 夜雨聆风
夜雨聆风“ 副标题:很多AI系统把这两个概念混在一起,结果系统越用越乱
引言:一个容易被忽视的设计错误
在给AI运营助手设计存储层的时候,很多人会做一个看似合理的决定:
“ "把所有信息都存到一个地方,需要的时候统一检索就好了。"
这个决定,会让系统在早期运行良好,但用了三个月之后开始出问题——
用户发现助手会把"手册上的标准值"和"某次修正的临时记录"混在一起给出建议,搞不清楚哪个更可信;也不知道一条信息是专家确认过的,还是某个用户随手说的。
问题的根源,是知识和记忆被混在了一起。
这篇文章,把这两个概念彻底讲清楚。
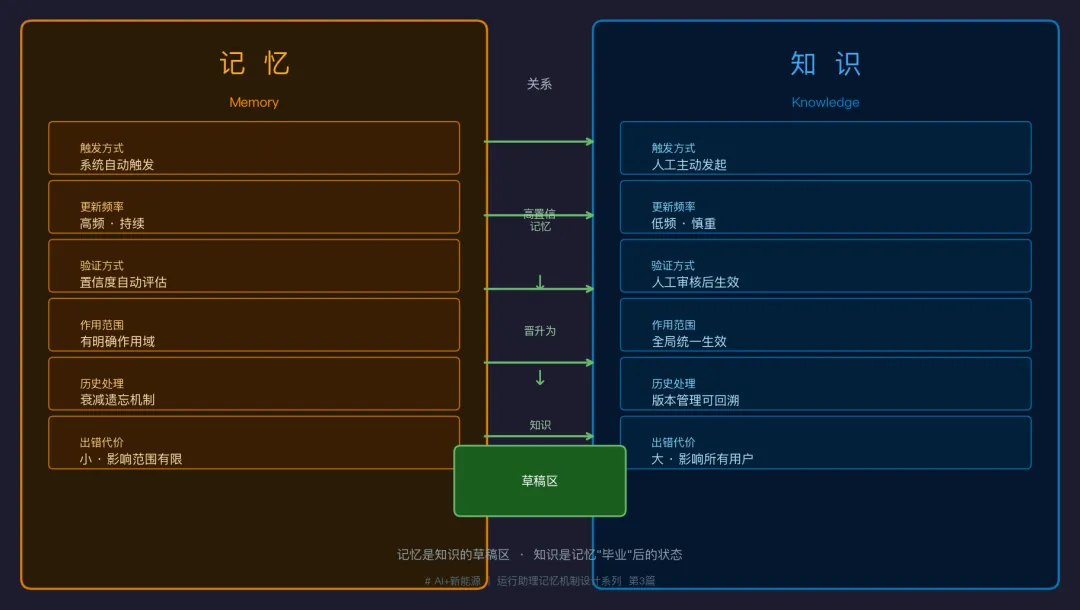
一、本质区别,一句话说完
知识 = 已经被确认为"真"的事实,供所有人共用
记忆 = 在使用过程中积累的"经验",带有来源和置信度
打个比方:
知识:教科书上写的内容——客观、共享、相对稳定 记忆:老师傅脑子里的经验——来自实践、个性化、动态变化
在新能源运维场景里:
| 知识 | 记忆 | |
|---|---|---|
| 是什么 | SL2500主轴温度标准阈值80℃ | 张工反馈马一风场75℃就需要关注 |
| 来源 | 机型手册、厂商标准 | 用户交互、现场反馈 |
| 可信度 | 高,经过验证 | 待定,需要持续验证 |
| 作用范围 | 所有用该机型的场站 | 马一风场,或仅限3号机 |
| 稳定性 | 相对稳定 | 动态变化 |
二、两者的关系:记忆是知识的"草稿区"
知识和记忆不是平行关系,而是有明确的流向:
知识库
│
│ 为记忆提供初始锚点
│ 没有知识,记忆无从比较"这条经验是偏差还是规律"
↓
记忆系统
│
│ 在知识基础上积累偏差和修正
│ 高置信度的记忆,可以反哺知识库
↓
知识库更新
一个具体例子:
初始状态:
知识库 → SL2500主轴温度阈值 = 80℃
记忆系统 → 空
张工反馈75℃有问题:
知识库 → 不变,仍然是80℃
记忆系统 → 写入修正记忆,置信度0.5,作用范围:马一风场
同场站3台机都验证了75℃有问题:
知识库 → 不变
记忆系统 → 置信度升至0.8,固化为场站稳定规则
其他场站5个同机型也确认:
知识库 → 进入更新候选队列,专家审核
记忆系统 → 候选记忆提报"可能是L1级偏差"
专家审核通过:
知识库 → L1机型经验层更新为75℃
记忆系统 → 清除L2中的重复记忆(已被知识覆盖)
核心逻辑:记忆是知识的草稿区。草稿被验证足够多次,才有资格"毕业"成为知识。
三、更新机制的五个核心差异
这是最重要的部分。知识和记忆不能用同一套更新机制,原因如下:
差异一:触发方式
知识更新 → 人主动发起(专家决定改规则)
记忆更新 → 系统自动触发(每次交互就更新)
知识的改动影响所有用户,必须是慎重的主动决策。记忆是个人经验积累,应该无感知地自动发生。
差异二:更新频率
知识更新 → 低频、慎重(一个月改几次)
记忆更新 → 高频、持续(每次对话都在更新)
差异三:验证要求
知识更新 → 需要人工审核确认,改完才全局生效
记忆更新 → 系统自动评估置信度,达到阈值才固化
知识一旦更新就覆盖全局,错了代价很大。记忆可以带着不确定性存在,在验证中逐步提高可信度。
差异四:作用范围
知识更新 → 全局生效(改了所有人都用新的)
记忆更新 → 有明确作用域(用户级/场站级/机组级)
这也是为什么知识更新要格外谨慎——它没有范围限制。
差异五:历史处理
知识更新 → 版本管理(旧版本保留,可回溯)
记忆更新 → 衰减机制(旧记忆权重降低,逐渐淡出)
知识的历史版本有意义(可以看"这条规则是什么时候改的")。记忆的旧内容没有永久保留的必要,自然遗忘就好。
四、对比表
| 维度 | 知识更新 | 记忆更新 |
|---|---|---|
| 触发方式 | 人主动发起 | 系统自动触发 |
| 更新频率 | 低频、慎重 | 高频、持续 |
| 验证要求 | 人工审核后生效 | 自动评估置信度 |
| 作用范围 | 全局生效 | 有明确作用域 |
| 历史处理 | 版本管理,可回溯 | 衰减机制,自然遗忘 |
| 冲突处理 | 新版本覆盖旧版本 | 多条并存,按置信度加权 |
| 错了代价 | 大(影响所有人) | 小(作用域有限) |
五、什么情况该存知识,什么情况该存记忆
设计系统时,最常见的判断困惑是:这条信息,该放哪里?
一个简单的判断框架:
存知识,当满足以下条件:
经过验证、可推广到同类场景的规则 有明确来源(手册/专家/多场站确认) 需要全局统一使用的内容
存记忆,当满足以下条件:
单次交互中产生的观察 还没被验证的修正建议 有特定作用域(某场站/某用户/某机组) 处于中间状态(待验证、置信度不够高)
核心原则:
记忆是知识的"草稿区"
知识是记忆"毕业"后的状态
六、混在一起会出什么问题
如果知识和记忆不做区分,存在同一个地方:
问题一:可信度混乱 "手册标准值"和"用户随口说的"被等同对待,助手不知道该信哪个。
问题二:范围失控 某个只适用于马一风场3号机的修正,被错误地应用到全系统所有同机型机组。
问题三:更新冲突 自动更新的记忆频繁覆盖需要稳定的知识,系统越用越不稳定。
问题四:无法溯源 出了问题不知道是哪条信息导致的,也不知道这条信息是谁写的、什么时候写的。
总结
知识 → 确认为真,全局共用,人工慎重更新,版本管理
记忆 → 经验积累,作用域明确,自动高频更新,置信度衰减
关系 → 记忆是知识的草稿区,高置信记忆可以晋升为知识
原则 → 两者必须分层存储,不能混在一起
把知识和记忆分清楚,是AI运营助手能"越用越好用"而不是"越用越乱"的基础设计决策。
系列文章回顾:
第一篇:AI运营助手记忆机制全景建模[1] — 五种记忆类型 + 四大职责增益设计 第二篇:测点知识四层分层与修正记忆设计[2] — L0基线到L3机组个例,修正如何传播 第三篇(本篇):知识与记忆的本质区别和更新机制
