 夜雨聆风
夜雨聆风
引言
医学影像基础模型的发展正在改变临床诊断的范式。然而,与自然语言处理和计算机视觉领域的基础模型相比,医学影像AI面临着一个核心瓶颈「数据规模与多样性的严重不足」。当前多数公开医学数据集仅包含数千张图像,这与自然图像领域数十亿样本的训练规模形成了数量级的差距。
近期发表在arXiv上的一项里程碑式研究「Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development 」,对2000年至2025年间发布的1000余个开放医学影像数据集进行了全面系统的梳理与分析。这项研究由上海人工智能实验室等40余家国际顶尖机构联合完成,首次从数据规模、模态分布、任务类型、解剖等多维度揭示了医学影像数据集的现状、局限与整合路径,为医学基础模型的发展提供了重要的数据基础。
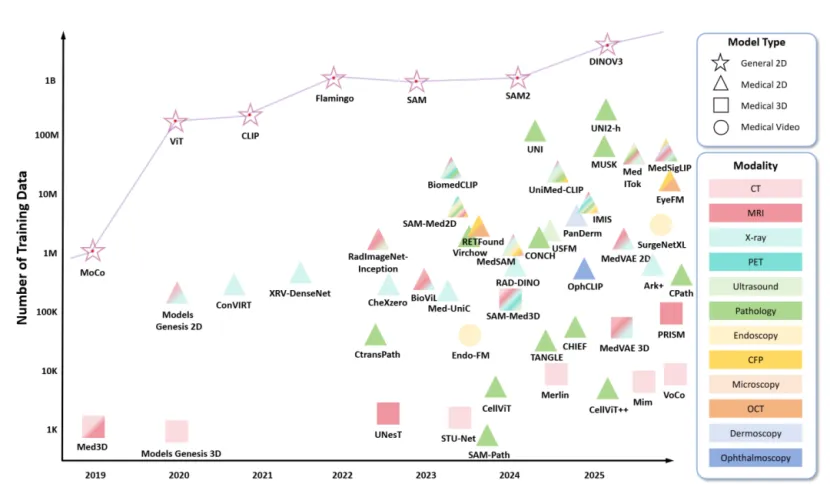
图 1:医学基础模型和通用领域基础模型的演变
研究背景与核心问题
医学影像数据集的构建面临三大核心挑战:首先,医学图像采集需要专业设备和临床专家参与,成本高昂;其次,数据标注依赖专业医师,耗时耗力;最后,伦理审查和隐私保护增加了数据共享的复杂度。这些因素导致当前数据集呈现高度碎片化的特征——数据分散在孤立的、范围狭窄的集合中,难以支撑大规模基础模型的训练需求。
该研究团队指出,数据集整合是突破这一困境的关键策略。通过系统性地融合具有相似模态、解剖区域或任务的小规模数据集,可以构建更大、更均衡的训练资源。然而,现有的整合工作缺乏全局视野和标准化框架,往往聚焦于特定成像类型或器官系统,难以系统性地解决数据碎片化问题。
方法
数据集收集与分类框架
研究团队从The Cancer Imaging Archive (TCIA)、Grand Challenge等主要公开数据仓库中系统收集数据集,经过去重、人工验证和元数据标准化后,建立了涵盖1000余个数据集的综合目录。
为系统组织这一庞大的数据集合,研究采用了层级化的分类法:按成像维度(2D、3D、视频)、成像模态(CT、MRI、X光、病理等)、任务类型和解剖区域进行分类。这一分类法与基础模型训练需求高度契合:成像维度影响模型架构设计,模态反映成像物理特性和临床用途,任务决定监督信号,而解剖多样性则塑造临床泛化能力。
元数据驱动的融合范式(MDFP)
针对数据集碎片化问题,研究提出了创新性的元数据驱动融合范式(Metadata-Driven Fusion Paradigm, MDFP),这是一个系统化的四阶段工作流程(见图2):
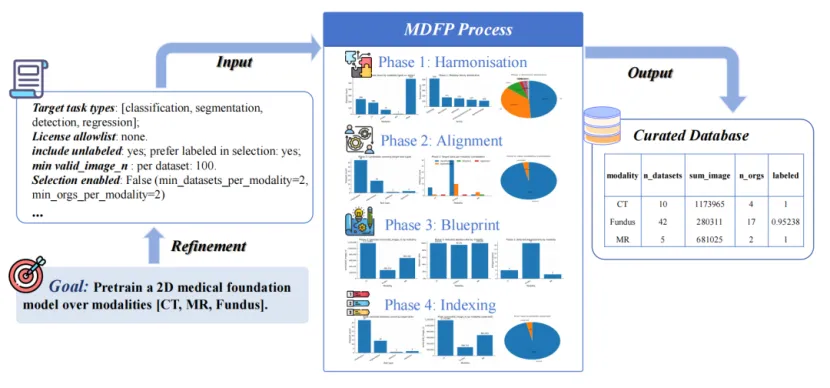
图 2:元数据驱动的融合范式(MDFP)四阶段工作流程
阶段一:元数据协调化。通过将数据集描述符映射到统一医学语言系统(UMLS)和医学主题词表(MeSH)等权威医学术语体系,建立了标准化的元数据模式。
阶段二:语义对齐。将抽象的机器学习任务映射到具体的临床意义,使数据集更贴近实际临床应用需求。
阶段三:融合蓝图设计。基于协调化的元数据,按成像模态、临床任务和解剖覆盖范围进行数据集分组和分类。
阶段四:数据集索引与社区共享。创建公开的元数据索引和可视化工具,支持端到端的数据集整合。
MDFP的核心优势在于主要操作元数据而非原始像素,这显著降低了处理开销和隐私风险,提高了可重现性和可审计性。
结果
数据集增长趋势与规模分析
研究揭示了医学影像数据集发布的显著时间演变特征(见图3)。从2000年到2025年,数据集发布呈现两次明显的增长拐点:
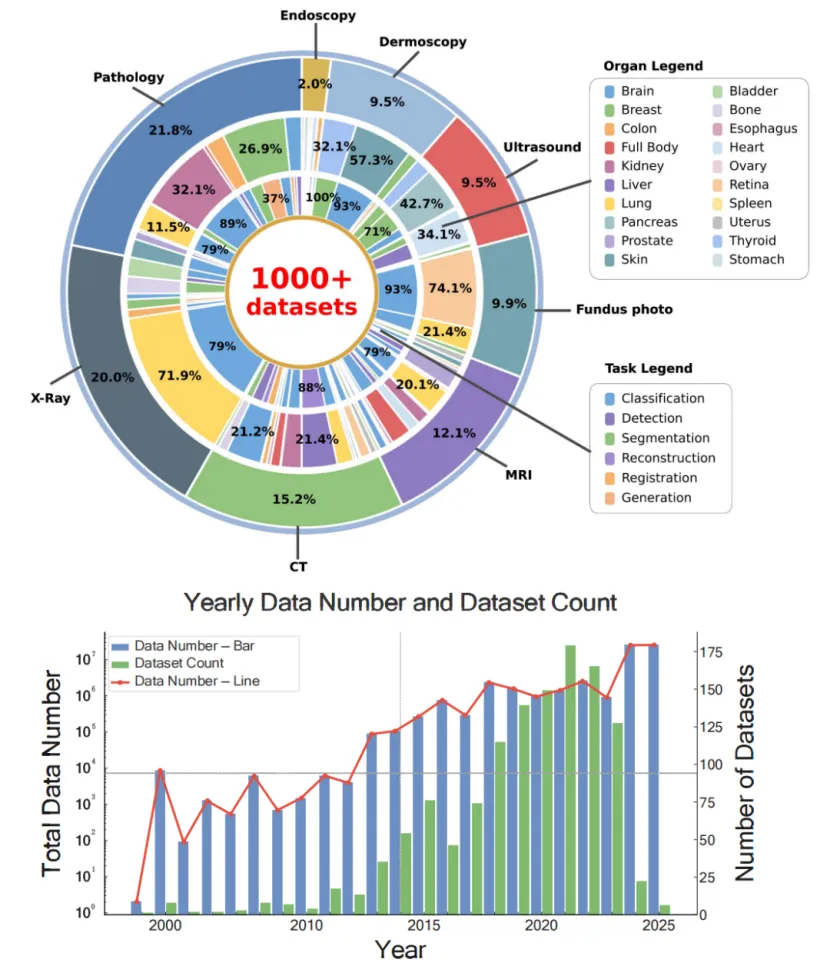
图 3:上:器官及模态分布;下:医学影像数据集增长趋势(2000-2025)
2012年后的首次激增与深度学习方法的兴起密切相关,2023年开始的第二次激增则反映了自监督学习和大规模基础模型的采用。尽管近年来出现了AbdomenAtlas(150万张2D CT图像)、CT-RATE(25692个CT扫描)等大规模数据集,医学影像数据的规模仍远小于自然图像领域,这强调了数据集整合策略的实践价值。
成像维度、模态与任务的分布特征
研究发现数据集在多个维度上存在显著的分布不均(见图4和图5):
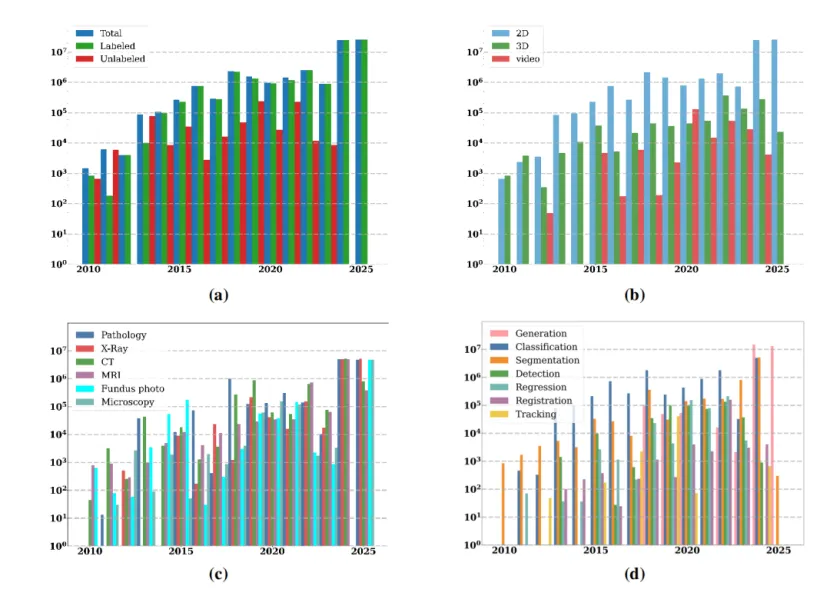
图 4:不同模态、成像维度、任务类型数据集随时间变化趋势
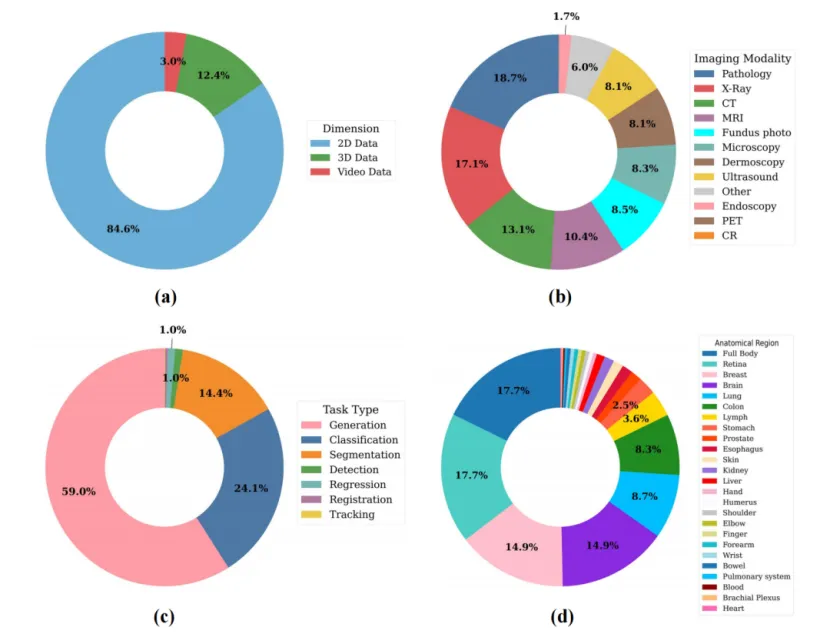
图 5:不同模态、成像维度、任务类型数据集占比
成像维度:2D图像占据主导地位(约85%),而3D体积数据(约12%)和视频数据(约3%)相对稀缺。
模态分布:病理学图像、CT和X光占据主导,而PET、超声和内窥镜等模态代表性不足。
任务分布:分割(42%)和分类(35%)任务占据主导,而新兴的视觉问答(VQA)任务极度匮乏(仅1.5%)。
解剖覆盖:脑、肺、肝等器官的数据集丰富,而罕见病、儿科影像等专业领域代表性严重不足。
结论
任务定义的局限性。现有数据集大多针对间接的下游任务(分割、分类、检测),与直接的临床诊断、治疗推荐等实际应用存在错配。重新标注的成本高昂,是未来发展的重要障碍。
多模态数据的稀缺性。整合影像模态与临床报告、基因组学的多模态医学数据极为罕见,缺乏标准化的多模态收集和标注框架,限制了跨模态推理研究。
许可与隐私约束。患者隐私法规(HIPAA、GDPR)和机构知识产权政策的双重约束,阻碍了数据集的广泛共享和协作研究。
未来展望
该研究为医学影像数据集的现状提供了迄今最全面的综述,揭示了碎片化和失衡格局对医学基础模型发展的根本制约。研究团队提出三个关键策略推动领域进步:
第一,鼓励更广泛的医学影像数据集公开发布,提升透明度和跨机构公平访问。
第二,发展合成数据生成和标注高效的学习方法,缓解隐私和数据稀缺挑战。
第三,公开发布在私有数据上训练的基础模型,使高级医学AI能力民主化。
参考文献
1.Deng Z, Tang C, Huang Z, et al. Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development. arXiv:2603.27460v1 , 2026.
2.项目地址:https://github.com/uni-medical/Project-Imaging-X
3.交互式门户:https://tchenglv520.github.io/medical-dataset-browser/

