 夜雨聆风
夜雨聆风
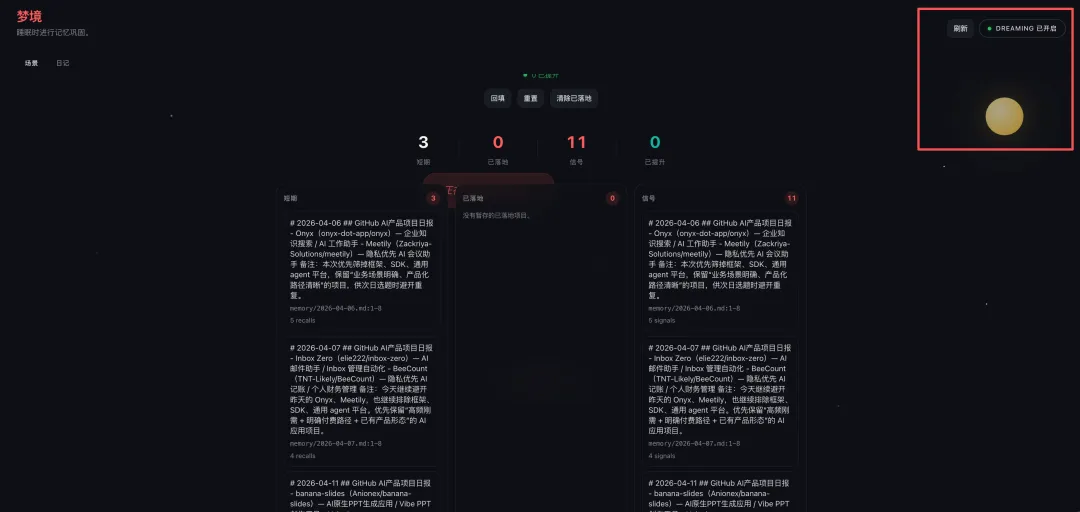
很多人第一次看 OpenClaw 的记忆系统,第一反应都很朴素:不就是把东西记下来,等需要的时候再搜出来吗?
这个理解不能说错,但只说到了一半。真正有意思的地方在于,OpenClaw 不是只做了一个“会检索的笔记本”,它还补上了 短期记忆、夜间整理、主动召回 这三层能力。
说白了,前台是“记”,后台是“理”,回复前还有个“小秘书”先帮你翻档案。这样一套链路跑起来,智能体才会从“会查资料”慢慢变成“越来越懂你”。
先别急着谈 AI,先把“记忆”这件事讲清楚
如果只用一句话解释 OpenClaw 的记忆,我会这么说:
记忆 = 被保存下来的内容 + 在需要时能被准确召回的能力。
前半句像做笔记,后半句像查目录找书。
你把一本书放进书架,不代表你下次就一定能在 30 秒 内翻到想要的那一页。真正有价值的,不只是“存过”,而是“找得到,而且找得准”。OpenClaw 的记忆系统,本质上就在解决这个问题。
它通常分成两层:
短期记忆: memory/*.md,更像日记式、主题式的工作台账长期记忆: MEMORY.md,沉淀跨会话依然值得保留的事实、偏好和稳定背景
这个设计背后的逻辑很实在:不是所有信息都值得升格为长期记忆。
今天临时记录的一条报错、一个待测试命令、一次随口提到的想法,可能只适合留在短期区;真正会被反复用到、能持续影响回复质量的内容,才值得进入 MEMORY.md。
Dreaming 不是玄学,它更像夜间记忆整理员
很多人看到 “Dreaming” 这个名字会下意识觉得有点抽象,但它做的事其实非常具体。
白天,智能体一边聊天,一边产生很多零散材料;晚上,Dreaming 像整理员一样把这些材料拿出来复盘,决定哪些该留在暂存区,哪些值得升级。
它分成 3 个阶段:
Light:整理和暂存短期材料,不写 MEMORY.mdREM:提炼主题和反思,不写 MEMORY.mdDeep:真正评分,并决定是否写入 MEMORY.md
这套分层设计很关键,因为它避免了一个很常见的问题:AI 什么都记,最后把记忆库记成垃圾堆。
如果没有 Light 和 REM 这两层缓冲,系统很容易把大量噪音、临时上下文、偶发情绪全都直接塞进长期记忆。短期看像“记得很全”,长期看就是“越记越乱”。
从用户视角看,Dreaming 的价值不是“帮你生成了多少睡眠报告”,而是它在替你做一次筛选:
什么只是当天临时有用 什么是反复出现的高价值信息 什么真的值得跨会话保留下来
这个判断过程,才是记忆系统能不能越用越聪明的分水岭。
真正决定记忆好不好用的,是检索,不只是存储
很多人对记忆系统的误解,卡在“有没有存下来”。
但从工程角度看,决定体验的往往不是写入,而是召回。因为你真正感受到“它懂我”,通常不是在它写文件的那一刻,而是在你发出一句话后,它能不能把对的东西找回来。
OpenClaw 在查询时通常会走两路并行:
1. 向量检索
先把 query 做 embedding,再去向量库里找语义相近的片段。
这一路特别适合处理“意思接近,但措辞不一样”的情况。比如你今天说“我想看 AI 产品日报”,和你上周写的是“每天追踪 AI 工具更新”,字面不一样,但语义上其实是近的。
2. 关键词检索
对 query 分词,然后去全文索引里找关键词命中。
这一路更适合找精确项,比如:
某个 message_id某个配置 key 某条报错 某个参数名
如果只靠向量检索,像配置字段、ID、版本号这种特别“硬”的词,效果往往不稳定;如果只靠关键词检索,又容易漏掉语义接近但表述不同的内容。
所以 OpenClaw 选择的是 混合检索。
两路结果拉回来后,再做加权合并和排序。增强项里还会有:
temporal decay:最近的记忆更容易排前面 MMR:去重,避免一堆相似结果霸榜
这背后的逻辑很像一个成熟编辑在整理资料:既要看“相关不相关”,也要看“是不是重复”,还要看“是不是最近刚发生”。
这些被检索到的痕迹,反过来还会影响长期记忆晋升
这里是很多人第一次看 OpenClaw 时容易忽略,但其实非常妙的一层。
Dreaming 在做长期记忆晋升判断时,不是只看“这段话写没写进文件”,还会参考它有没有被系统反复召回。
比如 Deep ranking 里常见的几个信号:
frequency:某条候选内容被反复命中的次数 relevance:每次被检索到时,相关性质量高不高 query diversity:是不是被不同问题、不同上下文多次打到
这就像人脑的一个朴素规律:
你不是因为“见过一次”就永远记住,而是因为它反复被提取、反复被使用,才慢慢从短期印象变成稳定记忆。
所以 Dreaming 不是简单的日志汇总器,它更像一个“记忆晋升评审器”。它会看这条信息到底有没有长期价值,而不是看到内容就机械入库。
想把检索能力跑起来,先别一上来就追求大而全
如果你什么都不配,OpenClaw 在自动探测一圈后,如果发现没有可用的大模型 embedding 服务,就会直接放弃向量化能力,退回到 纯文本关键词搜索 模式。
这不一定是坏事。
因为关键词模式虽然朴素,但至少可用、稳定、零额外成本。对于刚开始搭环境的人来说,这个降级策略反而很友好,不会让整套系统因为“缺一把 API Key”直接瘫掉。
但如果你想让中文召回更自然,还是建议把向量检索补上。
一个相对省心的最小接入方案是:Ollama + 中文 embedding 模型。
第一步,先把 Ollama 跑起来
ollama serve
如果你装的是桌面版 Ollama,通常后台已经启动,这一步可能都不用你手动敲。
确认是否启动成功:
curl http://127.0.0.1:11434/api/tags
第二步,准备 embedding 模型
官方默认常见的是 nomic-embed-text,但如果你的主要语料是中文,建议直接选更合适的中文 embedding 模型。
例如:
ollama pull qwen3-embedding:0.6b
ollama pull qwen3-embedding:4b
ollama pull qwen3-embedding:8b
然后用下面这条确认是否拉取完成:
ollama list
这里的分析逻辑很简单:
0.6b:更轻,适合先跑通 4b:质量和资源消耗更均衡,通常是比较合适的主力档 8b:效果更强,但机器资源要求也更高
对大多数本地中文环境来说,qwen3-embedding:4b 往往是一个比较稳的平衡点。
配置 Memory Search 时,有个版本坑值得提前说清楚
如果 Ollama 不在默认端口,你需要显式配置 provider,而且要注意:
**baseUrl 不能带 /v1**。
正确示例:
{
"models": {
"providers": {
"ollama": {
"apiKey": "ollama-local",
"baseUrl": "http://127.0.0.1:11434",
"api": "ollama"
}
}
}
}
但如果你刚好在 4.12 这个版本附近,还会遇到一个现实问题:有些环境里直接走 Ollama provider 可能不够顺手,这时可以临时把 Ollama 的 embedding 接口伪装成 lmstudio provider 来用。
示例配置:
{
"models": {
"providers": {
"lmstudio": {
"apiKey": "lmstudio-local",
"baseUrl": "http://127.0.0.1:11434/v1",
"models": []
}
}
},
"agents": {
"defaults": {
"memorySearch": {
"enabled": true,
"provider": "lmstudio",
"model": "qwen3-embedding:4b",
"query": {
"hybrid": {
"enabled": true,
"vectorWeight": 0.7,
"textWeight": 0.3,
"mmr": { "enabled": true, "lambda": 0.7 },
"temporalDecay": { "enabled": true, "halfLifeDays": 30 }
}
},
"extraPaths": [],
"experimental": {
"sessionMemory": false
}
}
}
}
}
为什么推荐这一组参数?
因为它在“能搜到”和“别搜得太飘”之间比较平衡:
vectorWeight: 0.7,让语义召回占主导textWeight: 0.3,保证精确关键词别丢mmr,降低重复片段扎堆出现的概率temporalDecay,让最近的记忆更容易浮上来
你可以把它理解成一套很实用的默认编辑策略,而不是玄学调参。
配完后,记得验证
openclaw memory status --deep
openclaw memory search --query "AI产品项目日报"
能查到状态、能搜到结果,这套链路基本就算跑通了。
如果说 Dreaming 是夜间整理员,那 Active Memory 就像隐身小秘书
Dreaming 处理的是“睡前整理”,而 Active Memory 处理的是“回复前预习”。
它是 OpenClaw 里的一个可选插件,本质上是一个在主回复前运行的阻塞型记忆子智能体。说人话就是:在主模型正式回答你之前,它先帮忙去记忆库里翻一遍,看有没有相关背景。
这个流程之所以好用,不是因为它多复杂,而是因为它 够早。
以前很多系统的记忆调用是被动的,你得先明确说“去查查我的偏好”,它才会动;而 Active Memory 是你消息刚发出去,它就先一步去搜,然后把浓缩后的摘要悄悄递给主模型。
于是最后你看到的不是“它去搜完了再回复”,而是“它怎么好像天然就记得”。
这也是为什么它常被形容成一个“隐身小秘书”:
先翻档案 再递纸条 主模型据此自然回答
更重要的是,它默认会控制使用边界,比如只允许在 direct 私聊 里生效,避免在群聊里突然把你的私密偏好抖出来。这一点其实很加分,因为“会记”不是最难的,“知道什么时候别乱记、别乱说”才是更成熟的系统设计。
推荐配置示例:
{
"plugins": {
"entries": {
"active-memory": {
"enabled": true,
"config": {
"agents": ["main"],
"allowedChatTypes": ["direct"],
"queryMode": "recent",
"promptStyle": "balanced",
"timeoutMs": 15000,
"maxSummaryChars": 220,
"persistTranscripts": false,
"logging": true
}
}
}
}
}
这里面最值得关注的几个参数是:
allowedChatTypes:限制只在私聊生效,保护边界queryMode: "recent":速度和上下文连贯性更平衡maxSummaryChars: 220:防止给主模型塞太长的小纸条timeoutMs:限制这一轮主动记忆最多跑多久
如果你问我这套配置的核心思想是什么,那就是四个字:有用,但克制。
从入口到开关,整条路径其实并不复杂
实际操作时,很多人最怕的是“概念听懂了,但不知道去哪儿点”。
这部分反而是最不玄学的。
首先,进入本地 OpenClaw 控制台:
http://127.0.0.1:18789/
然后在菜单栏里找到 Dreaming 入口,进入后可以看到状态面板、已晋升内容和相关操作区。

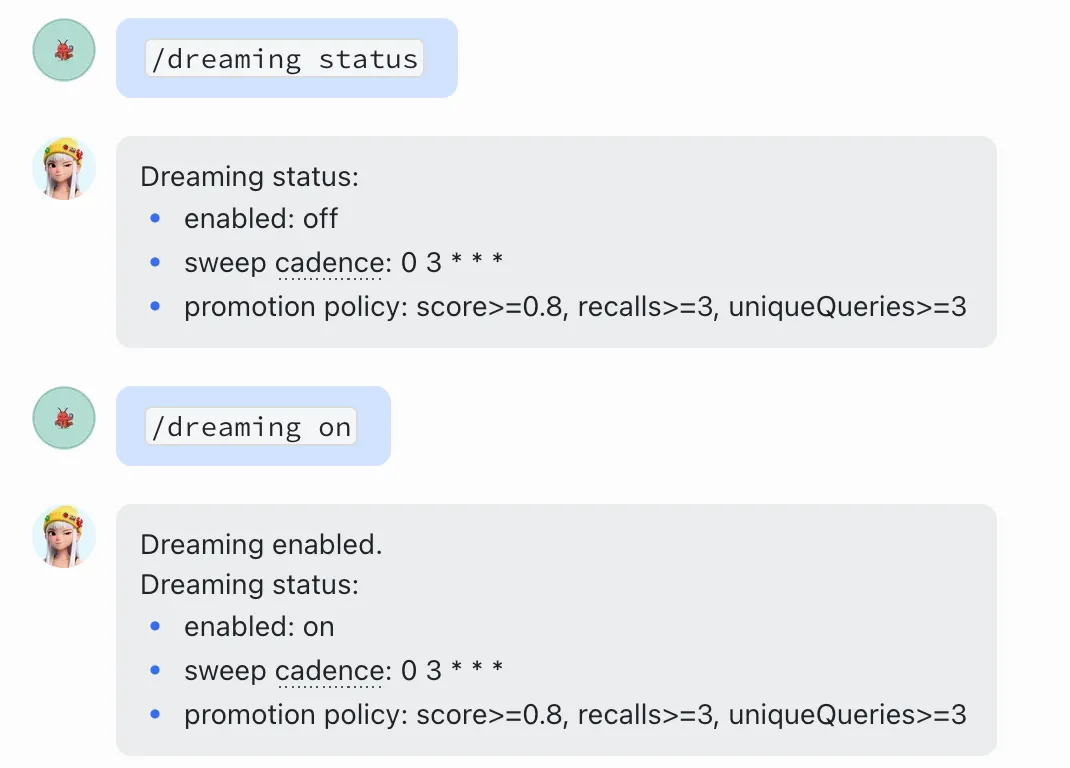
验证 Dreaming 可以直接在聊天窗口里用斜杠命令:
/dreaming status
/dreaming on
验证 Active Memory 则可以用:
/active-memory status
所以你会发现,这整套机制虽然听起来像“记忆进化系统”,但真正落地时并没有那么重。它不是要你先搭一套夸张的 AI 基础设施,而是先把几个关键环节串起来:
记忆文件是否在收集 检索是否能召回 Dreaming 是否在整理 Active Memory 是否能在回复前主动补背景
只要这四步跑通,体验就会明显上一个台阶。
最后把整条链路压成一句人话
如果一定要用一句最接地气的话总结 OpenClaw 的记忆体系,我会说:
白天先记,查询时会找,晚上再整理,回复前还能主动提醒。
对应的数据流其实很清晰:
私信消息 → Active Memory 子智能体 memory_search → 注入隐藏摘要 → 主回复;
夜间则由 Dreaming 做 sweep,生成 DREAMS.md 之类的梦境记录,并在满足条件时把真正值得长期保留的内容升格进 MEMORY.md。
这也是为什么我会说,OpenClaw 的记忆系统,真正厉害的地方从来不是“它会写个文件”,而是它把 存储、召回、筛选、前置辅助 这几件事连成了闭环。
闭环一旦形成,智能体就不只是“知道你说过什么”,而是开始具备一点“知道什么该留下、什么时候该想起来”的味道了。
至于这套机制接下来会不会继续往更强的长期个性化方向进化,我觉得答案大概率是会。只不过真正有价值的方向,应该不是“记得越来越多”,而是“记得越来越准”。
参考链接
OpenClaw 本地控制台: http://127.0.0.1:18789/Ollama 下载:https://ollama.com/download
