 夜雨聆风
夜雨聆风大家好,我是枯燥的工程师。
近几年软考的命题趋势显示,考查范围越来越广,细节要求越来越高。仅靠学习传统的“重点难点”,已难以覆盖所有考点,系统性遗漏的风险在增加。因此,我对《软件设计师》教材进行了全面梳理,预计200余个具体知识点,逐一整理、编号、解读。建立完整的知识体系,是应对当前考试最扎实的方法。也欢迎大家扫描文末二维码加入学习交流群!
从2月份开始,我将以每周更新三次的频率,严格按教材顺序分享知识点,预计四月下旬完成。
今天我们继续分享第9章:
知识点13.函数依赖
1、函数依赖。
设R(U)是属性集U上的关系模式,X、Y是U的子集。X函数决定Y或Y函数依赖于X,记作X→Y。
2、完全函数依赖。
在R(U)中,如果X→Y,并且对于X的任何一个真子集X´都有X'不能决定Y,则称Y对X完全函数依赖。
3、部分函数依赖。
如果X→Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖。
4、传递依赖。
在R(U,F)中,如果X→Y,Y→Z,则称Z对X传递依赖。
5、码。
设K为R(U,F)中属性的组合,若K→U且对于K的任何一个真子集K'都有K'不能决定U,则K为R的候选码。若有多个候选码,则选一个作为主码。候选码通常也称为候选关键字。
6、主属性和非主属性。
包含在任何一个候选码中的属性称为主属性,否则称为非主属性。
7、外码。
若R(U)中的属性或属性组X非R的码,但X是另一个关系的码,则称X为外码。
8、函数依赖的公理系统(Armstrong公理系统)。
⚫Al自反律:若𝑌⊆𝑋⊆𝑈,则X→Y为F所蕴涵。
⚫A2增广律:若X→Y为F所蕴涵,且𝑍⊆𝑈,则XZ→YZ为F所蕴涵。'.
⚫A3传递律:若X→Y,Y→Z为F所蕴涵,则X→Z为F所蕴涵。根据上述3条推理规则又可推出下述3条推理规则。
⚫合并规则:若X→Y,X→Z,则X→YZ为F所蕴涵。
⚫伪传递率:若X→Y,WY→Z,则XW→Z为F所蕴涵。
⚫分解规则:若X→Y,𝑍⊆𝑌,则X→Z为F所蕴涵。
知识点14.规范化
1、第一范式1NF
关系中的每一个分量必须是一个不可分的数据项。通俗地说,第一范式就是表中不允许有小表的存在。比如,对于如下的员工表,就不属于第一范式:
例如:学生表(学号,学生姓名,系编号,课程号,成绩,系名,系主任)
学生→学号,学生→学生姓名,学生→系号,系号→系主任姓名,学生→课程号,(学生,课程号)→成绩
2、第二范式
如果关系R属于1NF,且每一个非主属性完全函数依赖于任何一个候选码,则R属于2NF。
通俗地说,2NF就是在1NF的基础上,表中的每一个非主属性不会依赖复合主键中的某一个列。
按照定义,上面的学生表就不满足2NF,因为学号不能完全确定课程号和成绩(每个学生可以选多门课)。
将学生表分解为:
学生(学号,学生姓名,系编号,系名,系主任)
选课(学号,课程号,成绩)。
每张表均属于2NF。
3、第三范式
在满足2NF的基础上,表中不存在非主属性对码的传递依赖。
继续上面的实例,学生关系模式就不属于3NF,因为学生无法直接决定系主任和系名,是由学号->系编号,再由系编号->系主任,系编号->系名,因此存在非主属性对主属性的传递依赖。
将学生表进一步分解为:
学生(学号,学生姓名,系编号)
系(系编号,系名,系主任)
选课(学号,课程号,成绩)
每张表都属于3NF。
知识点15.无损连接与函数依赖
1、函数依赖:
如果F上的每一个函数依赖都在其分解后的某一个关系上成立,则这个分解是保持依赖的(这是一个充分条件)。
2、无损分解:
分解后的关系模式能够还原出原关系模式,就是无损分解,不能还原就是有损。
当分解为两个关系模式,可以通过以下定理判断是否无损分解:
定理:如果R的分解为p={R1,R2},F为R所满足的函数依赖集合,分解p具有无损连接性的充分必要条件是R1∩R2->(R1-R2)或者R1∩R2->(R2-R1)。
9.6数据库的控制功能
知识点16.事务管理
事务是一个操作序列,这些操作“要么都做,要么都不做”,是数据库环境中不可分割的逻辑工作单位。
事务具4个特性,也称事务的ACID性质。
(1)原子性。事务是原子的,要么都做,要么都不做。
(2)一致性。事务执行的结果必须保证数据库从一个一致性状态变到另一个一致性状态。
(3)隔离性。事务相互隔离。当多个事务并发执行时,事务的操作对其他事务不可见的。
(4)持久性。一旦事务成功提交,其对数据库的更新操作也将永久有效。
知识点17.并发控制
1、并发操作
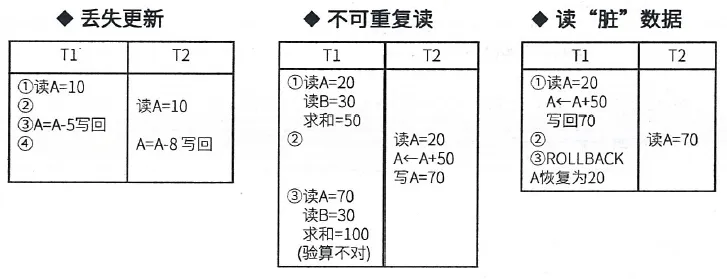
所谓并发操作,是指在多用户共享的系统中许多用户可能同时对同一数据进行操作。并发操作带来的问题是数据的不一致性,主要有三类:丢失更新、不可重复读和读脏数据。
丢失更新:事务1对数据A进行了修改并写回,事务2也对A进行了修改并写回,此时事务2写回的数据会覆盖事务1写回的数据,就丢失了事务1对A的更新。即对数据A的更新会被覆盖。
不可重复读:事务2读A,而后事务1对数据A进行了修改并写回,此时若事务2再读A,发现数据不对。即一个事务重复读A两次,会发现数据A有误。
读脏数据:事务1对数据A进行了修改后,事务2读数据A,而后事务1回滚,数据A恢复了原来的值,那么事务2对数据A做的事是无效的,读到了脏数据。
2、排他锁与共享锁
(1)排它锁。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他事务都不能再对A加任何类型的锁,直到T释放A上的锁。
(2)共享锁。若事务T对数据对象A加上S锁,则只允许T读取A,但不能修改A,其他事务只能再对A加S锁,直到T释放A上的S锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A进行任何修改。
3、三级封锁协议
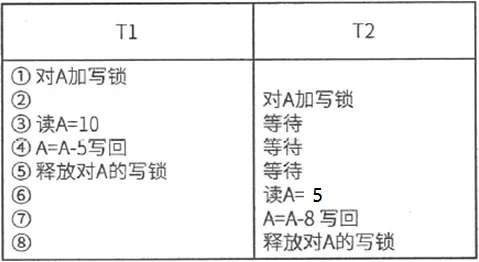
(1)一级封锁协议。事务在修改数据R之前必须先对其加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。一级封锁协议可以解决丢失更新问题。
(2)二级封锁协议。在一级封锁协议的基础上,加上事务T在读数据R之前必须先对其加S锁,读完后即可释放S锁。二级封锁协议可以解决读脏数据的问题。但是,由于二级封锁协议读完了数据后即可释放S锁,所以不能保证可重复读。
(3)三级封锁协议。在一级封锁协议的基础上,加上事务T在读数据R之前必须先对其加S锁,直到事务结束时释放S锁。三级封锁协议除了防止丢失修改和不读“脏”数据外,还进一步防止了不可重复读。

知识点18.数据库的备份与恢复
1、数据库中的4类故障
(1)事务内部故障。事务内部的故障有的可以通过事务程序本身发现。
(2)系统故障。通常称为软故障,是指造成系统停止运行的任何事件。
(3)介质故障。通常称为硬故障,如磁盘损坏、磁头碰撞和瞬时强磁干扰。
(4)计算机病毒。计算机病毒是一种人为的故障和破坏。
2、备份方法
恢复的基本原理是“建立数据冗余”(重复存储)。数据的转储分为静态转储和动态转储、海量转储和增量转储、日志文件。
(1)静态转储和动态转储。指在转储期间不允许对数据库进行任何存取、修改操作。
(2)海量转储和增量转储。海量转储是指每次转储全部数据;增量转储是指每次只转储上次转储后更新过的数据。
(3)日志文件。在事务处理的过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件
3、恢复事务恢复步骤:
(1)反向扫描文件日志(即从最后向前扫描日志文件),查找该事务的更新操作。
(2)对事务的更新操作执行逆操作。
(3)继续反向扫描日志文件,查找该事务的其他更新操作,并做同样的处理,直到事务的开始标志。

