【统计分析软件SPSS】46、合并文件——添加个案本系列(基于SPSS 31版本)文章配套数据可通过百度网盘获取:链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj 提取码:mnsj
由于微信公众号已发布文章的内容及排版顺序无法二次编辑,为了方便大家后续查阅、检索,同时便于我对内容进行补充更新与完善,我会将所有已发布的推文,在个人网站上以结构化文档的形式重新整理、归档。欢迎前往查看:https://www.mizhushare.com/docs/
在数据分析工作中,我们经常会遇到多个数据文件需要整合的情况。例如:不同月份的问卷调查数据;
不同地区的销售记录;
或者多次实验的结果数据。
此时,可以使用SPSS中的【添加个案】功能,将两个或多个数据文件的个案(行数据)按对应变量进行上下拼接,从而增加数据集的样本量。
需要注意的是,要合并成功的数据文件需要具有相同的变量结构(即变量名、变量类型、长度一致),但包含的是不同的观测对象(个案)。否则会出现新增多余变量、某些变量大量缺失值等情况。
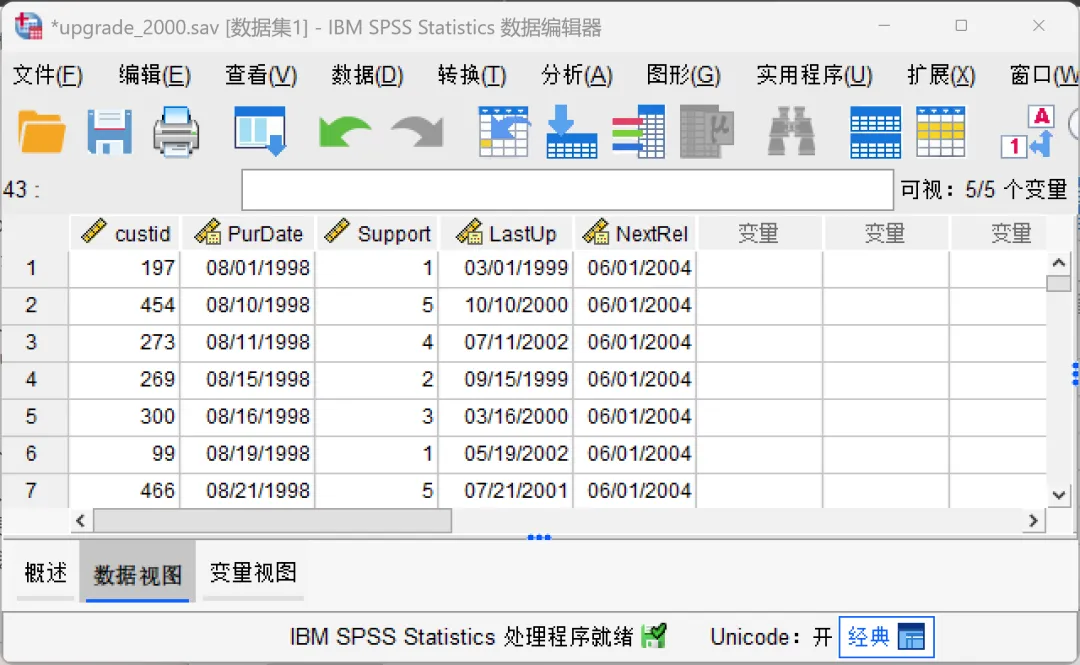
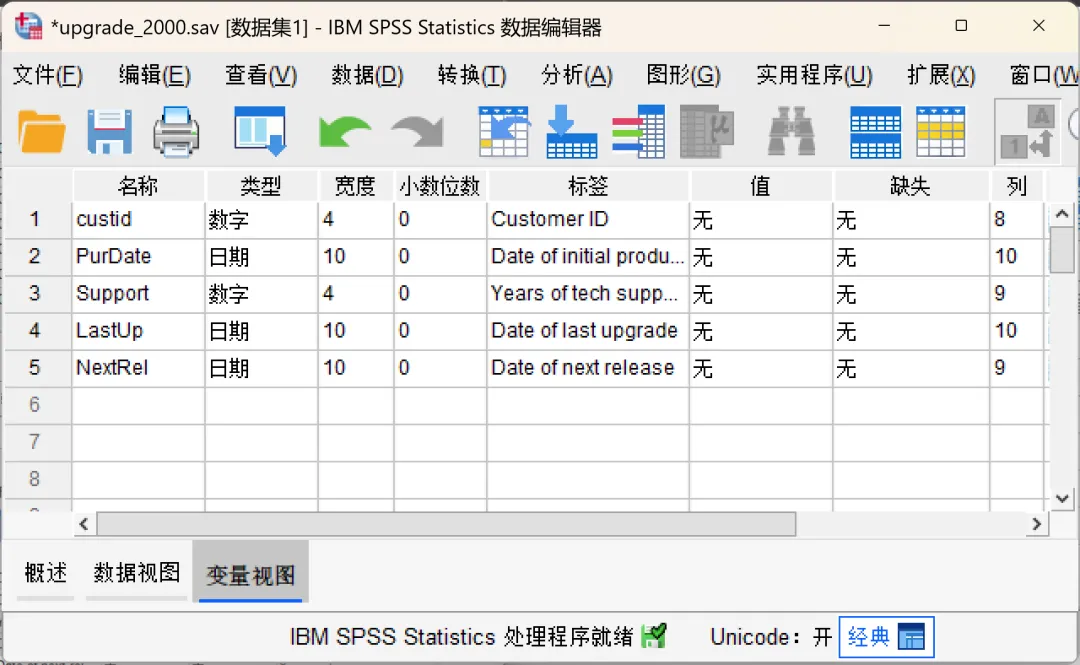
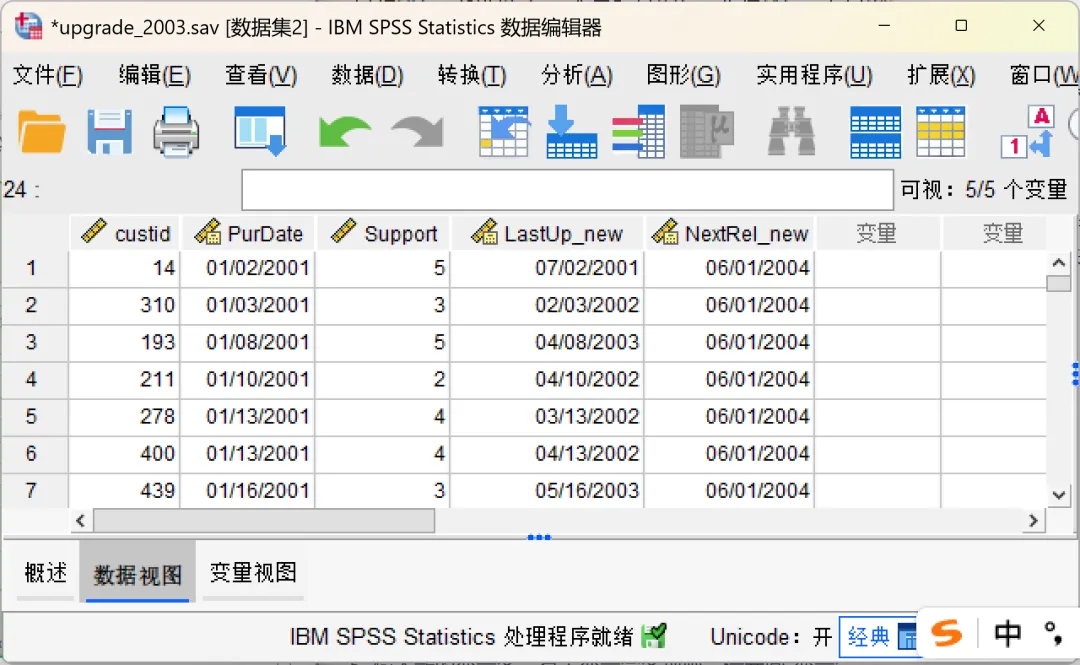
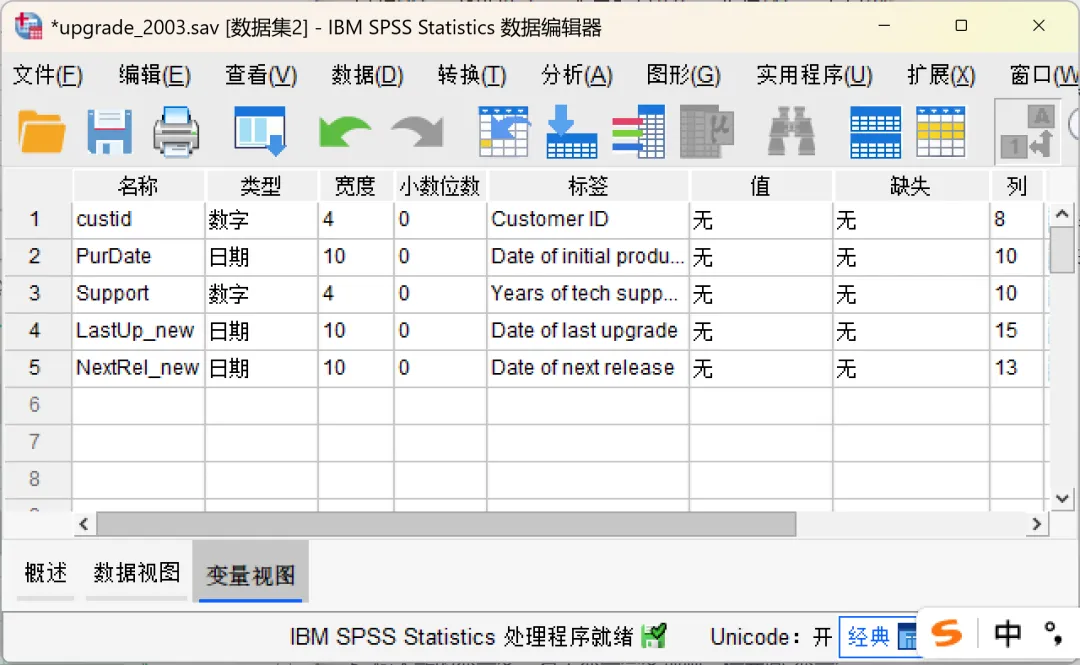
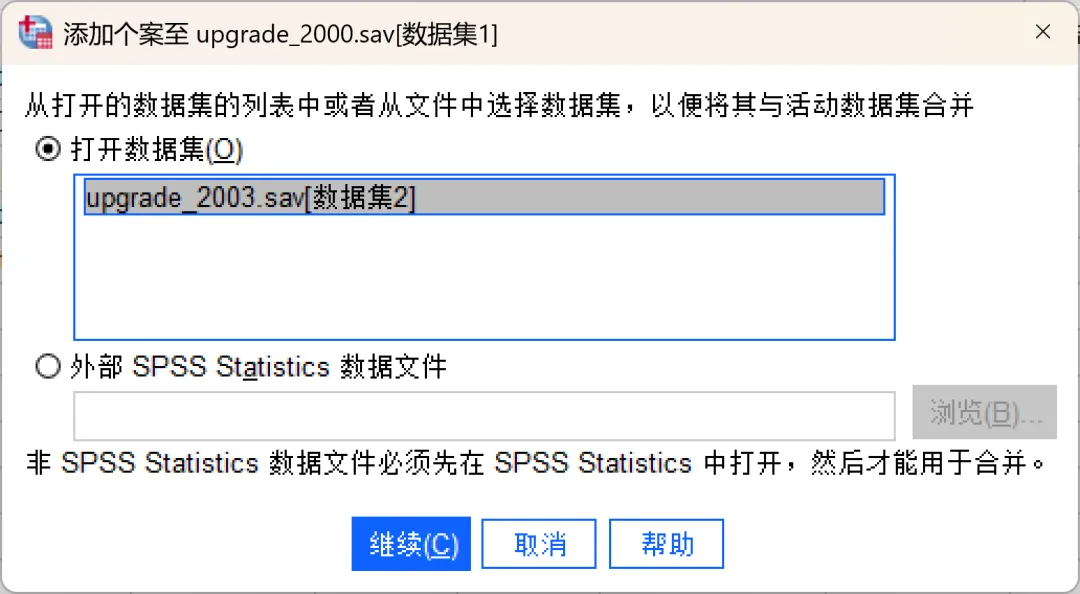
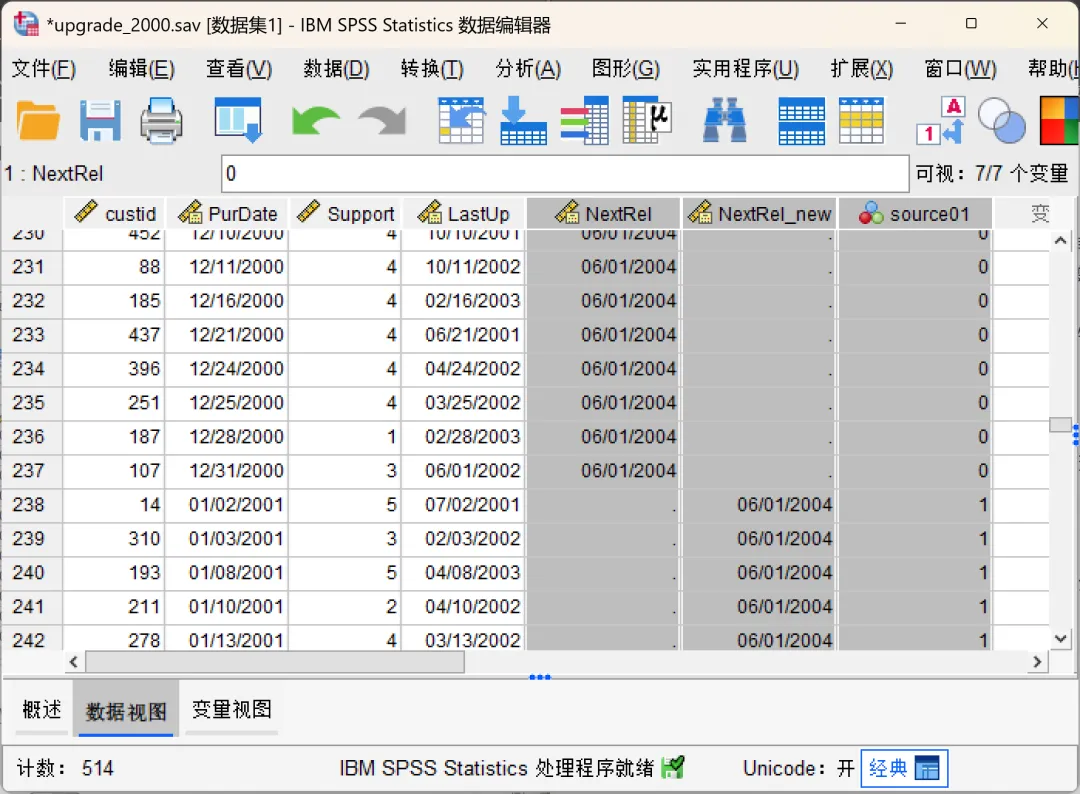
分别加载【upgrade_2000.sav】和【upgrade_2003.sav】(软件自带某软件公司用户购买升级许可的样本数据)示例数据。其中,【upgrade_2000.sav】表示「PurDate」变量值为2000年之前的数据,【upgrade_2003.sav】表示「PurDate」变量值为2000-2003年之间的数据。需要注意的是,两个示例数据均包含5个变量,其中custid(用户ID)、Support(支持年数)两个数值型变量以及PurDate(初始产品许可日期)日期类型变量名称以及数据类型一致;但是,LastUp/LastUp_new(上次升级日期)、NextRel/NextRel_new(下次发布日期)两个日期类型变量的名称不一致但是数据类型一致。打开其中一个数据文件(如upgrade_2000.sav),点击顶部菜单栏的【数据→合并文件→添加个案】,在弹出的对话框中进行设置。
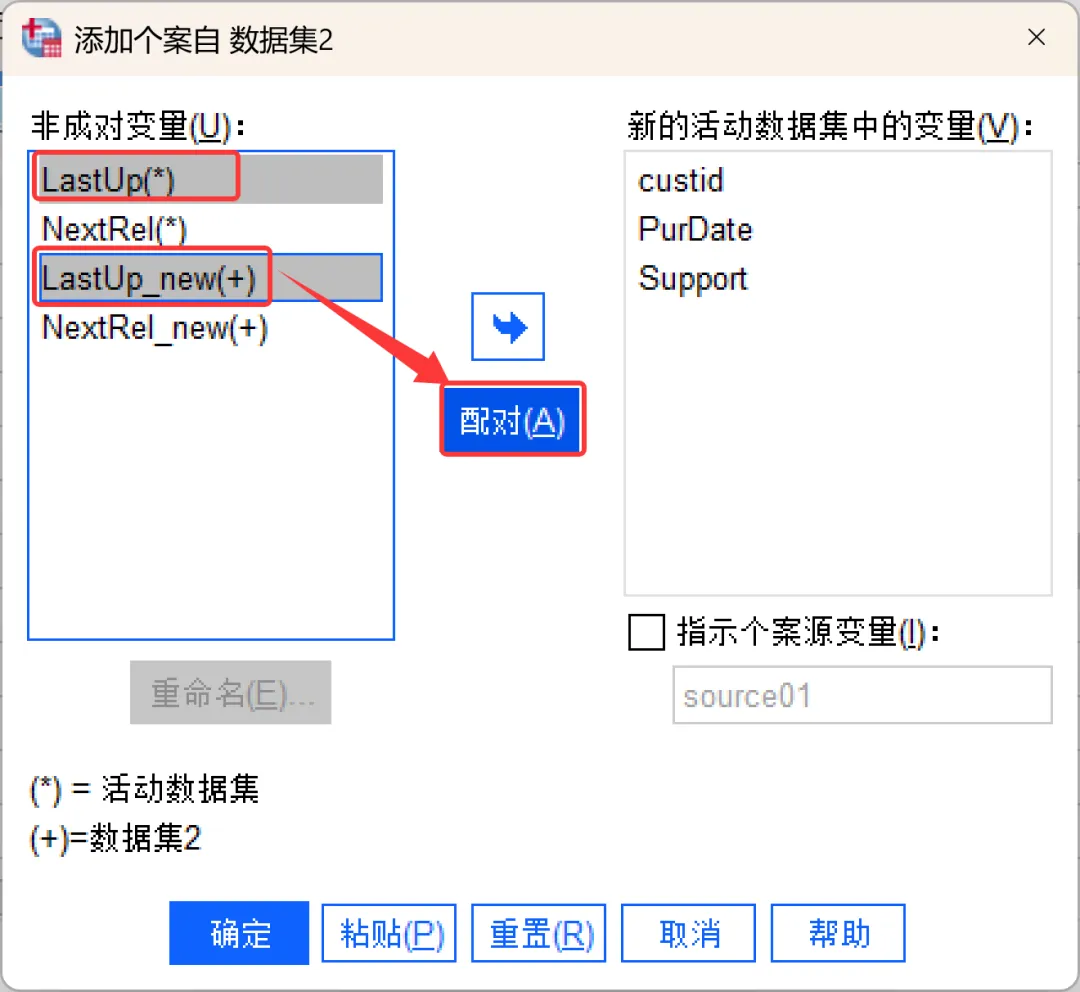
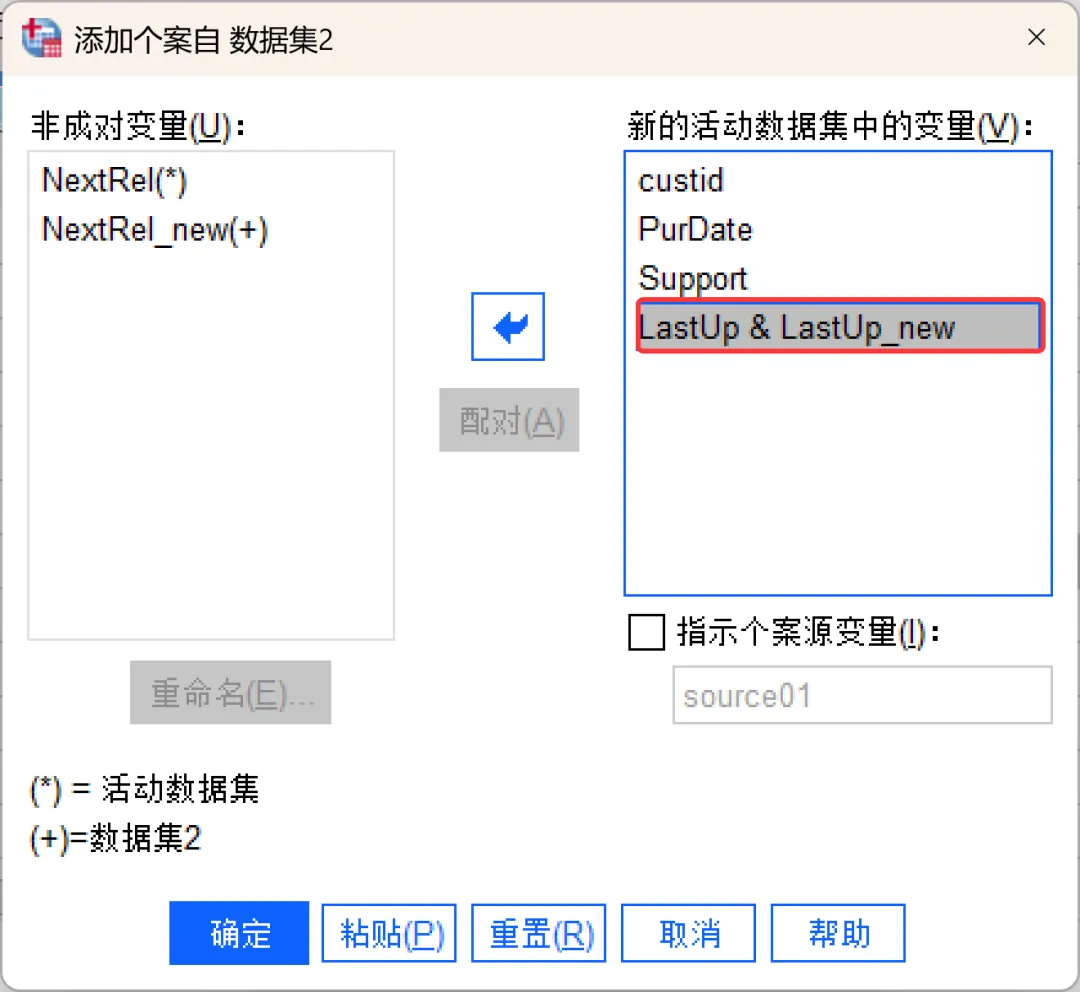
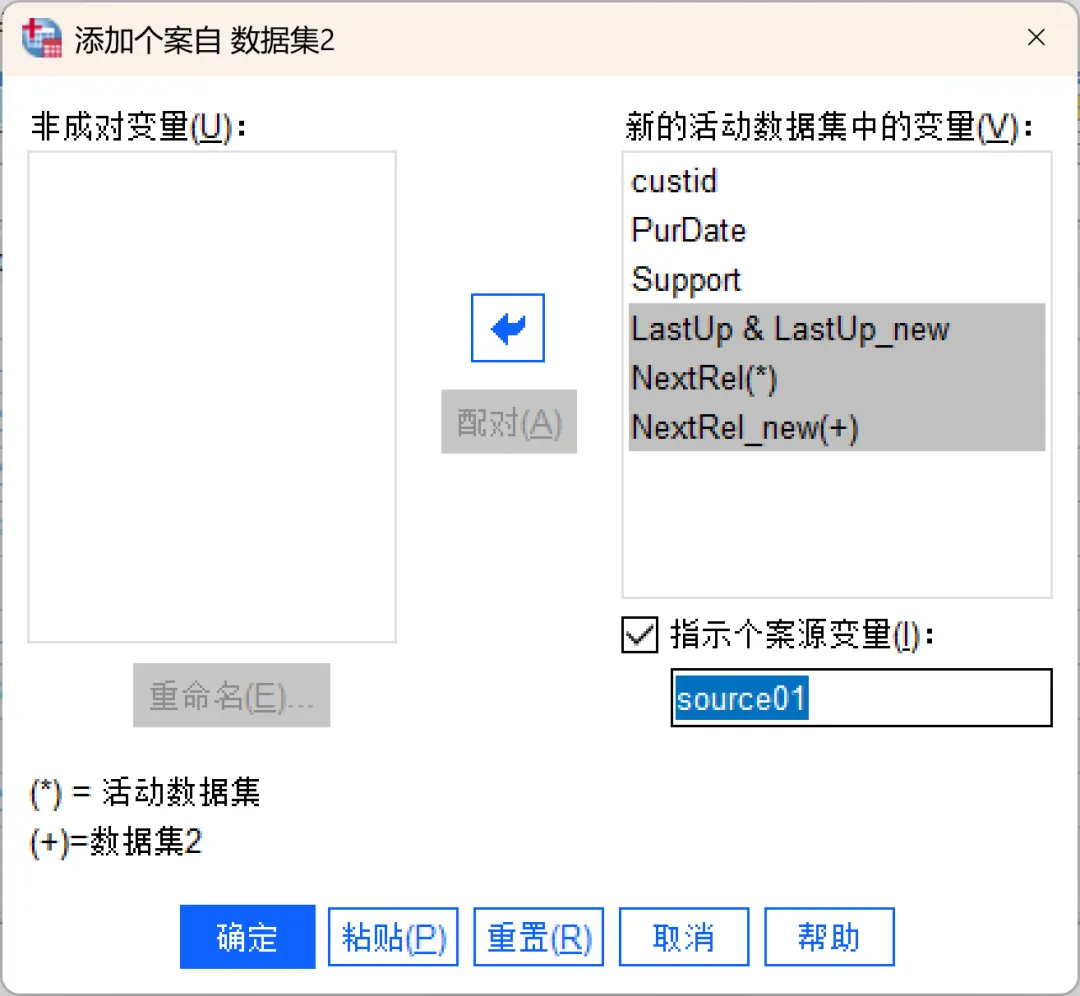
如果已打开其他数据文件,系统默认选中「打开数据集」选项,在列表中选择要合并的数据即可;如果未打开其他数据文件,系统默认选中「外部SPSS数据文件」选项,点击「浏览」,找到并选中另一个待合并文件即可,然后点击继续。选择数据后弹出该对话框,显示两个文件的变量匹配情况,其中:①、新的活动数据集中的变量:默认显示两个文件中「变量名+类型都匹配」的变量(比如示例中的custid、PurDate、Support),这些变量会保留在合并后的文件中。如果不希望某些变量包含在合并后的文件中,可以从列表中将其移除。②、非成对变量:显示不匹配的变量(名称不同或类型不一致的变量),其中,「*」表示活动数据集变量,「+」表示要合并的文件变量。如果是「变量名不同但含义相同」的情况(示例中的LastUp/LastUp_new),可以按住 Ctrl 键同时选中两个变量,点击「配对」按钮,就可以将它们合并为同一个变量(以活动数据集的变量名为准)。其他情况下,如果需要保留变量,可以选中该变量后点击箭头按钮将其添加到结果文件中,后续再进行处理。③、指示个案源变量:勾选后会在合并后新增一个叫「source01」(可自定义名称)的变量,其中,0代表来自原活动数据集,1代表来自外部文件(要合并的文件),方便后续核对数据来源。建议勾选。④、重命名:可以在将变量从「非成对变量」列表移至「新的活动数据集中的变量」列表之前,对来自活动数据集或其他数据集的变量进行重命名。需要注意的是,活动数据集中任何现有的字典信息(变量和值标签、用户缺失值、显示格式)都将应用到合并后的数据文件中。如果某个变量在活动数据集中的字典信息未定义,则使用来自另一个数据集的字典信息。如果活动数据集为某个变量包含了任何已定义的值标签或用户缺失值,则来自另一个数据集中该变量的任何额外值标签或用户缺失值将被忽略。设置完成后点击确定,SPSS会自动完成合并。此时查看数据视图,会发现个案数已经变成两个文件的总和。其中:合并完成后,切记保存数据。

 夜雨聆风
夜雨聆风