似rubrics或者画像的东西来描述我们,LLM在接收到这些信息的时候,它能否尽可能的重现我们的思维?
如果考虑说话风格肯定是可以的,毕竟rubrics里可以记录个人的口癖以及擅长的领域等等,但实际测试会发现,现有的LLM是无法很好模拟用户的,它模拟的更像是一群人里偏正向的中位数。
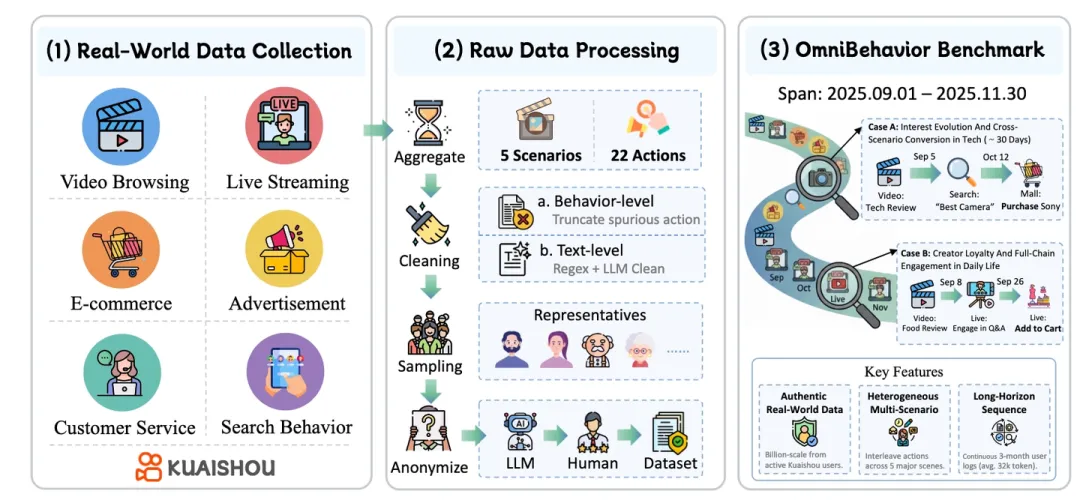
《Towards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces》[1] 这篇论文基于快手真实数据,有刷视频、直播等场景,通过搜索、点赞、分享等异构操作进行交互,汇总了200个用户在3个月之内的完整交互轨迹和精确时间戳。
其主要考察的是在这种真实且复杂的环境下,给定用户的个人资料、历史行为序列以及特定场景描述的上下文,LLM能否很准确的预测用户行为。
很遗憾,结果是不行的,LLM很难根据一段个人描述就推断出用户下一步可能做什么,这里的信息不足以模型收敛用户的决策空间。
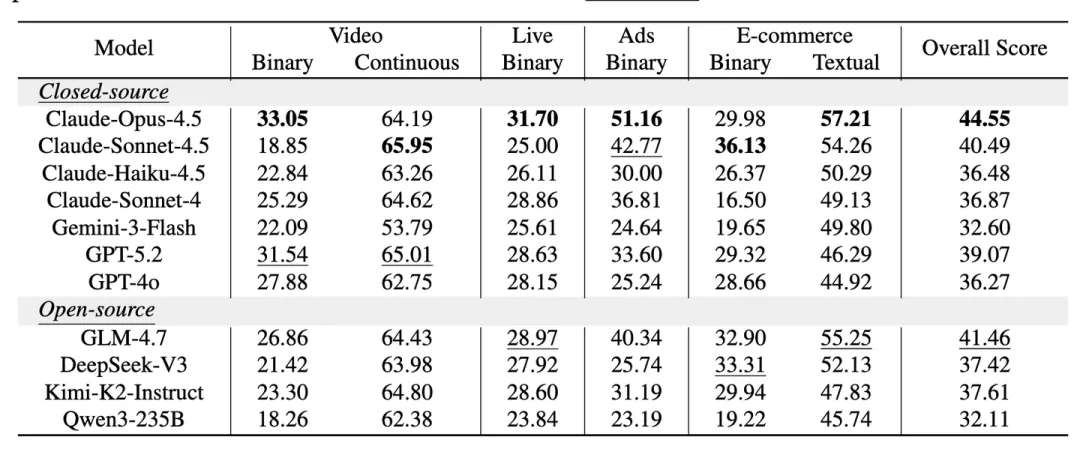
更有趣的是,LLM模拟的用户给出正向反馈的比例是非常高的,比如夸奖助手或者点赞等行为相较于真实用户更高。在真实场景下我们观察到的用户一般都是暴躁老哥/老姐,动不动就是点踩开喷,你根本猜不到模型到底怎么惹ta了。实际预测用户下一步行为准确率很低
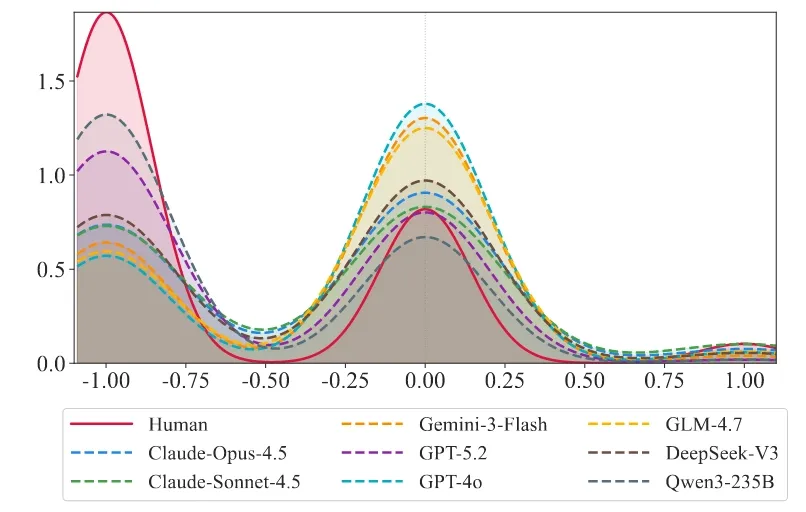
预测和真实用户回复的情感偏向(-1是负向)
还有很多的paper也论证了尝试用LLM去模拟用户,其实际效果和真实用户的差距还是非常大的,并且缺少scale趋势——即一般意义上智商越强的模型,在模拟用户这一块并不一定能取得更好的效果,这是一个不得不承认的扎心事实 [2]。
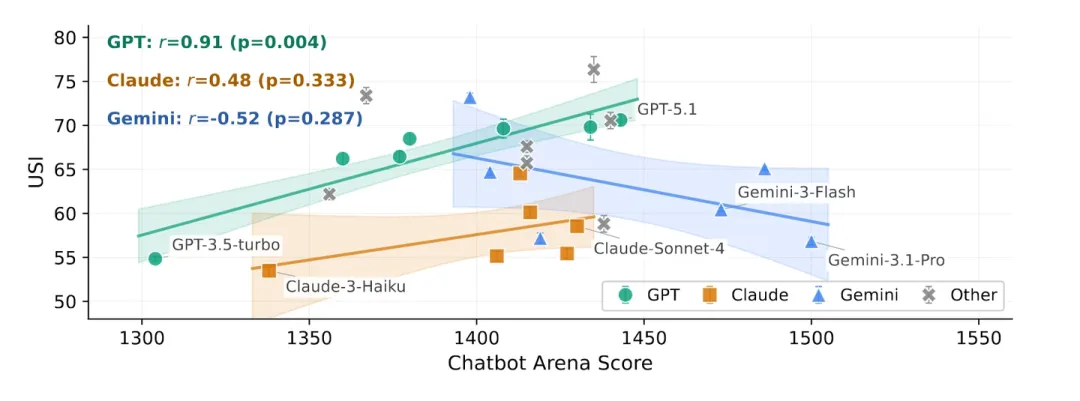
用户模拟评分和模型Arena评分相关性
是什么导致了用户模拟在给定足够的画像和交互的情况下也很难预测到用户下一步可能做什么?
Anthropic 在2月发表了一篇名为《The Persona Selection Model》的blog,里面核心观点谈到:LLM在预训练期间,其实已经内化了各种人格。

直观理解这一点,在预训练阶段模型通过next token prediction的方式进行优化,要更准确的预测小说里的下一段话,就必须理解里面的人物在历史语料中是什么样的人,得知道不同角色在这个场景下为什么会这么说。比如它得知道,曹操说话会带着权谋和试探,林黛玉会敏感又带点锋利,孙悟空遇事第一反应是反抗和出手,不是在猜下一个词,而是在猜“这个人接下来会怎么说、怎么做”。
参考一下花叔的总结:
"""几万亿token训练下来,模型内部形成了一个巨大的人格空间。这里解释一下「空间」是什么意思。神经网络的内部状态可以用一组数字表示,每个数字是一个维度。你可以把它想象成一个极高维度的坐标系。每一个位置对应一种人格配置。「善良内向的中学生」在一个位置,「傲慢的英国教授」在另一个位置。位置之间是连续的,不是离散的列表。临近的位置对应相似但不完全相同的人格。后训练来了。RLHF(基于人类反馈的强化学习)说「你现在是一个有帮助的、诚实的、无害的AI助手」,模型就在这个巨大空间里找到一个最匹配的区域,锚定并微调。论文里的原话:「与AI助手的交互,本质上是与一个LLM生成的故事中的角色进行交互。」这解释了我的第一个困惑2024年卡林实验里发生了什么,一下子就清楚了。第一种方式(「按卡林风格写」)直接激活了模型内部已有的「卡林」persona(人格),一个完整的、有内在一致性的角色。模型在预训练中见过大量卡林的材料,已经有了一个相当丰满的卡林位置。第二种方式(先描述风格再创作)把一个完整的角色拆成了碎片化的特征列表,比如「讽刺性强」「喜欢用重复」「关注社会底层」,然后让AI用约束条件去拼凑。从一个活的角色退化成了一堆死的规则。粗糙的蒸馏在压缩模型已有的信息,结果当然不如直接激活。
"""
理解了这一点,其实也能更好的解释为什么这些名人skills能提取出这些人的核心特征,并且模仿的惟妙惟肖,而当我们把用户的特征提取出来喂给模型时,LLM却无法定位到这个真实的用户在人格空间里的定位如何。
核心就在于在大量互联网语料中,关于名人的token是大量存在的,在pre-train阶段模型早已学习到了其画像,进而在使用的时候能激活。但普通用户的对话历史、个人信息等完全没有参与进来,导致一个是纯粹in-context而一个是参数知识+context激活,两者的区别一眼可见。
总结
这些结论最大的启示或许是,LLM并不像想象中的万能,因为它无法模仿我们,我们有我们自己的思想和语言;
但LLM又是有足够潜力的,只是它在学习的过程中还没见过我们,当我们的信息足够多时,或许会有新的涌现现象。
[1] Towards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces
[2] Mind the Sim2Real Gap in User Simulation for Agentic Tasks
[3] The Persona Selection Model
