 夜雨聆风
夜雨聆风过去三年,AI天天霸屏,从ChatGPT到Sora再到DeepSeek等各种国产大模型,烧钱如流水,但变现的途径始终不太清晰。整个行业像极了在跑一场前面吊着胡萝卜、“只讲技术不讲利润”的马拉松。
风向正在悄悄转变了。综合高盛及多家头部券商的年度策略,2026年被一致圈定为AI由“流动性叙事”转向“盈利叙事”的关键拐点。兴业证券也做了如下判断:2026年将成为AI产业的分水岭,核心叙事从技术军备竞赛正式迈入“商业化兑现期”。
为什么之前还没到盈利兑现阶段?
过去三年,AI行业一直在干一件事:打基建。
全球四大互联网巨头(微软、谷歌、亚马逊、Meta)的资本支出在2025年都达到3622亿美元以上的高位,疯狂地买显卡、建数据中心、堆算力。"想致富、先修路",先把算力规模堆上去再说。
为了打开市场,2024年OpenAI、Anthropic、谷歌等巨头集体将旗舰模型的API调用价格下调超90%。国内紧随其后,字节跳动率先出手,BAT等企业紧随其后,百万token压到1元,甚至打出“免费、永久免费”的口号:先用低价甚至免费抢用户,快速抢占市场份额。
这种情况下,大部分AI公司理所当然地处于亏损的境地。例如智谱,2025年营收虽然增长了131.9%,净亏损依然高达47.18亿元。
当然,厂商在算另外一笔帐,提升AI普及率的同时,真实场景里用户高频使用产生的对话数据反向助力AI大模型的迭代优化,提高产品竞争力,形成商业闭环。
2026年来临的变化
变化的不是某个单一事件,而是一连串“共振”。
01 算力成本剧烈下降
2026年,三个层面的技术突破集中释放,使得主流模型的推理单位Token输出成本在过去3年下降了超99%。
硬件层面,谷歌与博通共同开发的TPU v7,单位推理成本相比上一代下降约70%,绝对成本已与英伟达GB200基本持平。
软件层面,谷歌在2026年4月推出了TurboQuant技术,在英伟达H100上实现了内存使用量减少6倍、注意力逻辑计算速度提升8倍。
国产化层面,DeepSeek宣布下一代旗舰模型V4完全适配华为昇腾950PR芯片。这是国产万亿参数MoE大模型首次在推理阶段彻底摆脱对英伟达GPU的依赖,而昇腾 950PR标准版5万元,高配HBM版7万元,仅为英伟达 H20的1/2-1/3。
“杰文斯悖论”也被触发了:模型优化和芯片迭代造成的成本极度收敛反而刺激了更广泛的使用场景和更高的收入产出,形成技术迭代,推动应用普及的正向循环。

02 商业化路径逐渐清晰
2026年一季度,“龙虾潮”引爆全行业,同时冒出来的还有另外四种完全不同的 Agent产品形态。OpenClaw走个人助理、Cowork走办公协作、Codex走长程工程任务、Perplexity Computer 走统一工作站、腾讯云 ADP走企业平台。
这不是巧合,而是底层条件刚刚成熟后,行业同时闻到的味道。AI Agent被赋予的期待不再只是简单地“回答问题”,而是能独立规划任务、调用工具、执行多步骤工作流。
用户为之花钱购买的也是一个主动推进、持续工作、自动学习的数字劳动力。
AI的需求不是线性增长而是拐点驱动,只要通向真实需求场景的路径足够短、足够明确,使用量就会从线性增长切换为“上凸曲线”式爆发。
03 大模型重掌定价权
智能体每次记忆回溯、执行任务都将消耗大量token。每一次的token成本,也变成了个人和企业愿意为提升效率付出的生产成本。
市场已经达成共识:能力强的模型拥有定价权。
如果大模型能独一无二地解锁高价值任务(智能体编码、长时程工作流、企业级可靠性),由于可量化的回报,客户会愿意支付溢价。另一方面,随着硬件、算法效率不断提升,推理单位成本将持续下降,对能力停滞的模型形成价格压力。
智谱CEO张鹏提出了一个概念——TAC(Token架构能力),他认为当大模型具备长程任务执行的闭环能力后,核心竞争力将重塑为“智能调用量×智能质量×经济转化效率”的乘积。
近期,多家厂商开始结束免费公测、转向正式商用按量计费,甚至释放涨价信号。
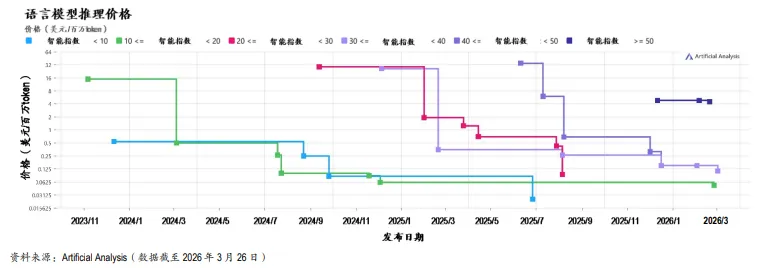
关键的是,市场已经开始接受高质量Token的收费权,而不是“谁涨了多少价”。这比单纯的调用量增长更重要。
处于周期的节点
当然,跳出产业细节,从周期视角来看:
科技内部子周期中,渗透率拉升、算力仍然短缺、ROI逐渐显现、预期偏热、赛道仍然竞争不止;信用周期中,利率环境为扩大投资兜底;市场流动性宽松周期中,高预期、高估值、强流动性并存;技术周期中,AI进入真正的大规模部署未来可期。
不管怎样,2026年AI的淘汰赛会更加可视而激烈,这头“吞金兽”也终于开始反哺。接下来,谁能在智能体、多模态、行业垂直应用这些“深水区”率先跑通闭环,谁就能吃下最大的一块蛋糕。

