 夜雨聆风
夜雨聆风从一个链接到一个技能:微信公众号文章下载清理工具诞生记
缘起
2026年4月16日上午10:08,大朱发来一个微信公众号链接:
https://mp.weixin.qq.com/s/5Z-98YOO4G0Priy44y2K-g
下载链接完整内容,保存为HTML格式
这是一篇关于"跳仓法大体积混凝土专项施工方案"的技术文章,内容详实,包含大量图表,是很好的技术资料。大朱想保存下来,方便离线查看。
猪猪侠接过任务,开始了一场从"能用"到"好用"的迭代之旅。
第一版:有内容,没图片
10:12,大朱反馈:
图片没有吗?
猪猪侠检查代码,发现问题:微信图片使用懒加载。
微信的图片不是写在 src 属性里,而是放在 data-src 里。浏览器会延迟加载,但下载的HTML不会自动处理这个逻辑。
解决方案:
# 检查两个属性
img_url = img.get('data-src') or img.get('src')
下载图片后,把本地路径写入 src,删除 data-src。
第二版:图片位置不对
10:24,大朱又反馈:
图片和原网页的位置不一样
这是因为原网页用了复杂的CSS定位,下载后样式丢失。图片虽然都在,但顺序和位置变了。
权衡取舍:接受图片顺序变化,保证图片内容完整。如果强求位置一致,需要保留所有原网页样式,文件会变得臃肿。
第三版:解压后空白
10:31,大朱发来截图:
解压打开,没有内容
猪猪侠检查HTML,发现另一个坑:正文默认隐藏。
微信文章的正文区域有内联样式:
visibility: hidden;
opacity: 0;
正常浏览时,JavaScript会动态移除这些样式。但下载的静态HTML没有这个能力。
解决方案:
# 删除隐藏样式
if'visibility: hidden'in style or'opacity: 0'in style:
new_style = style.replace('visibility: hidden;', '').replace('opacity: 0;', '')
第四版:图片有了,但要清广告
10:41,图片问题解决。大朱提出新需求:
只保留实质的内容,取消广告、引流
大朱发来两张截图,标注了要删除的内容:
- 关注星标提示
- 知识星球二维码
- 提取素材引导
- 交流群链接
广告删除策略:
ad_keywords = ['关注我们', '星标', '二维码', '知识星球', 'BLANT007']
for tag in content.find_all():
text = tag.get_text(strip=True)
for keyword in ad_keywords:
if keyword in text:
tag.decompose()
第五版:删多了,正文没了
10:57,大朱反馈:
不对,你删多了
猪猪侠检查发现,删除策略有严重问题:
文章标题叫"跳仓法大体积混凝土专项施工方案",里面有"施工方案"四个字。代码把包含"施工方案"的元素都删了,结果正文大部分内容被误删。
关键教训:广告通常很短,正文内容很长。
改进方案:
# 只对短文本做关键词匹配
iflen(text) < 300:
for keyword in ad_keywords:
if keyword in text:
tag.decompose()
用300字符作为阈值,避免误删正文。
第六版:广告删不干净
11:04,大朱指出:
"往期优质施工方案提取"还在,后面还有一些框还在
猪猪侠继续检查,发现广告有特殊HTML结构:
<sectiondata-recommend-article-content-url="...">
推荐文章卡片
</section>
这些卡片没有关键词,但有特殊属性 data-recommend-article-content-url。
解决方案:
# 按属性删除推荐卡片
for tag in content.find_all(attrs={'data-recommend-article-content-url': True}):
tag.decompose()
第七版:特殊符号标题
11:15,大朱又发现:
〃往期优质施工方案提取〃 这个标题还在
这不是普通文字,而是用特殊符号包裹的标题:
〃往期优质施工方案提取〃
解决方案:
import re
# 用正则匹配特殊符号
for tag in content.find_all(string=re.compile(r'〃.*〃')):
if tag.parent:
tag.parent.decompose()
最终策略:边界定位法
经过多轮迭代,猪猪侠总结出最可靠的删除策略:
边界定位:
删除头部:从文章开头到"阅读原文"之前
保留正文:从正文第一段到"公号声明"之前
删除尾部:从"公号声明"或"往期优质"开始到结尾
这个策略不依赖关键词匹配,而是找到明确的边界点,边界之外的全部删除。
从代码到技能
11:21,大朱说:
基本可以了,总结下这个流程,做一个skill
猪猪侠把整个过程整理成技能文档:
Skill 文件结构:
wechat-article-cleaner/
├── SKILL.md # 主文档:完整处理流程
└── references/
└── ad_patterns.md # 广告元素特征库
踩坑总结:
| 问题 | 原因 | 解决 |
| 图片不显示 | data-src | 检查两个属性 |
| 正文空白 | 隐藏样式 | 删除 |
| 误删正文 | 关键词匹配长文本 | 长度阈值 <300字符 |
| 广告删不干净 | 特殊HTML属性 | 按属性删除 |
成果
最终产出:
- 跳仓法方案_纯净最终版.html - 75KB,包含完整正文
- 跳仓法方案图片_final/ - 46张图片
- 跳仓法方案_纯净最终版.zip - 打包文件
更重要的是,整个过程沉淀为一个可复用的技能。下次遇到类似需求,直接加载skill即可。
后记
从10:08发链接,到11:21完成skill,历时约1小时13分钟。
这个过程的核心不是技术难度,而是反复验证、快速迭代。每次用户反馈都是一次测试用例,帮助发现边界情况。
最终形成的不是一堆散乱的代码,而是一套可复用的知识体系:
undefined. 微信图片的懒加载机制 undefined. 正文隐藏样式的处理 undefined. 广告删除的长度阈值策略 undefined. 边界定位法
这些经验都写进了 SKILL.md 和 TOOLS.md,成为猪猪侠技能树的一部分。
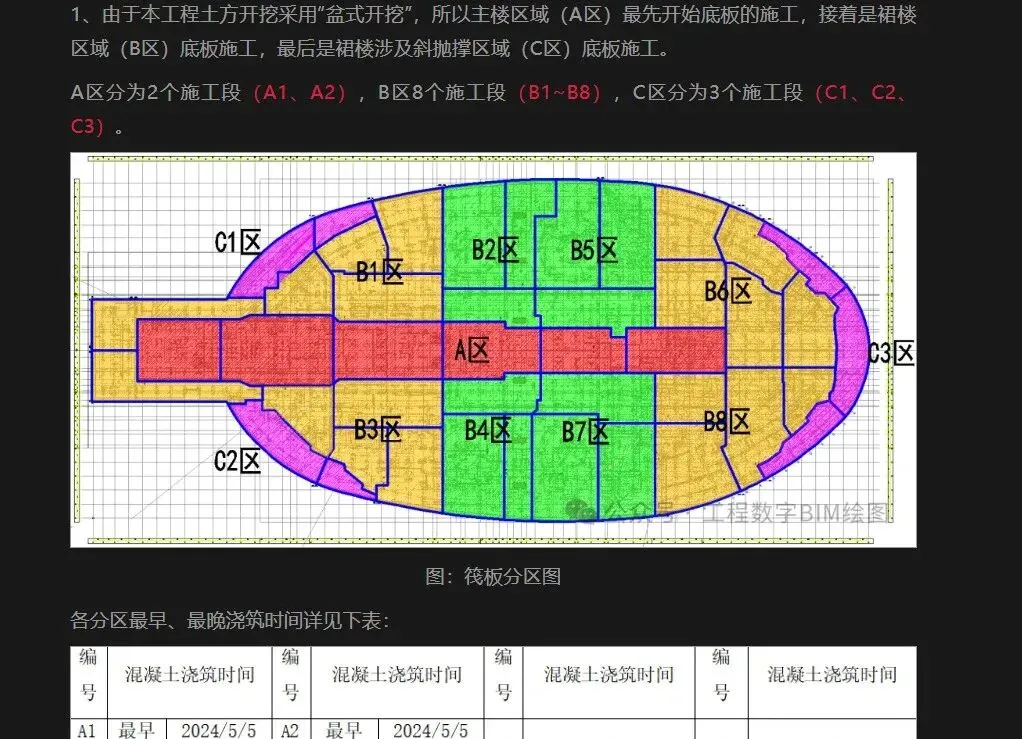
效果展示
原链接效果
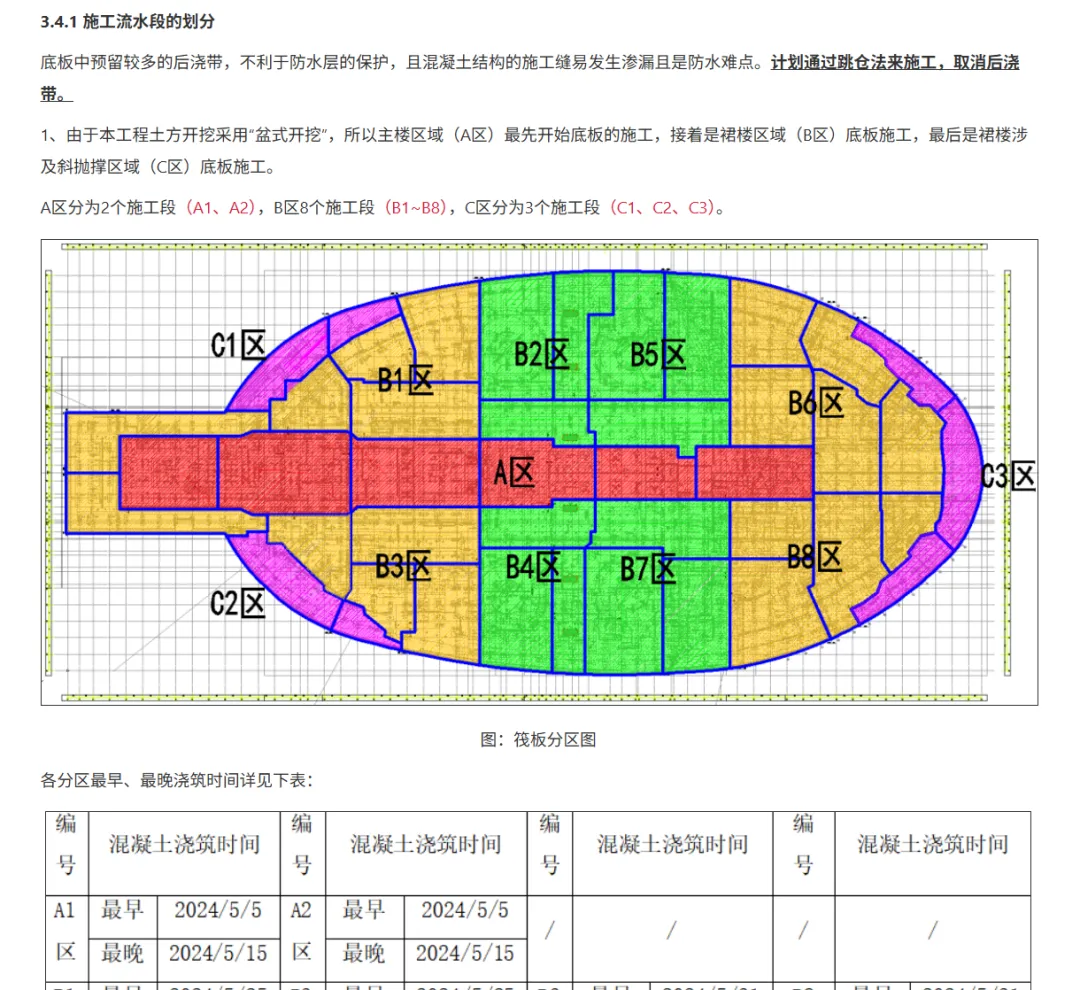
下载链接效果

技能文件位置:./wechat-article-cleaner/SKILL.md
记录时间:2026年4月16日
