 夜雨聆风
夜雨聆风大家好,我是IT周瑜。
今天跟大家聊聊企业级 AI Agent 开发中那些容易踩的坑。
很多团队都有这样的经历:Demo 阶段,Agent 跑得飞起,老板看了直点头。一上生产环境,各种问题接踵而至:Token 账单暴涨、Agent 开始胡说八道、用户投诉响应太慢、出了问题完全查不到原因。
Demo 能跑通,不代表生产能用。 这中间的差距,就在于有没有把这 8 件事想清楚。
一、场景边界:别什么都让 Agent 做
很多团队一上来就想搞一个"万能 Agent",客服、推荐、报表生成、审批流程全往里塞。结果呢?每个场景都做得半吊子,最后没有一个能用的。
Agent 不是万能的。 它适合的是那些决策路径多、需要外部信息、规则难以穷举的场景。比如智能客服、数据分析、代码审查这类任务,路径不确定,传统规则引擎很难覆盖,Agent 的优势就出来了。
但如果你要做的是高精度计算(比如财务结算)、强合规流程(比如合同审批)、实时性要求极高的场景(比如交易撮合),Agent 反而是累赘。这些场景要么容不得半点错误,要么法规要求每一步可追溯,LLM 天生的不确定性反而成了最大的风险。
先画边界,再写代码。 在动手之前,先回答三个问题:这个场景决策路径是否确定?错误容忍度有多高?是否需要 100% 的可解释性?如果前两个答案都是"确定"和"很低",那老老实实用规则引擎可能更靠谱。
二、模型选型:不是越贵越好
"既然上生产了,那就用最好的模型吧。" 这个想法听起来合理,但实际是烧钱的开始。
GPT-5 和 Claude Opus 4.6(4.7刚出了) 确实强,规划、推理、复杂任务处理都没话说。但问题是,不是每一步都需要这么强的模型。Agent 的一次任务执行通常包含规划、工具选择、结果解析等多个步骤,如果每一步都用旗舰模型,Token 成本会非常惊人。
更聪明的做法是多模型路由:
- 规划和推理:用旗舰模型,确保策略质量
- 信息提取和格式转换:用中等模型,速度快成本低
- 简单判断和分类:用小模型甚至规则匹配,没必要动用大模型
在 Spring AI 中,可以为不同的 Agent 步骤配置不同的 ChatModel,通过 ChatClient 的链式调用灵活切换。实际项目中,合理的模型路由策略能把成本压到原来的五分之一甚至更低。
选模型的三个维度:能力够不够、延迟能不能接受、成本划不划算。三个维度综合权衡,而不是一味追求最强。
三、上下文管理:Token 不够用是常态
很多开发者以为上下文窗口 128K tokens 就够用了。但实际上,Agent 的上下文消耗比想象中大得多。
系统提示词、工具描述、历史对话、RAG 检索结果,这些东西叠在一起,很容易就把窗口塞满了。一个有 10 个工具的 Agent,光工具描述可能就要吃掉几千 tokens。再加上多轮对话的累积,128K 真的不经花。
上下文工程才是 Agent 的核心竞争力,不是提示词工程。 提示词写得好只是基本功,真正的挑战在于怎么在有限的窗口里装进最相关的信息。
几个实用的策略:
- 动态工具加载:不要把所有工具描述都塞进上下文,根据用户意图按需加载
- 对话摘要压缩:超过一定轮次后,对历史对话做摘要,保留关键信息丢弃冗余
- RAG 精排:检索到的文档不是全塞进去,做一道相关性过滤,只保留 top-K
- 分层记忆:短期记忆放当前对话,长期记忆用向量数据库存储,需要时再检索
这些策略在 Spring AI 中都有对应的实现方式,比如 Advisor 机制可以用来做上下文压缩,VectorStore 负责长期记忆的存取。
四、工具调用安全:Agent 权限必须有边界
Agent 最大的能力是调用工具,但这也是最大的风险。你的客服 Agent 有查询数据库的权限,用户问了一句"帮我查查所有用户的手机号",如果 Agent 没有权限控制,它可能真的会查出来返回。
工具调用安全要遵循最小权限原则:
- 工具白名单:Agent 只能调用注册过的工具,不能动态执行代码
- 参数校验:入参严格校验格式和范围,防止注入攻击
- 数据脱敏:返回前对敏感字段脱敏处理
- 操作审批:高风险操作必须加入 Human-in-the-Loop
Human-in-the-Loop 是企业级 Agent 的标配。关键节点必须有人工确认步骤。比如数据分析 Agent 生成了删除语句,执行前必须弹给管理员确认。权限沙箱参考 RBAC 的思路,给每个 Agent 分配明确的权限集合,超出范围直接拒绝,别指望模型自己判断。
五、可观测性:出了问题你得能查
传统后端系统出问题,看日志、查链路追踪、定位到具体哪行代码。但 Agent 出问题,你面对的是一个黑盒:它为什么要调用这个工具?为什么选了这个参数?为什么得出了这个结论?一问三不知。
Agent 的可观测性比传统系统复杂得多。 因为它不是按固定逻辑执行,而是每一步都在"思考"和"决策"。你需要追踪的不是代码执行路径,而是决策路径。
具体要记录什么?
- 决策日志:每一步选择了什么工具,为什么选这个,备选项是什么
- Token 消耗:每步用了多少 tokens,累计消耗多少
- 工具调用详情:调了什么接口,传了什么参数,返回了什么结果
- 延迟分布:规划耗时多少,工具调用耗时多少,总计耗时多少
这些信息汇聚起来,就是 Agent 的"决策审计日志"。出了问题,你可以像回放录像一样,一步步看 Agent 当时是怎么想的、为什么做出了错误的决策。
在 Spring AI 中,可以通过 Advisor 和自定义的拦截器来记录这些信息。建议用 OpenTelemetry 做链路追踪,把 Agent 的每一步决策作为一个 Span 记录,这样就能在可观测性平台上看到完整的调用链。
六、成本控制:Token 烧钱比你想象得快
"单次调用才几毛钱,能有多贵?" 这是很多团队上生产前的想法。但 Agent 的成本有一个放大效应。
一次用户请求,Agent 可能要经过规划(1 次调用)、工具选择(1 次调用)、执行工具(0 次调用,但是 API 调用有成本)、结果解析(1 次调用)、自我检查(1 次调用)。一个简单的任务就 4 次 LLM 调用。如果 Agent 遇到错误需要重试,调用量还会翻倍。
日活 1 万用户,每人平均 3 次对话,每次对话平均 4 次 LLM 调用,一天就是 12 万次调用。按 GPT-5 的价格算,一个月的成本相当可观。
成本控制的几个抓手:
- 缓存策略:相似问题的回答做语义缓存,命中缓存直接返回,不走 LLM
- Token 预算:为每个用户/租户设置日消耗上限,超出后降级处理
- 模型降级:非核心路径用小模型,或者高峰期自动降级
- 调用链优化:合并不必要的步骤,减少 LLM 调用次数
一个容易被忽略的点:系统提示词的长度直接影响每次调用的成本。 如果你的系统提示词有 2000 tokens,那每次调用这 2000 tokens 都要付费。精简系统提示词,把固定的指令外置到代码逻辑中,也是一个有效的降本手段。
七、容错与降级:Agent 不靠谱时系统不能挂
LLM 最大的特点就是不确定性。同样的输入,可能给出不同的输出。偶尔还会出现幻觉,一本正经地胡说八道。在企业环境里,这种不确定性是不可接受的。
所以你必须为 Agent 设计完善的容错机制:
- 超时控制:LLM 调用必须设超时,不能让用户一直等着。超时后返回兜底回答或转入人工
- 结果校验:Agent 返回的结果要做格式和内容校验。如果返回的不是合法 JSON,或者数值明显不合理,自动重试或降级
- 重试策略:不是无脑重试,而是带退避的重试。连续失败 N 次后触发降级
- 降级方案:Agent 不可用时,回退到规则引擎或直接转人工。保证业务不中断
企业级系统的核心原则:Agent 是增强,不是替代。 在 Agent 出问题的时候,你的系统必须还能正常运转。就像推荐系统挂了,首页还能展示默认商品列表一样。
在 Spring AI 中,可以用 RetryTemplate 做重试,用 CircuitBreaker 做熔断,用 Fallback 做降级。这些微服务的最佳实践在 Agent 场景下同样适用。
八、评估体系:怎么知道 Agent 表现好不好
传统软件测试有明确的断言:输入 A,期望输出 B,不符就报错。但 Agent 的输出是开放的,同一个问题可能有多个合理答案,你怎么判断它答得好不好?
Agent 的评估需要一套全新的体系:
- 准确率:Agent 的回答是否正确(需要人工标注或用 LLM-as-Judge)
- 完成率:用户交给 Agent 的任务,有多少比例能顺利完成
- 成本效率:完成一个任务平均消耗多少 tokens,花了多少钱
- 用户满意度:用户主观反馈,NPS 评分
其中比较有意思的是 LLM-as-Judge 的做法:用另一个强模型来评估 Agent 的输出质量。虽然不是 100% 准确,但在大规模评估场景下,比人工标注效率高很多。
还需要建立 A/B 测试框架。修改了提示词、换了模型、调整了工具列表,这些变更对 Agent 表现有什么影响?必须通过 A/B 测试来量化。不能靠"感觉好像好了一点"来做决策。
没有评估体系,所有的优化都是在瞎折腾。
建立评估数据集,定期跑评估,根据数据做决策,这才是一个成熟的企业级 Agent 项目该有的样子。
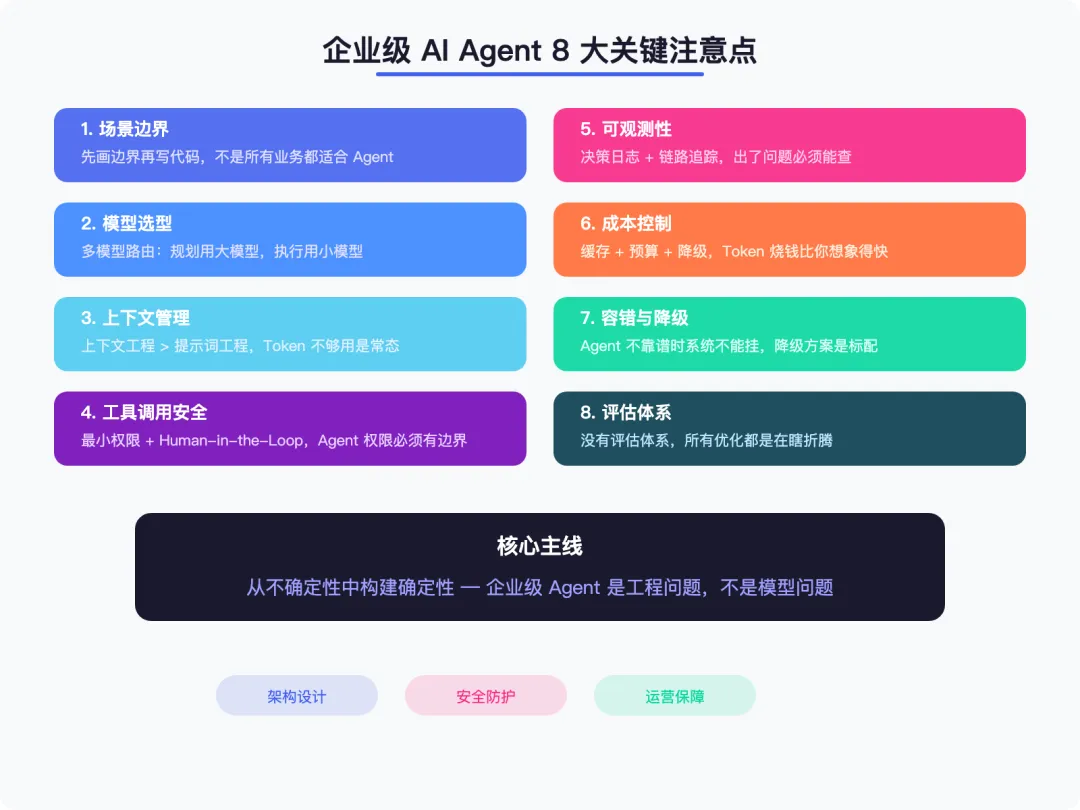
▲ 8大注意点全景图
- - - - - - - - - -
写在最后
回顾这 8 件事,其实背后有一条主线:Agent 开发的本质,是从不确定性中构建确定性。
LLM 本身是不确定的,但通过场景边界限制、权限控制、容错降级、评估反馈这些工程手段,我们可以让 Agent 在企业环境中可靠运行。
记住,企业级 Agent 是一个工程问题,不是一个模型问题。模型会越来越强,但工程上的这些关注点,不会因为模型升级而消失。
你对开发企业级 AI Agent 还有什么疑问?或者在实际项目中遇到过什么坑?欢迎在评论区聊聊。
如果觉得这篇文章对你有帮助,欢迎关注我的公众号: IT周瑜,后续会持续分享 AI Agent 实战经验。
- - - - - - - - - -
如果你想系统学习AI,我有两个VIP课程推荐给你:
《零基础手写AI Agent》——课程现在包含五大框架和十大实战,再加上提示词工程和上下文工程等理论专题,理论+手写+实战,课程内容相当丰富,只要会Java+Spring就能学,帮你成为AI Agent开发工程师。详细了解:零基础手写AI Agent
《零基础手写大模型》——课程现在包含学习神经网络、NLP、Transformer、GPT、BERT、DeepSeek、Stable Diffusion、强化学习等主流技术,通过理论+手写+实战,帮你彻底搞懂大模型底层原理,会编程就能学,课程会教必要的Python和数学基础。详细了解:零基础手写大模型
两个课程都持续更新,现在报名后续新增内容免费学。想咨询或报名的同学可以扫码联系我。
▲ 微信二维码
