 夜雨聆风
夜雨聆风就在前几天,我做了一个实验。
我用 Midjourney 跑了一张赛博仙侠风的大场景图。提示词是这段,群里流传的"神级壁纸词":
A magnificent floating island above the clouds, ancient Chinese palace complex with curved roofs perched on the edge of a cliff, massive waterfalls cascading down into the mist below, a long stone bridge connecting two floating mountain peaks, cyberpunk neon lights subtly glowing from within the ancient architecture, volumetric god rays piercing through dramatic cloud formations...
出来的构图确实绝了。浮空仙山、云海、石桥、瀑布,该有的全有了。

但光影——怎么说呢,就是差了那么一口气。
提示词里明明白白写了 volumetric god rays(体积光)和 dramatic cloud formations(戏剧性云层),但出来的光柱,更像是天空中淡淡的一层白纱,完全没有那种"神光劈开苍穹"的冲击力。
然后我把这张图拖进了我自己写的一个网页工具里。
拉了两下滑块。
用减淡画笔在建筑窗户上涂了几下。
总共花了不到20秒。
口说无凭,你们自己看效果。


整个过程没有装任何软件、没有开Photoshop、没有连ComfyUI的节点。
就是在浏览器里打开一个网页,拖图进去,拉滑块,涂两下,导出。
20秒。
1
为什么非要后期?AI不是应该直接画好吗?
这是很多人最大的困惑。
你看那些B站爆火的AI仙境图、小红书上的绝美光影写真、甚至通义千问首页推荐的官方模板——清一色都是光影冲击力拉满的。
你就很自然地以为:人家提示词写得好,所以AI直接就出了这种效果。
但实际上,这里面有一个圈子里不太有人公开说的事情。
如果你画的是人像写真,提示词加上 dramatic lighting 之类的强光词,确实能出很惊艳的效果。
因为AI模型在训练的时候,吃了大量的影棚人像摄影作品——那些照片本身就有着精心打过的侧逆光、轮廓光。模型对"人+强光"这个组合,有着极其深刻的"记忆"。
但如果你画的是大场景——比如浮空仙山、赛博都市、废土荒原——情况就完全不一样了。
想想看:现实世界里,有摄影师拍过"悬浮在云海上方的仙侠宫殿,头顶的丁达尔光柱穿透几公里厚的云层"这种照片吗?
当然没有。这是纯虚构的。
模型的训练数据里,这类"宏大虚构场景 + 完美体积光"的高质量样本,跟人像摄影比起来少太多了。它能把构图拼出来,但在这种空间尺度上对光影的把控,远不如人像那么精细。
所以它给你的光,永远是那种"安全的、不犯大错的、但也毫无激情的"中庸状态。
你想让它更猛?改提示词?
改了一百遍,光还是那个样子。但构图可能已经被你改崩了。
这就是大场景光影的死结:提示词能控构图,但控不了光的精度。
2
"那即梦不是可以图生图加光吗?"
有人可能会说:现在不是有即梦、通义万相这些工具吗?上传一张底图,写一句"加上从左上方射入的丁达尔光",AI不就自动帮你加了?
试过的人都知道,这里有一个非常恼火的问题。
你写"左上方45度的强逆光"。
AI理解的"左上方45度"——和你脑子里想的那个位置?
完全不是一个地方。
你写"光柱落在宫殿屋顶上"。
AI可能把光打到了旁边的石桥上。
你想让光再弱一点,把"强烈的"改成"柔和的"。
但"柔和"是原来的几成?三成?五成?说不清楚。
文字,天生就是模糊的。
你没法用一句话精确到"光源位于画面横轴68%的位置,光束宽度占15%,透明度从100%线性衰减到0%"。
但光影效果的好坏,偏偏就藏在这些参数里。
3
不用描述,用手调

我的解决方案很简单粗暴:
不跟AI用文字谈判。直接用滑块和画笔,自己决定光打在哪。
用纯前端代码(HTML + JavaScript),写了一个网页工具。浏览器打开就能用,不装任何东西。
我把它叫做「玄幻光影调整工具」。
三个核心功能,一个一个来看。
1
丁达尔光效(滑块控制)
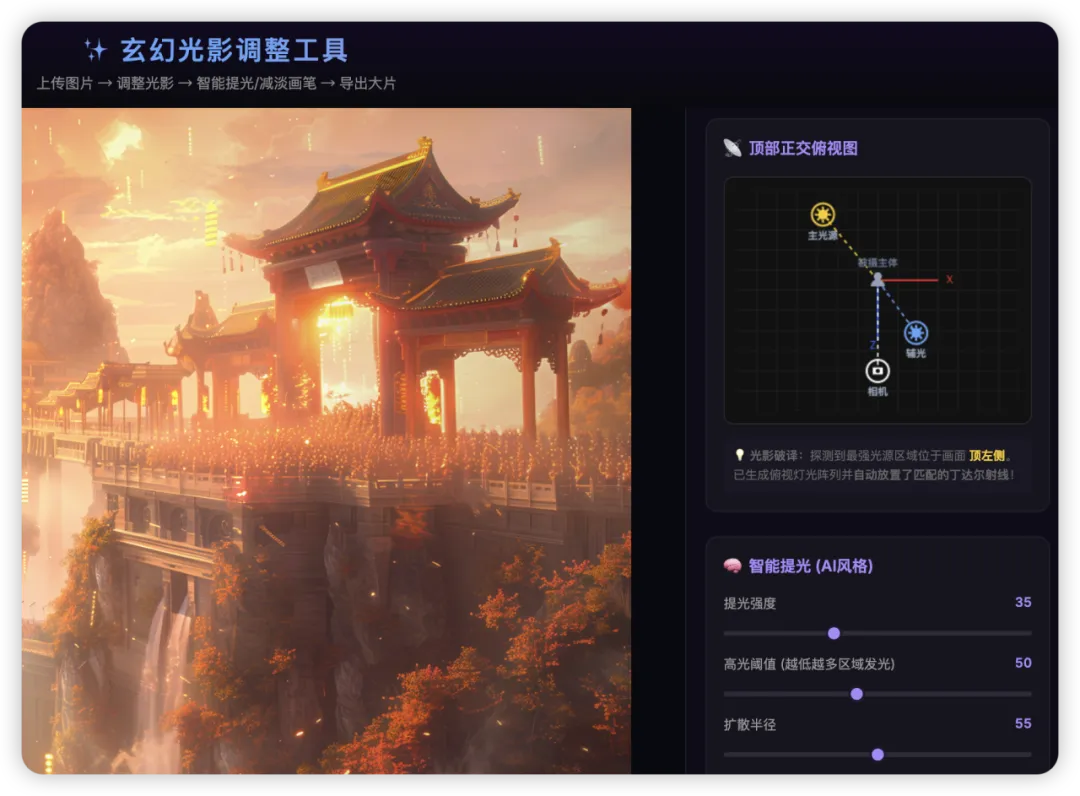
拖进一张底图,拉四个滑块:光的强度、条数、宽度、偏转角度。
代码会生成一组具有梯形衰减的渐变光束(模拟真实丁达尔光从光源到远处的自然变弱),用Canvas的滤色模式融合进原图。
你觉得光太多了?往回拉一点。角度不对?转一下。
所见即所得。不用猜。
2
减淡画笔(局部提亮)

有时候你不需要一整道大光柱,你只需要某个局部更亮一点。
比如漫剧里角色手中的神剑需要发光,或者赛博朋克建筑的窗户需要透出暖光。
开启减淡画笔,在那个位置涂两下。
它的底层逻辑不是"拿白色画笔盖上去"——那样看起来就像一块胶布。
它是对每个像素做基于原色的加法运算(R' = R + (255-R) × dodgeAmount)。说人话就是:它把你涂的地方的原有颜色往更亮的方向推,但保留了原始色调。
所以涂出来的效果,看着像真的有一盏灯照在了那个位置。不假。
3
光影雷达分析

这个功能我自己用得最多。
你刷B站的时候看到一张大神的场景图,觉得光影氛围特别好。但你说不出那道光到底是从哪个方向打过来的。
把那张图拖进来,点击"雷达分析"。
工具会把图片极度缩小,找到亮度最集中的区域,然后在一张俯视图上标出大致的主光源方向。
叠个甲: 这是纯2D像素亮度分析,不是3D光线追踪。它有时候会把高反光的水面误判为光源。它给的是一个大致方向参考。
但就是这个大致方向,已经比你盲猜好太多了。
根据雷达分析的结果,工具会自动预设一个对应角度的丁达尔光效。你在这个基础上微调就行。
4
到这里,少年,你已经完全掌握了
总结一下操作流程:
第一步:用MJ/FLUX跑一张底图。提示词专注写构图和内容,不用纠结光影词。
第二步:打开浏览器,进入工具页面,把底图拖进去。
第三步:拉丁达尔光效滑块,加上主光源。
第四步:用减淡画笔,给关键位置点缀高光。
第五步:导出。完事。
整个流程,20秒到1分钟。
但是,还没完
到现在为止我讲的都是"怎么用"。但在这件事里,有一个更值得想的问题。
为什么"光影感强"的图就是能火?
这不是玄学。这有生理学基础。
人类几十万年的进化里,光线直接关联着生存——光意味着视野、意味着安全、意味着能发现猎物和躲避掠食者。大脑对高对比度的强光信号有一套本能的奖赏机制。
说人话就是:看到一道从天上劈下来的光,你的大脑会分泌多巴胺,就是让你觉得爽的那个东西。
美学心理学里把这种反应叫"崇高感"(Sublime)——面对远超自身尺度的宏大景象时,大脑产生的混合了震撼和渺小感的情绪。
所以那些AI仙境图的光柱,不是装饰。
它是一个精准的多巴胺触发器。
这也是为什么游戏大厂把体积光做成了标配。米哈游在《原神》璃月港做的黄昏光影、腾讯在《王者荣耀世界》里用体积光做叙事——他们不是在做特效,他们是在操控你的神经。
而现在,同样的手段,你用一个浏览器就能做到了。
5
写在最后

在接触AI绘画之前,我一直觉得"打光"是属于专业摄影师和影视灯光师的活。
那是一门需要几年经验、大量器材、对光线物理有深刻理解的手艺。
但AI时代改变了一件事。
构图和光影被解耦了。
以前你在片场拍照片,构图和光影是绑死的——相机移了一寸,光就全变了。
但现在,AI帮你把构图画好以后,光影变成了一个可以独立调整的图层。
这意味着什么?
"打光"这件事的门槛,被压扁了。
你不需要成为灯光师。
你只需要知道:这张图的哪个位置,需要亮一点。
剩下的,交给工具。
🌐 在线直接用(浏览器打开即可):https://efabc5a0.main-8o1.pages.dev
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,
如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。

