 夜雨聆风
夜雨聆风
如果你对人工智能、神经网络这些听起来高大上的词汇感到好奇,但又觉得它们神秘而遥远。今天,我们就用最简单的语言,一步步揭开神经网络的面纱,看看它到底是如何工作的。
一、神经网络是什么?
首先,不要被“神经网络”这个名字吓到。它听起来像是机器有了“神经”,能像人一样思考,但实际上,它只是一套复杂的数学计算结构。你可以把它想象成一个巨大的、可调节的“计算器”,通过大量的乘法和加法运算,从数据中学习规律,最终做出预测或决策。
举个例子,假设你是一名气象预报员,要根据今天的温度、湿度、风速来判断明天是否会下雨。你可能会根据经验给每个因素赋予不同的“重要性”:比如湿度影响最大,温度其次,风速稍弱。神经网络中的“神经元”就在做类似的事情,只不过它用数字来精确表示这些“重要性”。
二、一个神经元:一道“加权求和”的算术题
神经网络的基本单位是“神经元”。它的计算过程可以分解为四步,我们用天气预测的例子来说明:
第一步:加权
每个输入(比如温度、湿度、风速)都乘以一个对应的“权重”(weight)。
权重就是这个因素的重要程度。比如:
温度权重:-0.02(温度越高,越不容易下雨) 湿度权重:0.08(湿度越高,越容易下雨) 风速权重:0.03(风速越大,稍容易下雨)
假设今天的数据是:温度30°C,湿度85%,风速12km/h,那么:
温度的贡献:30 × (-0.02) = -0.6 湿度的贡献:85 × 0.08 = 6.8 风速的贡献:12 × 0.03 = 0.36
第二步:求和
把这些贡献值加起来:-0.6 + 6.8 + 0.36 = 6.56
第三步:加偏置
偏置(bias)是一个基准值,可以理解为“默认倾向”。比如某地区本身就多雨,即使各因素一般,下雨概率也较高。
假设偏置是-3.0: 6.56 + (-3.0) = 3.56
第四步:激活函数
如果没有这一步,不管叠加多少层,神经网络都只能表达简单的线性关系(比如直线)。但现实世界是复杂的、非线性的(比如曲线)。激活函数的作用就是引入“非线性”,让网络能处理更复杂的问题。
最常用的激活函数是ReLU,它的规则很简单:
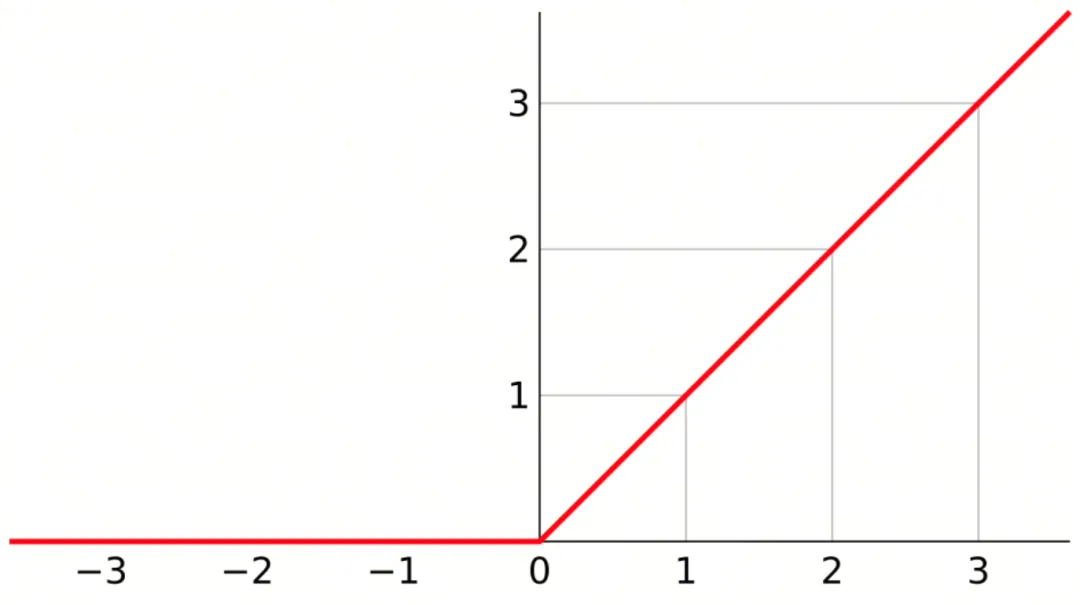
如果输入大于0,就原样输出; 如果输入小于等于0,就输出0。
在我们的例子中:ReLU(3.56) = 3.56
最终,这个神经元的输出是3.56。你可以把它理解为“下雨的可能性较高”。
三、从“一个神经元”到“一层神经元”
单个神经元只能捕捉一种规律,比如“湿度高易下雨”。但实际场景中,规律往往是多样的:
高温高湿易有雷阵雨 风速突变可能意味着冷锋过境 温度骤降且湿度上升可能预示降雨
因此,我们需要多个神经元并行工作。就像同时有多个气象预报员,同时看同一组数据(温度、湿度、风速),但每个气象预报员用不同的方式计算(权重和偏置不同),从而提取不同的信号。
举个例子:
神经元A(侧重湿度):输出3.56 神经元B(综合温度和风速):输出1.92
这一层的输出就是一组数字:[3.56, 1.92]。
四、多层网络
单层神经元的表达能力仍然有限。真正的威力来自于多层叠加,就像工厂的流水线:
第一层提取基础特征(比如边缘、纹理) 第二层组合这些特征,形成更复杂的模式(比如形状) 第三层进一步组合,最终做出判断(比如识别物体)
回到我们的例子,假设第一层输出[3.56, 1.92],第二层(输出层)的神经元会综合这两个信号,给出最终判断:
输入:[3.56, 1.92] 权重:[0.4, 0.6],偏置:-2.5 计算:3.56×0.4 + 1.92×0.6 + (-2.5) = 0.076 激活:ReLU(0.076) = 0.076(下雨可能性较低)
为什么第一层认为湿度高(3.56),但最终输出却很低(0.076)?
因为输出层综合考虑了所有信号,可能发现其他因素(如温度、风速)的加权结果不足以支持高概率下雨的结论。
五、激活函数:让网络从“直线”走向“曲线”
为什么激活函数这么重要?想象一下,如果没有激活函数,无论叠加多少层,整个网络都等价于一次线性变换(输入乘以某个常数)。而现实问题(如图像识别、自然语言处理)往往是非线性的,激活函数正是通过“掰弯”线性关系,使网络能够拟合复杂的曲线。
ReLU因其简单高效成为最常用的激活函数之一。它像一个“开关”:正数信号原样通过,负数信号直接归零。这种“稀疏激活”的特性让网络更容易训练,也更具表达力。
六、参数从哪来?机器自己“学习”得到的
你可能会问:那些权重和偏置(比如-0.02、0.08、-3.0)是怎么来的?
答案是:它们不是人工设定的,而是通过“训练”从数据中学到的。
训练过程大致如下:
- 随机初始化
所有参数初始为随机小数值。 - 前向计算
输入数据,得到输出。 - 计算误差
比较输出与正确答案的差距。 - 反向传播
根据误差,调整每个参数,使输出更接近正确答案。 - 重复迭代
以上步骤重复数百万次,直到模型表现足够好。
这就像有成千上万个旋钮,你通过不断微调,最终让机器能准确识别猫和狗——虽然听起来不可思议,但通过优化算法(如梯度下降),计算机可以高效完成这一任务。
七、神经网络 vs. 大脑
“神经网络”这个名字来源于对生物神经元的简化模拟:
接收输入 → 生物神经元接收电信号 加权求和 → 不同突触强度不同 激活输出 → 超过阈值则“放电”
但请注意,这个类比非常粗略。人脑有约860亿神经元,每个神经元与上千个其他神经元连接,其工作机制远比“乘加运算”复杂。人工神经网络只是受此启发,本质上是一套数学计算框架,而非“人造大脑”。
八、从AlexNet到GPT-3:参数量的飞跃
2012年的AlexNet是一个里程碑式的模型,它包含约6000万个参数,错误率比之前降低了近一半。它的结构包括卷积层(提取局部特征)和全连接层(综合判断),最终在1000个类别中做出选择。
如今的大模型,如GPT-3,参数规模已达到1750亿,是AlexNet的近3000倍。但核心原理不变:仍是乘法、加法、激活函数的堆叠与组合。
九、AI的本质是数学
所谓“人工智能”,背后并没有魔法或意识,而是大量精心设计的数学运算。它的强大之处在于,通过简单的操作(乘加)与大规模的组合,竟能实现图像识别、语言理解等复杂任务。
但这不意味着它在“思考”。它只是在计算——高效、精准、可复现的计算。
