 夜雨聆风
夜雨聆风
wuhu快报


文 | 敏 糸
在顶级影视剧组的片场,最让制片人手心冒汗的往往不是烧钱的特效,而是那些“只有一次机会”的宏大实拍。
克里斯托弗·诺兰在《信条》里为了追求真实质感,直接买下一架波音747冲向机库;Netflix在《灰影人》里为了一场布拉格街道激战,把半座城的街道翻了个底朝天。这种级别的镜头,快门按下的一瞬间就是数百万美元的燃烧。

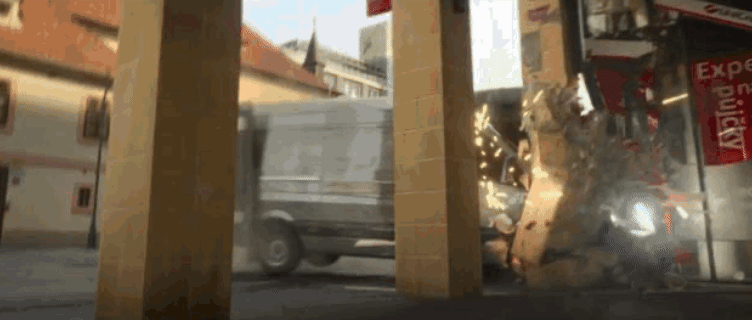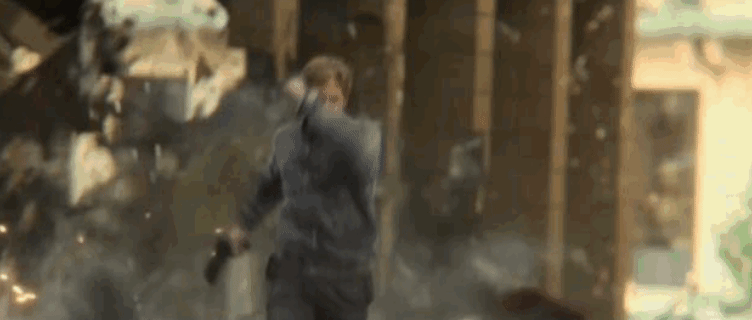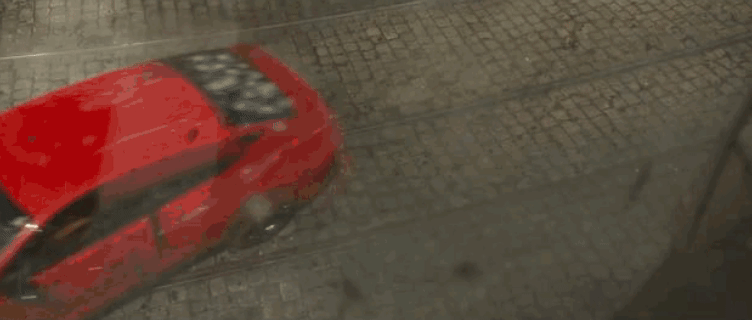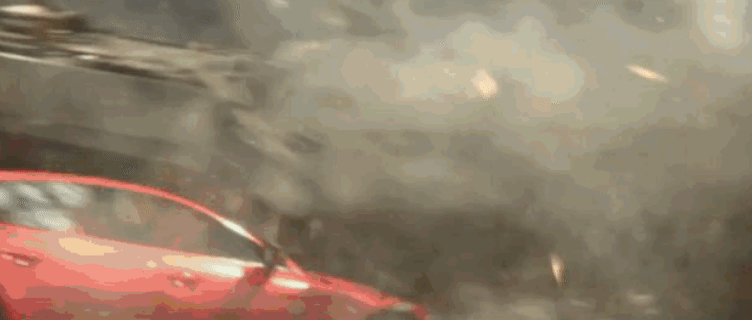
作为资方,除了默念「哈利路亚」,没别的招了——一旦实拍失败,补拍的账单足以拖垮整个项目的预算。

过去,如果实拍出了岔子,视效团队靠CGI或辅助初级的AI工具在后期“缝缝补补”。虽能勉强还原画面,但在后期修补中效果打折不少。
与其把这种决定成败的“豪赌”交给运气,或者把补救的希望寄托在外包公司,流媒体巨头Netflix(网飞)想着:干脆自己下场,投钱研发。他们瞄准了AI「脑补」技术。
最近,Netflix的研究团队联手保加利亚索非亚大学(GATE Institute),正式开源了一项名为VOID(Video Object and Interaction Deletion,视频对象与交互删除) 的全新模型。
▲ https://github.com/Netflix/void-model


视频里可以看见,AI会在消除目标物体的同时,尽量还原本身的状态,并且遵循物理规律。
这对创作者来说是狂喜,因为就好像给了AI一个魔法橡皮擦,在不借助后期特效的情况下,普通人也能达到“后期导演”的水平。

而且,VOID是全球首个能够“重写物理规律”的视频编辑框架。
意味着,在世界模型(能够理解物理规律、因果关系,并在采取实际行动前在内部“预演”未来的可能状态的AI模型)的研究推进下,AI终于从“画得像”进化到了“懂逻辑”。
或许那个“拍错不用补拍,后期一键搞定”的时代,随着VOID的开源加速到来。
01

VOID——AI界的物理课代表
光看VOID的表现,大家可能感知不明显,为了验证VOID的实战能力,还得和“友商”PK。
这是壶铃放在枕头上的测试,标绿的部分是需要消除的,枕头的凹陷变化反映AI对环境和物体的感知。
这是VOID的消除成果,它理解了枕头柔软的物理特性,修正后的画面凹陷也对应消失了。

Runway,消除了壶铃,但是残留了黑色的带子,枕头凹陷也没有消除。

ProPainter的表现则有较大瑕疵,只消除了对象,没有考虑物体和环境的交互。

第二组是汽车对撞实验。
VOID判断出了消除一辆汽车以后另一辆应该正常行驶。

友商出现了未使原车继续行驶,汽车莫名穿越,消除物体留下残影等问题。


第三组提升了多个维度,是一个跳水的男子撞倒了水上气球船的场景,考验难度大大增加了,涉及到消除人物、和气球船的互动、落水的水花处理,还有影子消除四个“命题”。

VOID四个细节都消除了,略微有点瑕疵,在水的处理上有点糊。
Runway的表现其实也不错,没有处理水花问题,但是人和影子都消除了。

另外一位表现不佳,只消除了人,没有考虑物体交互,细节处理上也没有把影子消掉。
我们来看一下最难的一组实验——多米诺骨牌推倒实验
这里开发者没有只从两端推倒,给AI一个“预判”的机会。他们设置从中间拿掉三块骨牌,这需要AI了解多米诺骨牌的玩法机制以及物理碰撞原理。

VOID的确消除了中间三块,但是很明显,倒掉的两块积木出现了变形和“滑步”,所以只能说表现一般。
但看看友商的表现,就会觉得VOID不错了。

Runway在没有消除的情况下还变了色。

另外一家,消除了,但没有按要求只消除中间三块,并且还出现了大片虚影。
这个实验的确是四组中最难的,在官网中其实还有其他实验,参照的友商也不止这么几家,这里小编只选取了最有代表性的几组,其他就不一一列出了,大家有兴趣可以去原网址比对。
链接在此:https://void-model.github.io/
感官上的差距在量化数据中得到了进一步证实。在一项针对物理真实感的“人类偏好度盲测”中,研究人员邀请大量人类评委对不同模型的生成结果进行打分。
结果显示,VOID获得了高达64.8%的人类选票,被认为是最符合现实物理逻辑的。而作为行业标杆的Runway,即便在提供了明确文本提示(告诉它“物体应该掉落”)的情况下,也仅获得了18.4%的票数。
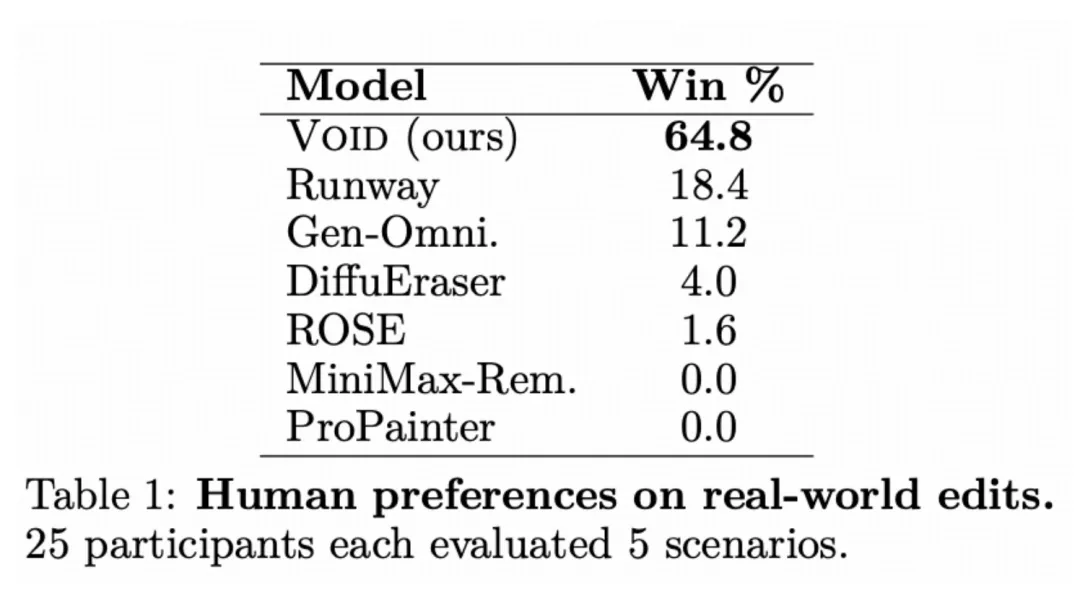
悬殊的差距印证了一个结论:在处理复杂的物理交互时,传统AI目前的优势不强。因为它们只能看到“现在有什么”,而无法处理“反事实推理”,即“如果他不在这里,这个世界接下来的动态会发生怎样的改变”。这也是为什么目前各家都在砸钱研究世界模型的原因。在目前这节AI物理课中,VOID是目前唯一的课代表。
02

VOID背后的黑科技

接下来,我们一起看看VOID背后到底有哪些黑科技?
首先,大家先了解一个基本事实,单纯的扩散模型(Diffusion Model)——广泛用于高质量图像、视频和语音生成,核心原理是模拟热力学扩散现象,通过“先加噪破坏数据,再逐步去噪还原数据”的训练方式,学习将随机噪声生成为逼真数据(如图像)的能力。(OpenAI的DALL-E(从DALL-E-2开始)、Midjourney和Google的Imagen都是)
像Sora(现在没了)或Runway这样的模型本质上是“视觉系”的,它们通过海量视频学习像素的分布规律,但由于缺乏对现实世界的逻辑建模,它们并不理解“重力”或“摩擦力”意味着什么。
VOID的核心突破在于引入了视觉语言模型(VLM)。
VLM像一个导演,不负责具体制作,但是他会严格地审视全局。(导演要求拎着袋子的手去掉,如果手没了,由于重力,表现出来的就得是自由落体)
然后动画师(Diffusion)接收到来自导演的逻辑指令,运用其强大的像素生成能力,把这段坠落的过程精准地画出来。
架构上,就变成了先将“世界知识”告诉AI,再生成指令。
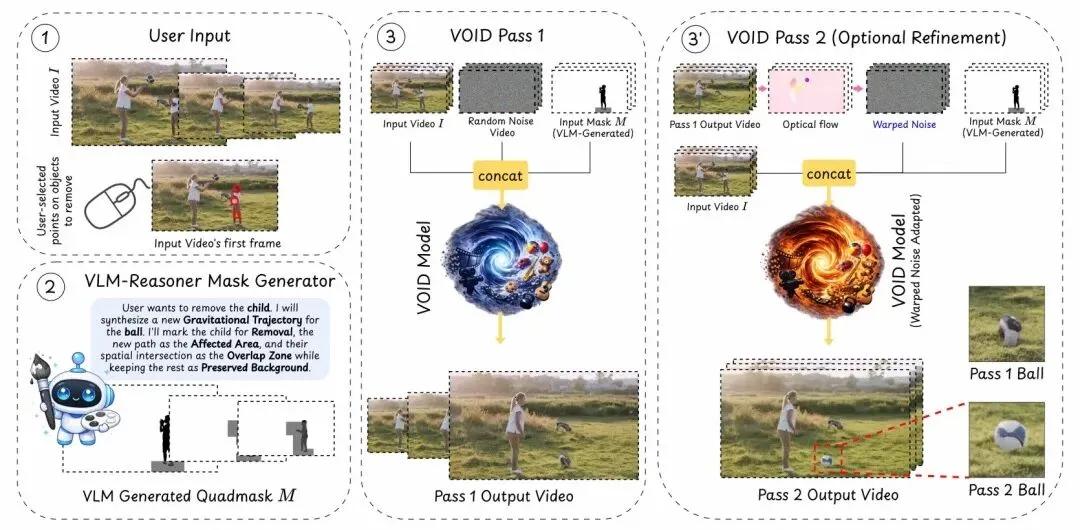
▲ VOID工作流示意图
第二,VOID创新性地提出了“四元掩码”(Quadmask)技术(传统通常使用“二值掩码”——黑色代表要删掉的部分,白色代表要保留的部分。)
黑色: 目标移除区,即你想要消失的物体。
白色: 绝对保留区,确保背景和无关物体纹丝不动。
浅灰色:受影响区域(Affected Area)。这是VOID的神来之笔。它预先标记出物体掉落轨迹或阴影变化的潜在空间,告诉 AI:“这里原本是背景,但现在由于物理变化,你需要在这里生成新的动态内容。”
深灰色:重叠悖论区。专门处理那些极其复杂的像素——既要删除旧物体,又要同时合成新运动。通过这种精细的标记,VOID解决了传统修复中常见的视觉伪影和边缘模糊。




第三,即便有了逻辑和地图,让AI画出稳定的动态物体还是很难。在早期的实验中,AI画出的掉落物体经常会出现“果冻感”:一个蓝球掉着掉着就变成了一坨,尤克里里也能落地变软。


为了解决这个麻烦,VOID采用了双通道稳定技术(Two-pass system)。
分两步走,先确定物体下落的路线、速度和最终位置(轨迹合成)。
再进行流变形噪声稳定(Flow-warped Stabilization),它利用光流(Optical Flow)技术锁定了物体的“骨架”。
可以把第二步想象成给AI提供了一个透明的模具。在生成每一帧画面时,AI必须在这个模具内填色。这样一来,无论物体运动得多么剧烈,它都能保持其固有的几何结构。确保视频中掉下来的球依然是圆的,摔在地上的尤克里里依然保持形状。


以上,就是VOID宣称的三个“黑科技”,当然没有Netflix肯砸钱,研发也不会那么容易。
▲ 技术论文原文:https://arxiv.org/abs/2604.02296
过去几年Netflix已经展示了自己的野心,是好莱坞最早一批将AI技术融入影视制作的巨头之一。

而VOID的加入,直指影视制作中最昂贵的环节——后期特效。
让“拍错不用补拍”在影视圈不再变成遥遥的奢望。
从行业大趋势来看,AI视频生成正在经历一场深刻的范式转移。如果说早期的视频模型追求的是“像素级画得像”,那么现在以李飞飞团队Marble(多模态世界模型,能通过一张图、一句话、一个视频,直接生成一个完整的3D世界)和Netflix VOID为代表的新一代模型,追求的则是“物理仿真世界模型”。

▲ 李飞飞判断:目前世界模型仍处在“前期工程化 + 中期科研”的阶段。真正的下一代AI,不只是“能聊天”,而是能在世界里理解、预测、行动、并承担后果。而这,正是世界模型真正的价值所在。
AI不再只模仿视频的外壳,而是在内部构建一套符合现实逻辑的运行规律。要求它必须理解什么是重力、什么是碰撞、什么是因果。
如今,Netflix选择将VOID开源,而这项技术是否真如传闻那般神奇,答案,还需每一位创作者亲自上手验证。
END
添加wuhu小精灵3号微信(wuhudonghua3)发送“动画新势力”即可在不久后被邀请进入粉丝群。


OiiOii爆款频出,20万动画人都在用的革新神器

《神奇数字马戏团》1集超4亿播放背后,一个“超级资产”的商业化启幕



奥特曼家被炸了之后,他半夜竟然发了张全家福


