夜雨聆风
夜雨聆风
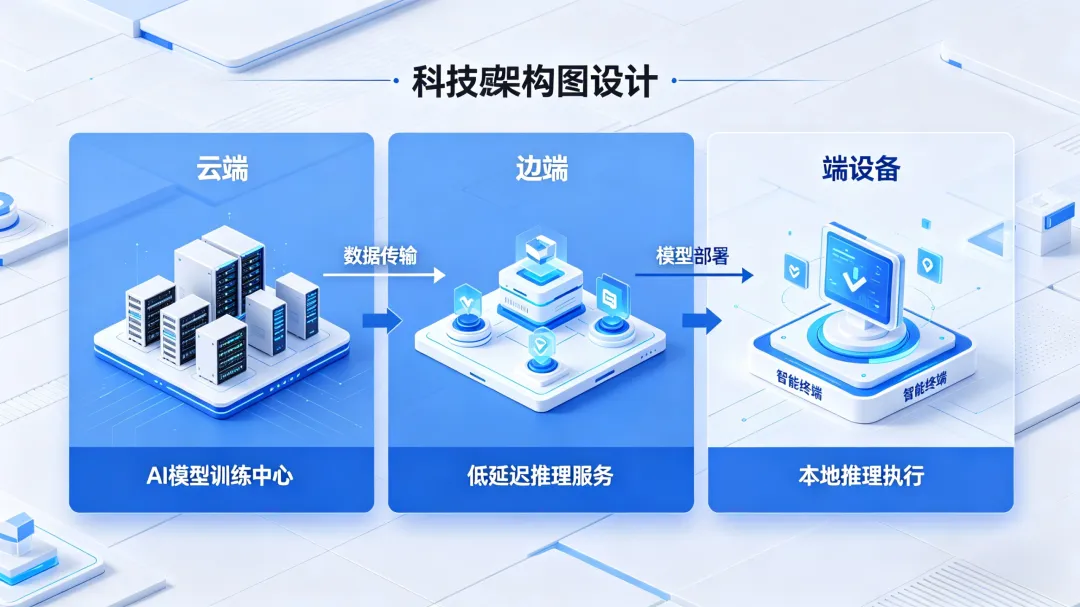
当行业还在惊叹于大模型训练的“算力军备赛”时,一场重塑算力市场底层逻辑的革命已悄然发生。2026年,全球AI算力需求迎来历史性拐点——推理算力占比将达66%,首次正式超越训练算力,成为拉动需求增长的绝对主力。这绝非简单的比例更迭,更是AI产业从“技术研发期”迈入“商业落地期”的核心信号,算力竞争的焦点,也从“资源争夺”转向“效率与成本的长期博弈”。
一、拐点实锤:2026年,推理算力正式接管主导权
2023年,全球AI算力中训练占比仍高达58%,行业重心始终聚焦“锻造最强模型”。但仅仅三年时间,这一格局便被彻底逆转。德勤《2026技术趋势报告》明确预测,2026年全球AI计算workload中,推理占比将飙升至66%,训练占比则萎缩至34%;SEMI中国、百度等机构的预测更为激进,部分数据显示推理算力占比将突破70%。
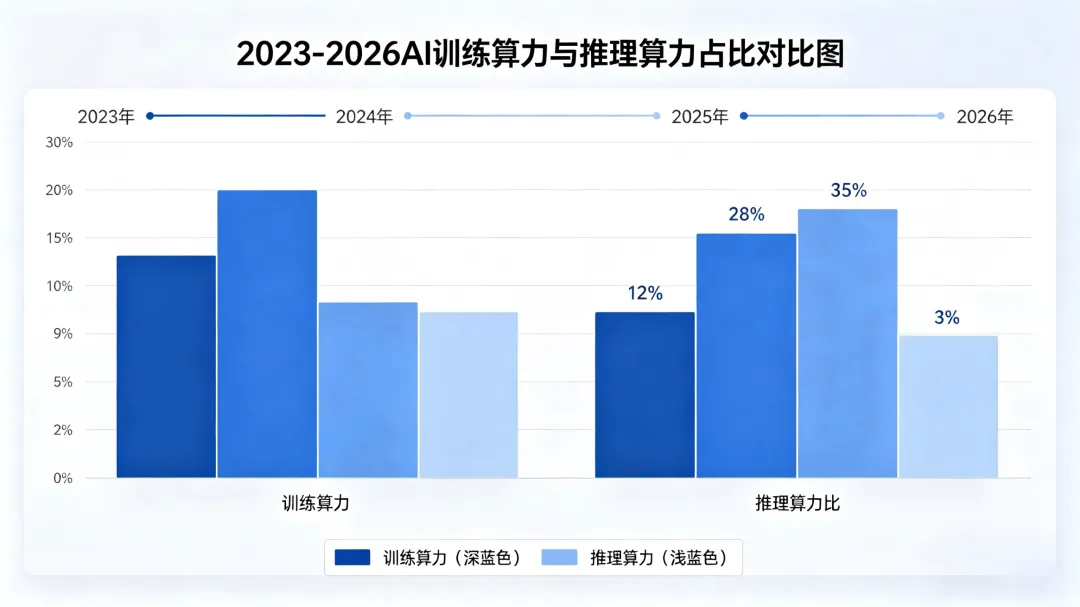
这一拐点的到来,源于AI产业的成熟迭代:2024-2025年是大模型“训练黄金期”,GPT-4、文心一言等头部模型集中完成训练,直接拉动高端H100/H200算力需求暴涨。进入2026年,模型训练逐步进入尾声,大规模商业化落地成为行业核心命题——智能体助手、多模态生成、自动驾驶、工业质检等应用全面渗透千行百业,全球日均Token消耗跃升至数百万亿级,单周调用量从6.4万亿次飙升至22.7万亿次,三个月增幅高达250%。英伟达创始人黄仁勋在GTC 2026大会上直言:“推理拐点已至,过去两年推理计算量增长1万倍,实际使用量增长100倍”。
二、三大核心引擎:引爆推理需求的指数级增长
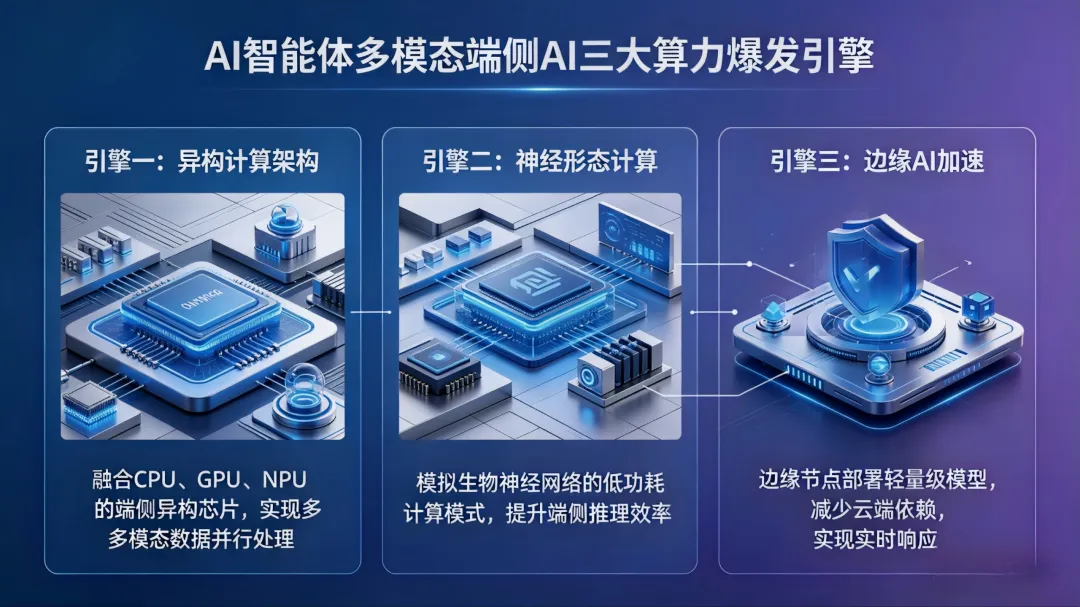
推理算力的爆发绝非偶然,而是智能体(Agent)、多模态、端侧AI三大应用浪潮协同发力的结果,三者叠加之下,算力需求呈几何级突破。
1. 智能体(Agent):7×24小时的“算力吞噬者”
智能体是推理需求的核心爆发点。与传统ChatGPT的单次问答不同,Agent具备自主规划、持续执行、多轮交互的核心能力,可独立完成写报告、订行程、代码开发等复杂任务。每一次任务拆解、每一步决策执行、每一轮工具调用,都需要实时推理算力支撑,且交互过程往往持续数小时甚至数天。英伟达数据显示,单个智能体的算力消耗,是传统对话模型的10-100倍,企业级Agent集群的推理需求,相当于上千个普通大模型服务的总和。更关键的是,Agent的“持续进化”特性,让算力消耗永无上限,成为推理算力的“长期稳定刚需”。
2. 多模态:从“文本理解”到“视听生成”,算力需求百倍跃升
2026年,AI正式迈入“多模态主流时代”,文本、图像、音频、视频的融合交互成为行业标配。与单一文本推理相比,多模态任务的算力消耗呈指数级增长:生成1秒高清视频的算力,相当于上百次文本对话;处理1张高精度工业图像的推理成本,是单条文本Token的50倍。从智能座舱的实时语音交互,到短视频平台的AI生成内容,再到医疗领域的影像诊断、教育行业的虚拟数字人,多模态应用的全面落地,让推理算力需求从“万亿Token级”跃升至“百万亿Token级”,缺口持续扩大。
3. 端侧AI:车/机器人/工业,算力下沉引爆分布式需求
推理需求的爆发,不仅来自云端,更来自端侧设备的全面智能化。2026年,智能汽车、工业机器人、服务机器人、智能家居等端侧设备,将成为推理算力的“新增长极”,推动算力需求从“集中式云端”向“云端+边缘+终端”的分布式架构延伸。
智能汽车:百度数据显示,汽车行业已迈入“全量推理时代”,智能座舱的个性化交互、自动驾驶的实时决策,每辆车日均产生数十万次推理请求;
工业场景:工业质检、设备预测性维护、智能调度等场景,需边缘端实时处理传感器数据,推理需求呈现“分布式、高并发、低延迟”特征;
机器人:服务机器人的语音交互、动作规划,工业机器人的视觉分拣,每一次响应都依赖本地或边缘推理,单台机器人的算力消耗是传统设备的20倍以上。
三、成本结构剧变:训练是“首付”,推理是“终身房贷”
推理时代的到来,不仅改变了算力需求结构,更彻底重构了AI产业的成本逻辑——从“一次性巨额投入”转向“长期持续性消耗”,单Token推理成本,成为决定企业生死的核心指标。
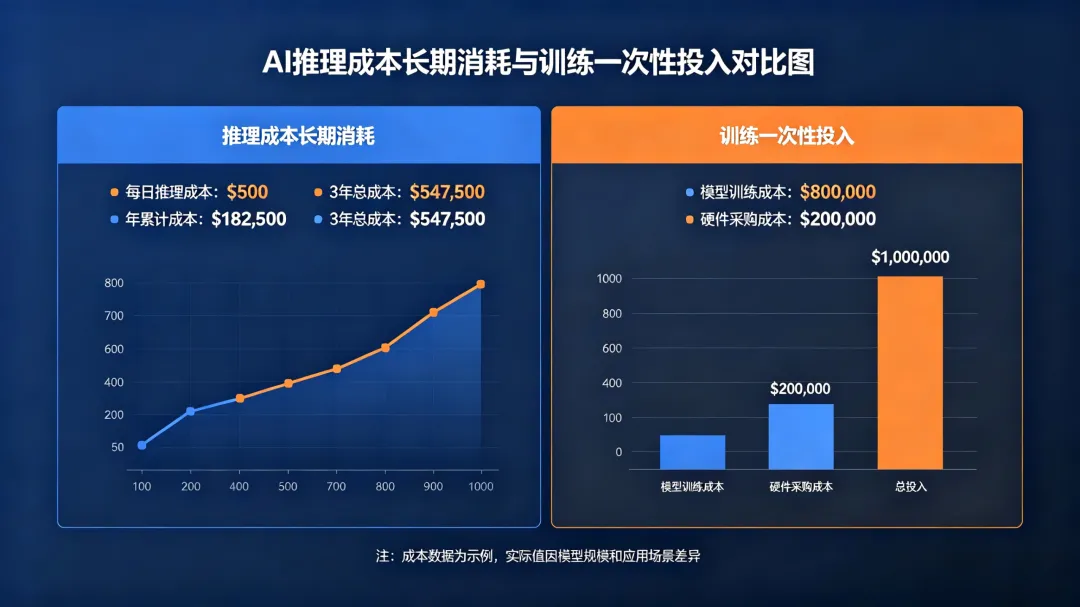
1. 训练:一次性“豪赌”,短期投入有天花板
大模型训练是典型的资本密集型、一次性投入:GPT-4训练成本约7800万-1亿美元,谷歌Gemini Ultra高达1.91亿美元,背后需要千卡级H100集群、数月训练周期,以及MW级电力消耗。但训练一旦完成,后续仅需少量微调即可复用,属于“一次投入、长期受益”的固定资产投资,投入规模有明确天花板。
2. 推理:长期“吸血”,累计成本超训练10倍
与训练相反,推理是持续性、高频次、永无止境的成本消耗。每一次用户提问、每一次Agent执行任务、每一次端侧设备响应,都在消耗算力,且成本随调用量线性增长。GitHub行业报告显示,2026年全球AI基础设施支出中,推理成本占比超80%,训练成本不足20%;对于中等规模大模型服务而言,一年内的推理累计成本,可轻松超过训练成本的10倍以上。
3. 核心竞争点:单Token成本决定规模化生死
推理时代,“单Token推理成本”已取代“模型参数规模”,成为企业核心竞争力。对于AI企业而言,推理成本直接决定服务定价、利润率和市场竞争力:目前GPT-4单次调用成本约0.03-0.12美元,千级Token成本达0.06-0.12美元;若能将单Token成本降低50%,企业便可在降价30%的同时维持利润,快速抢占市场份额。
英伟达、谷歌等行业巨头已率先将“降低推理成本”作为核心战略:英伟达推出专用LPU推理芯片,将推理速度提升1-2个数量级;FP8/INT4量化技术全面普及,使显存占用降低60%以上,单Token成本直接下降40%-70%。可以说,推理时代的算力竞争,本质是单Token成本的“军备赛”。
四、供需错配:通用算力过剩,智算/边缘算力紧缺
2026年的算力市场,呈现出极具矛盾的“结构性失衡”格局:低端通用GPU供大于求、无人问津,高端智算芯片和边缘专用芯片却一卡难求,缺口持续扩大。

1. 通用算力过剩:低端GPU沦为“闲置资产”
在之前的训练热潮中,不少企业盲目采购大量中低端GPU(如A10、RTX 4090),用于模型训练和简单推理。但进入推理时代,这些GPU因高延迟、低并发、高功耗的短板,无法满足智能体、多模态和端侧推理的核心需求,逐渐沦为“闲置资产”。市场数据显示,2026年一季度,中低端GPU库存积压率达35%,价格同比下跌20%-30%,呈现“过剩滞销”的尴尬态势。
2. 智算算力紧缺:HBM GPU、LPU“一卡难求”
智能体、多模态等核心应用,对算力的核心要求是低延迟、高并发、大显存、高带宽,而目前只有搭载HBM(高带宽内存)的高端GPU(如H200、H100 NVL)和专用LPU芯片能满足这一需求。但受限于HBM产能不足、英伟达供货收紧,高端智算芯片严重短缺:2026年全球HBM算力缺口达50%,H200显卡租赁价格半年涨幅达40%,即便如此仍“一卡难求”。黄仁勋曾公开表示:“2026年是算力供需缺口最严重的一年,这一短缺态势将持续至2029年”。
3. 边缘算力爆发:端侧芯片需求“井喷”
端侧AI的全面普及,直接拉动边缘推理芯片需求爆发。智能汽车、工业机器人、智能家居等设备,需要低功耗、小体积、高性价比的专用推理芯片(如昇腾310、海光DCU、英伟达Orin)。2026年全球边缘AI芯片市场规模将达800亿美元,同比增长65%,但芯片产能扩张滞后于需求增长,缺口达40%,成为制约端侧AI规模化落地的核心瓶颈。
五、算力竞争,从“资源争夺”进入“效率与成本博弈”
2026年的推理拐点,不仅是算力需求结构的简单切换,更是AI产业底层逻辑的全面重塑:
从“训练为王”到“推理为王”:行业重心从“造模型”转向“用模型”,推理能力直接决定AI的商业价值落地;
从“资本比拼”到“成本比拼”:一次性巨额训练投入的重要性下降,长期推理成本的控制能力,成为企业的核心竞争壁垒;
从“通用算力”到“专用算力”:低端GPU过剩已成定局,HBM智算芯片、LPU推理芯片、边缘专用芯片,成为市场稀缺资源;
从“单点算力”到“全域算力”:云端智算、边缘算力、端侧芯片协同的分布式架构,成为企业算力布局的主流选择。
未来,AI企业的核心竞争力,不再是“拥有多少张H100显卡”,而是能否在推理时代实现“低成本、高效率、高稳定”的算力运营。当前的“算力荒”,本质已从“有没有算力”的资源短缺,升级为“能不能用好算力”的效率困境。
推理时代的大幕已正式拉开,一场关于算力效率与成本控制的长期博弈,才刚刚开始。