 夜雨聆风
夜雨聆风在日常运维工作中,重复的巡检任务往往消耗大量人力,而人工巡检又容易因疲劳或主观判断出现疏漏。我们基于OpenClaw搭建了一套零人工干预、定时触发、自动判定的智能运维巡检工作流,将巡检从"人找问题"转变为"问题找人"。
架构设计:多个Skill协作模式
整个巡检系统的核心是巡检队长——Agent通过加载不同的Skill完成各阶段工作。就像队长指挥专项兵种:环境确认交给后勤兵,Prometheus查询交给情报兵,报告生成交给文书兵。
每个Skill职责单一、相互解耦:
list_environments负责读取环境配置(Prometheus地址、kubeconfig路径)
inspection-tasks负责解析巡检项清单和阈值配置
prometheus负责执行PromQL查询
k8s-query负责从集群获取实时状态
imap-smtp-email负责将报告送达指定邮箱
这种设计的好处很明显,新增巡检项只需修改配置,不用改动代码。
核心流程:六步标准化执行
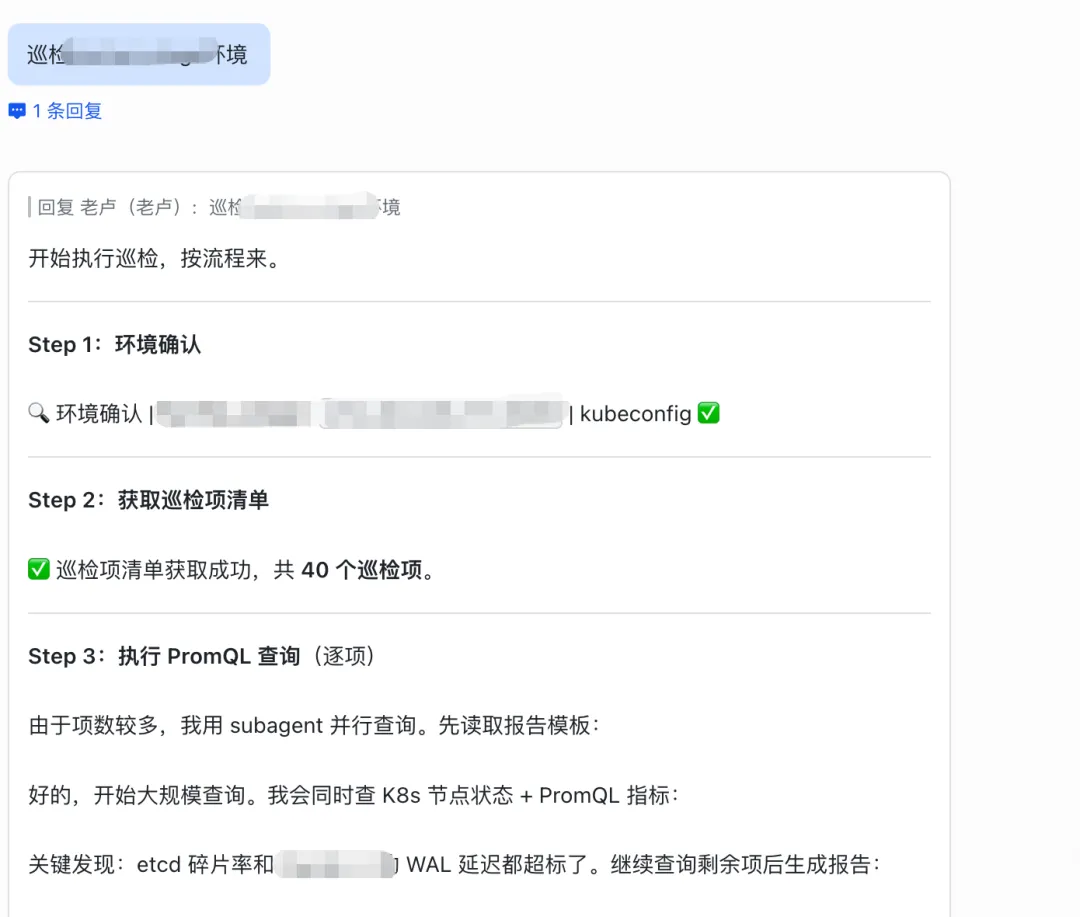
巡检队长的执行流程严格按照六步顺序执行,每一步完成后才进入下一步,确保不遗漏任何环节。
环境确认:队长从配置文件读取本次巡检的目标环境,获取Prometheus URL和集群凭证,打印确认信息后开始工作。
读取巡检清单:队长解析YAML格式的巡检项配置,获取所有需要执行的PromQL语句和对应的阈值。这个配置由运维团队提前维护,队长无权修改巡检范围。
逐项查询:对清单中的每一项,队长依次执行PromQL查询并记录结果,无论指标是否异常都必须执行,不允许跳过。这一步保证了数据的完整性。
分析判定:将查询结果与阈值对比,标注为正常、警告或严重三个级别。阈值全部来自配置文件,不允许硬编码。
报告生成:按照固定模板生成Markdown格式巡检报告,包含环境信息、汇总统计、异常明细和正常项概览。模板统一,输出格式不会因执行者不同而变化。
邮件发送:读取配置中的收件人地址,将报告作为邮件正文发送,完成整个巡检闭环。

真实数据与自动判定
在实际落地过程中,有两个技术细节值得注意。
数据必须真实查询,不能编造。系统设计了强制约束:版本信息(如kubelet版本、操作系统)必须通过kubectl实时从集群获取,PromQL查询结果必须来自真实返回值。任何臆测数据的行为都会被Skill层约束拦截。
定时触发与超时控制。通过系统cron任务实现每日定时巡检,支持灵活的超时时间配置。当集群规模较大、Prometheus查询较慢时,适当调大超时阈值可以避免任务意外中断。
效果与展望
目前该巡检系统已稳定运行,每日定时对生产环境和预发环境各执行一次。异常指标通过邮件实时推送,报告包含具体的实例名称、数值和阈值对照,运维人员可以直接定位问题根因。
后续可以考虑扩展的方向包括:异常根因自动分析、预测性巡检(提前发现)、问题知识库与方案推荐等
你所在的团队还有哪些运维提效的实用技巧?欢迎在评论区留言和大家一起分享讨论。
