 夜雨聆风
夜雨聆风“每次看到 API 账单,我都在想:这只小龙虾是不是在背着我偷偷开 Party?”
我盯着监控面板上跳动的 Token 计数器,突然意识到一个残酷的事实,这个月的 API 费用已经超过了服务器租金。OpenClaw 确实很强大,但它就像一台没装油表的跑车,你永远不知道什么时候会在半路抛锚。这篇文章写给所有正在为 Token 账单焦虑的技术人。
⭐点击『极客精益』→『……』→ 设为星标,觉得不错就点赞👍分享🔄推荐❤️
01. 狂欢散场后的账单
OpenClaw 火了。
GitHub 上 35.9 万星标(截至今日),技术社区里到处都是「小龙虾改变了我的工作方式」这样的赞歌。极客们兴奋地展示着它如何自动写代码、处理邮件、生成报告。那段时间,仿佛每个开发者都拥有了一个 24 小时在线的超级助手。
但狂欢总会散场。
OpenClaw 真正进入企业级生产环境后,那些被技术光环掩盖的问题开始一个个浮出水面。最直接、最刺痛神经的,就是 Token 消耗失控。
说白了,OpenClaw 为了维持智能体的长期记忆和复杂规划能力,每次和 AI 大模型交互时都会传输海量的冗余上下文。就像一个健忘的人,每次对话都要把之前说过的话全部重复一遍。更要命的是,错误重试时,智能体会持续地和 AI 大模型进行输入输出操作。
想象一下:你雇了一个助手,他每次汇报工作都要从公司成立的历史开始讲起。讲完还要把所有可能用到的工具说明书背一遍。这就是 OpenClaw 的 Token 消耗现状。
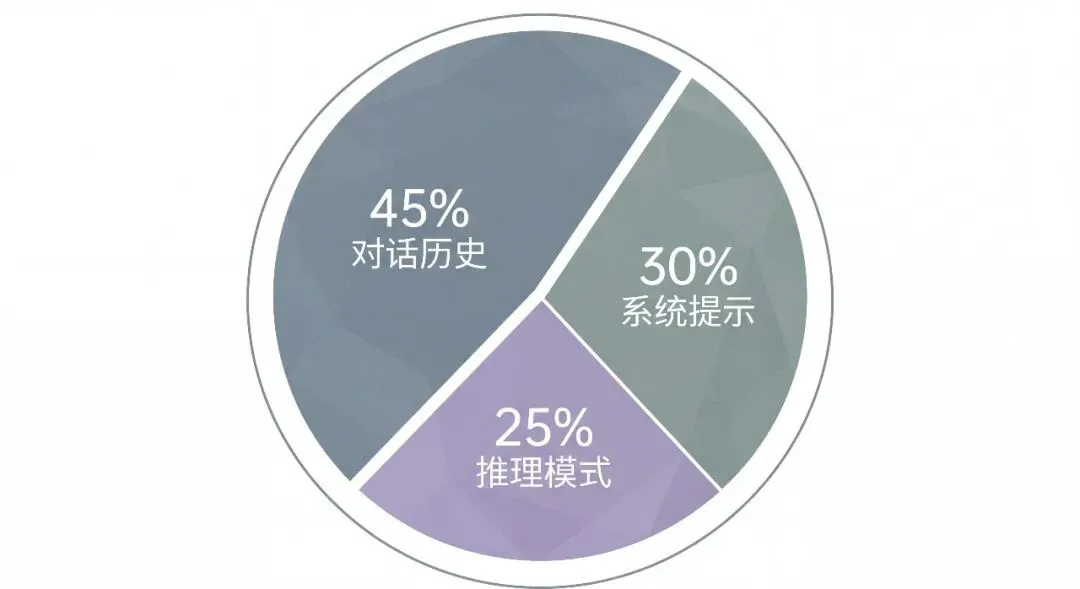
数据不会说谎。根据实测,OpenClaw 的 Token 消耗主要集中在三个「重灾区」:
• 对话历史累积占 40-50% • 系统提示词重复发送占 25-30% • 推理模式产生的中间 Token 占 20-25%
一个典型的 30 轮对话场景,每次请求可能携带 4,000-6,000 个 Token 的历史上下文。如果使用 Claude 3.5 Sonnet(输入 $3/百万 Token),日均 1,000 次请求的月成本能达到 $1,350。
这还只是 API 费用。服务器、运维、人力还没算。
关于 OpenClaw 的安全问题,36% 的插件恶意代码检出率、ClawHavoc 供应链投毒事件,这些我就不再重复念叨了。今天咱们只聊一件事: 如何控制 Token 成本。
02. 找到那些“吞金兽”
要省钱,得先知道钱花在哪儿了。
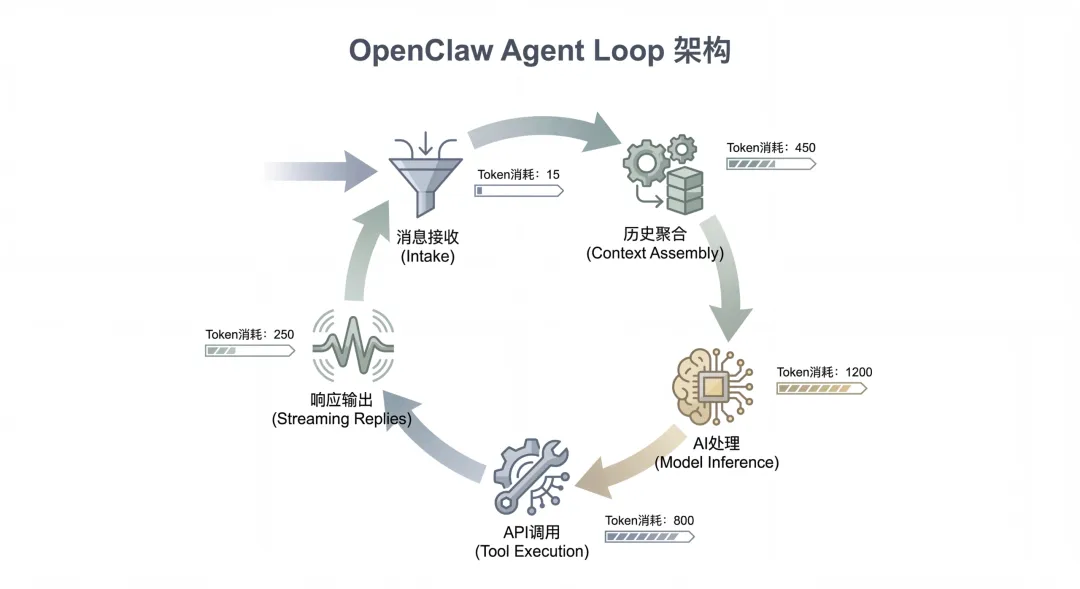
OpenClaw 的运行生命周期包含 5 个核心阶段:入站消息处理(Intake)、上下文组装(Context Assembly)、模型推理(Model Inference)、工具执行(Tool Execution)、流式回复输出(Streaming Replies)。Token 消耗主要发生在前三个阶段。
第一只「吞金兽」:持久化会话历史
OpenClaw 遵循「全记忆」设计哲学。
大语言模型本质上是无状态的,一旦返回结果就会「遗忘」前序指令。为了打破这个限制,OpenClaw 在内存或外部数据库中维护了一套极其复杂的会话状态树。每次用户发送新指令时,网关会将对话开始以来的 所有历史消息 、系统角色设定、环境观察结果全部打包,前置拼接在当前指令之前,形成一个庞大的输入负载发送给模型。
这就像你每次问朋友「今天吃什么」,他都要先回顾一遍你们从小学到现在的所有聊天记录。
对话轮次累加,输入 Token 数量呈现线性甚至二次方增长。任务后期的每一次微小交互,系统都需要为数万乃至数十万的前置冗余 Token 支付高昂的推理运算费用。
第二只「吞金兽」:工具调用 Schema 描述文件
OpenClaw 之所以被称为「有手有脚」的智能体,是因为它内置了极其丰富的工具系统。
为了确保大模型能够准确理解并合乎规范地输出调用这些工具的 JSON 指令,OpenClaw 必须在 System Prompt 中硬编码注入所有可用工具的详尽描述(即 JSON Schema)。这些 Schema 不仅包含工具的名称与功能概述,还必须涵盖极其详细的参数数据类型、枚举值域限制、回调数据格式规范以及严苛的权限黑白名单约束。
系统提示词由多达 12 个动态组件实时组装而成,包括工具列表、技能元数据、自我更新说明、工作区引导文件(AGENTS.md、SOUL.md、TOOLS.md 等)、当前时间、回复标签配置、运行时元数据等。整体注入内容受 bootstrapTotalMaxChars 限制,默认 60,000 字符,大约 15,000-20,000 个 Token。
企业级场景中,一次任务可能挂载了数十个甚至上百个工具 API。这些静态的 Schema 描述动辄占据数千个 Token 的篇幅。缺乏底层缓存机制的情况下,每一次模型交互循环都会将这数千个静态 Token 重新送入 Transformer 网络进行成本极高的自注意力矩阵乘法运算。
单次发送量通常在 5,000 至 10,000 Token 之间。占总消耗的 25-30%。
第三只「吞金兽」:多轮规划与反思的上下文堆叠
OpenClaw 在处理模糊或多步业务逻辑时,不会直接给出最终答案。它会在后台启动一系列的内部思考与验证循环。
模型先生成一个执行计划(Plan),然后调用工具执行第一步(Action),获取工具返回的系统日志或数据(Observation),接着生成关于当前状态的反思结论(Thought),再据此规划下一步行动。为了保持决策的连贯性,每一个后续步骤都必须将其之前所有步骤的 Action、Observation 和 Thought 完整包含在输入序列中。
假设一个复杂任务经历了十个内部反思步骤,那么最初的计划内容将被重复计算十次。中间的每一步执行结果也随之产生多次重复计费。
启用推理模式时,模型会在生成最终回复前进行「思考」,输出详细的中间推理步骤。对于复杂任务,这些中间推理可能产生 10,000 至 50,000 个 Token。是最终回复长度的数倍甚至数十倍。
03. 系统性优化:不是砍功能,是做减法
知道了 Token 消耗的「大户」,接下来该思考如何解决。
我说的不是粗暴地砍掉某些功能。就像减肥不是截肢,优化 Token 消耗也不是阉割智能体的能力。咱们要做的是精准的「减法」。去除冗余,保留精华。
策略一:动态上下文裁剪 + 滑动窗口
传统 OpenClaw 是「笨笨地」将历史会话记忆静态装瓶。
动态上下文裁剪的核心思想是:不是所有历史消息对当前任务都具有同等重要性。根据用户意图动态裁剪适合本次意图的历史记忆信息,而不是无脑全部携带。
这让我想起了 Claude Code 的 Auto Dream 机制。将更早时间的会话历史记忆进行浓缩和提炼,而不是简单丢弃。
滑动窗口机制更直接:将获取的会话历史记忆的时间窗口控制在一个范围内,只保留最近 N 轮的详细交互日志。超出窗口的历史内容进行异步的轻量级摘要浓缩,能够将 Agent 内部循环的 Token 规模始终控制在一个可预测的常数范围内。
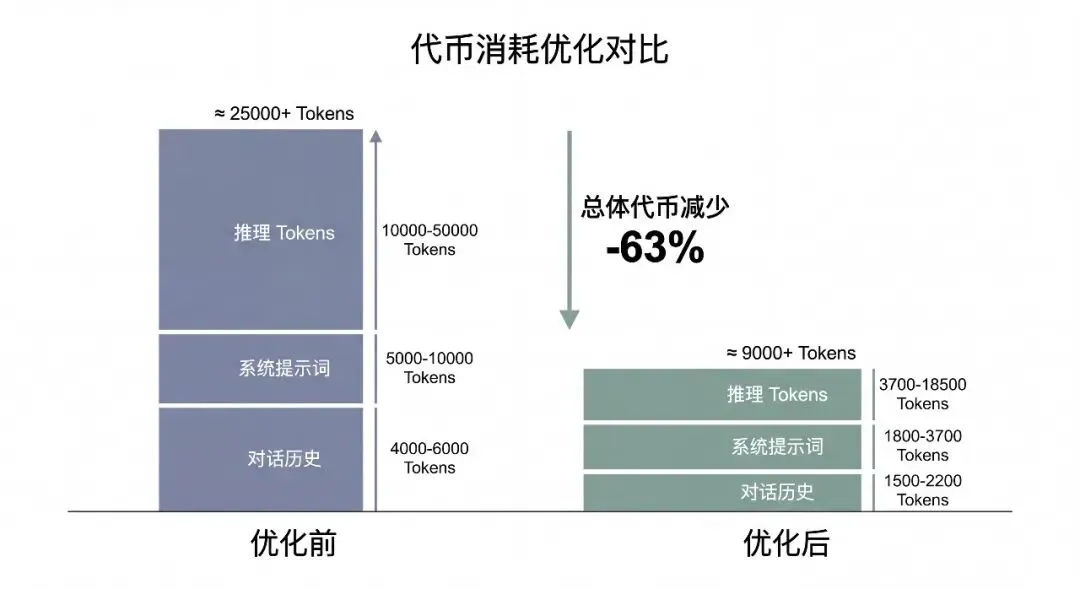
实测数据显示,在 30 轮对话场景下,通过滑动窗口裁剪可将每次请求的 Token 数从 4,000-6,000 降至 1,500-2,000。削减约 60%。
更先进的实现采用 LazyLLM 这样的动态裁剪技术。它打破了静态一次性裁剪上下文的传统思路,允许语言模型在不同的生成步骤中,根据注意力机制的实时需求,动态且选择性地计算那些对预测下一个 Token 至关重要的 Token 子集。在多文档知识库问答等典型长上下游任务的压测中,这种动态 KV 选择机制能够使百亿参数级别的模型(如 LLaMA 2 7B)在预填充阶段实现 2.34 倍的速度提升。准确率几乎不发生衰减。
策略二:基于信息熵的提示词压缩
说人话:去除低信息价值的停用词、格式控制符、语法冗余等。这是对信息的修剪和去噪。
微软研究院开发的 LLMLingua 是当前工业界最成熟的实现。它利用小型语言模型(如 GPT-2-small 或 LLaMA-7B)作为「压缩器」,在将提示词发送至目标大语言模型之前,识别并移除非关键 Token。
理论基础很简单:提示词中存在大量冗余信息。如果一个 Token 很容易被辅助模型预测出来(即该位置的信息熵极低),那么它对于维持整体语义完整性的贡献就非常微弱。反之,不可预测的罕见实体词或关键指令则承载了高密度的信息。
在 GSM8K 数学推理数据集上的实测结果:在 20 倍压缩比下,LLMLingua 保留了原始提示词 77.33% 的准确率,性能损失仅为 1.5%。延迟方面,将端到端推理速度提升了 1.7 至 5.7 倍。
这种深度压缩机制更适合应用于那些静态且修改频率极低的全局知识库前置加载环节。而非高并发的实时交互请求中。
策略三:语义路由与分层处理
说人话:在网关层根据输入意图路由到最适合的 AI 大模型和工具。
这就像医院的分诊台。感冒发烧不需要找专家号,复杂手术才需要主任医师。OpenClaw 的默认网关行为是,无论面对简单的天气查询,还是面对复杂的跨表数据库数据核对,系统都会一视同仁地唤醒后端昂贵的大型模型进行意图理解与工具分发。这种「高射炮打蚊子」的设计造成了极大的资源浪费。
引入 Semantic Router 这样专注于 LLM 与 Agent 加速决策的开源中间件,能够构建起一个低延迟(毫秒级)的前置决策防护罩。
工程落地层面,开发团队定义一系列的业务「路由」,例如将内部 IT 系统查询、考勤打卡、日常闲聊等高频标准化请求分别定义为独立的意图通道,并为每个通道配置一组具有代表性的话术样本。然后,网关初始化轻量级的文本编码器,将所有的预设话术映射并固化为高维语义向量空间中的坐标点。
真实用户的请求到达系统边缘时,路由层迅速将其转化为查询向量,并计算其与各个预设路由簇的余弦相似度。若匹配度超过了经过微调优化的系统阈值,该请求将被直接分发到本地确定性的代码逻辑、快速检索数据库或专门微调过的微型模型中进行处理。从而避开了后续漫长且昂贵的重型 LLM 思维链生成过程。
模型分层架构通常包含三个层级:
• 基础层使用 DeepSeek-V3.2(Input $0.28/M)或 Qwen-3.5-Plus 处理简单查询 • 中间层使用 GPT-4o-mini 或 Claude Haiku 处理中等复杂度任务 • 顶层使用 Claude Opus 或 GPT-5系 处理高复杂度任务
典型业务场景中简单任务占比约 45%、中等任务 35%、复杂任务 20%。通过动态路由整体成本可比全部使用高端模型降低约 55%。
策略四:全面深化的缓存命中率提升
说人话:识别不变与变,将不变的用键值对缓存和读取。这样就不用每次都请求 AI 大模型了。
Anthropic 为 Claude 系列模型提供的 Prompt Caching 功能(目前主流的AI大模型都支持这个功能)可将缓存读取成本降低至正常输入价格的 10%。即节省 90% 的费用。
计费模型是这样的:首次缓存写入的成本为正常价格的 1.25 倍(短期缓存,5 分钟 TTL)或 2 倍(长期缓存,1 小时 TTL),但后续缓存命中仅需支付 0.1 倍价格。
对于每日 50 次调用、系统提示词 8,000 Token 的场景,如果 48 次为缓存命中,使用缓存后的月成本可从 5.40。节省 85%。
在 OpenClaw 中启用 Prompt Caching 需要特定的技术配置。必须使用 大模型厂商的原生 API 格式,拿 Antheropic 的为例,需要在系统提示词中添加 cache_control: {type: "ephemeral"} 标记。建议将稳定不变的部分(如核心工具定义、身份配置)标记为缓存,而将频繁变化的部分(如当前时间、动态记忆)排除在缓存外。
这些解决策略都有相应的小模型、算法、中间件等技术配合使用:LLaMA 2 7B、LLMLingua、Semantic Router、向量数据库等。
综合应用这些优化技术,实测综合 Token 消耗可降低约 63%。
04. 技术小白的「快餐」方案
上面的解决策略还是需要一些技术底子。并且知道用什么技术工具才能真正落地。
但对于很多技术小白用户,更关心的是有没有现成的「快餐」。国内的「小龙虾」们,哪些是比较省 Token 的?
我关注的是在安全相对较好的基础上,哪些小龙虾是更省 Token 的。
推荐方案一:DeskClaw
桌面端原生执行,可以利用用户本地端点设备的算力和执行环境。
DeskClaw 以一只在用户屏幕上爬行的小螃蟹形象呈现,核心宣传语「不做网友,做同事」精准界定了其作为数字员工的定位。相较于需要庞大服务器集群支撑的中心化 Agent, DeskClaw 重度依赖用户本地端点设备的算力与执行环境。
优势很明显:
• 本土化生态融合友好,深度兼容飞书、钉钉等国内主流办公协同平台 • 本地算力运行,大幅降低了云端长轮询 API 带来的账单压力 • 启动时间约 2-3 秒,内存占用约 80-120MB
劣势也要说清楚:
• 能力上相对弱些,如复杂推理边界、工具调用稳定性和幻觉率等 • 工具生态不如 OpenClaw 丰富(OpenClaw 有 1700+ 社区技能插件) • 当操作高度复杂的本地非结构化系统环境时,偶发性动作失败的概率存在
适合场景:市场分析、竞品监控、HR 招聘等高度依赖单兵桌面作战的非技术类工种。
推荐方案二:DeepSeek-V3.2 模型
如果你只是想换个更便宜的模型,DeepSeek-V3.2 是不二之选。
定价对比:
• DeepSeek-V3.2: Input $0.28/M(cache miss) / $0.028/M(cache hit)、Output $0.42/M • Claude 3.5 Sonnet: Input $3/M、Output $15/M
便宜 10-50 倍!
对于一个日均消耗 100 万 Token 的中等规模 Agent 应用,使用 DeepSeek 的月成本约 $100-200。而使用 Claude 可能高达 $1,000-2,000。
DeepSeek-V3.2 在底层架构上原生强化了 Agent 生态能力,深度集成了高级的推理与思考逻辑。模型本身在一次前向传播的内部计算中就已经通过内在的 <think> 标签域完成了深度逻辑推演。这意味着你可以抛弃那些为了维持状态而反复拉取历史记录的重型网关,只需编写数百行精简的本地化 Python 调度脚本,直接使用 DeepSeek 的低计费 API。
其他方案简评
Hermes Agent: 最近新兴的,号称能替换小龙虾,比较火。我还没深度测评,晚点再说。
Qwen-Agent: 目前架构最为干净、轻量化程度极高的技术选择之一。核心代码仅 4,000 行,采用宽松且商业友好的开源协议。但需要具备一定研发能力,不是开箱即用的。对于有专职开发团队、愿意投入时间构建定制化系统的团队,这是个好选择。
CountBot: 21,000 行代码规模,「10 秒一键部署」和「无需 Docker」。原生支持钉钉、飞书、QQ、微信个人号等十余个国内主流渠道。适合追求开箱即用、专注中文场景的中小企业。但生态系统相对封闭,社区贡献的技能数量和多样性远不及 OpenClaw。
nanobot: 极简主义的代表。核心代码仅 4,000 行,启动时间 0.8 秒,内存占用 45MB。优势是极致的轻量和可审计性。劣势是功能缺失,不提供内置的浏览器自动化、语音控制、多渠道同步等高级功能。适合预算敏感、技术能力强的初创团队。
Copaw: 阿里出品,企业级安全。所有数据采用 AES-256 加密存储、完全本地留存,支持私有化部署。提供了四层记忆系统和基于角色的访问控制(RBAC)。适合安全合规要求严格的金融、政务、医疗行业。但企业版需要付费。
AutoClaw: 智谱出品,提供了与 OpenClaw 的 API 兼容性,可以在保留生态的同时修复安全漏洞。但继承了 OpenClaw 的运维复杂度。
这些方案各有优缺点。有些需要和云平台、AI 大模型绑定。选择时需要根据自己的技术能力、预算、业务场景综合权衡。
05. 我的真心建议
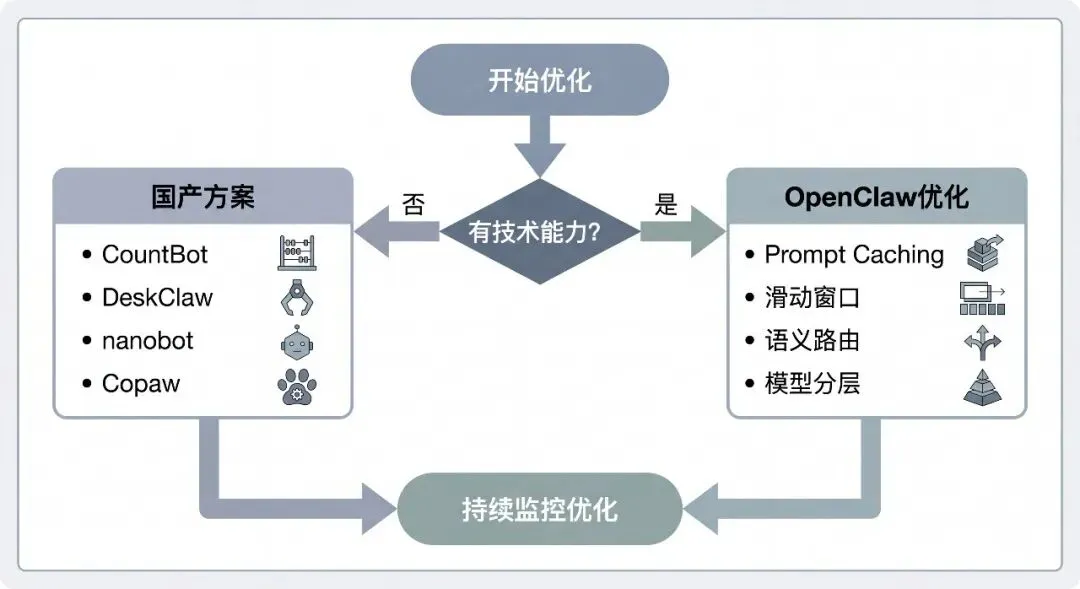
如果你懂或愿意写一些技术,我的建议是: 基于 OpenClaw 进行系统性优化。
为什么?
OpenClaw 的生态系统是目前最成熟的。1700+ 社区技能插件、30 余个 IM 渠道支持、完善的文档和活跃的社区。这些都是国产方案短期内难以追赶的。
而我今天告诉你的系统性解决策略及相关技术选型,动态上下文裁剪、信息熵压缩、语义路由、缓存优化,这些都不是什么黑科技。你让 AI 协助你优化也不难。真的可以试试。
具体怎么做?
立即启用 Prompt Caching: 这是投入产出比最高的优化。配置 Anthropic 等模型厂商的原生 API,在系统提示词中添加缓存标记。对于高频重复任务,这一项就能节省 85% 左右(不同模型会有所不同)的系统提示词成本。
实施滑动窗口机制:在网关层硬性规定只保留最近 N 轮的详细交互日志(N 可以根据任务复杂度设为 5-15)。超出窗口的历史内容进行异步摘要。这能将对话历史 Token 削减 60%(我测试的,环境不同数据会有所不同)。
引入语义路由:使用 Semantic Router 这样的开源中间件,为高频标准化请求(如查询、打卡、闲聊)定义独立的意图通道。简单任务不走大模型,直接路由到本地逻辑或微型模型。
考虑模型分层:不是所有任务都需要 Claude Opus 类这样的顶级模型。简单任务用 DeepSeek,中等任务用 GPT-4o-mini 类,复杂任务才用顶级模型。这能降低 55% 的整体成本(也是我测试的,仅供参考)。
集成 LLMLingua 压缩:对于需要注入大量静态知识库的场景,使用 LLMLingua 进行提示词压缩。20 倍压缩比,性能损失仅 1.5%。
这些优化措施并不复杂。大部分可以在一周内完成。如果你的月 Token 消耗超过 $1,000,这些优化的投资回报率是极高的。
如果你是技术小白,或者团队没有专职开发资源,那就选择一个适合的国产方案:
• 追求开箱即用、本土化集成 → CountBot 或 DeskClaw • 追求极致低成本、愿意折腾 → nanobot + DeepSeek • 企业级部署、安全合规要求高 → Copaw
但无论选择哪条路,都要记住一点: Token 优化不是一次性的工作,而是一个持续的过程。监控 Token 消耗、分析使用模式、调整优化策略,这应该成为 AI 系统运维的常规动作。
尾声
我关掉监控面板,Token 计数器终于不再那么疯狂地跳动。这篇文章写完了。但如果能帮你省下哪怕一点点 API 费用,也算值了。
OpenClaw 很强大。国产方案也在快速进化。技术的进步总是伴随着成本的优化。当咱们学会精准地使用这些工具,而不是被工具牵着鼻子走,AI 才真正成为了咱们的助手。而不是账单上的负担。
省钱不是目的。让 AI 更好地服务业务才是。
共勉。
读者互动:你在使用 OpenClaw 或其他 Agent 框架时,遇到过哪些 Token 消耗的坑?欢迎在评论区分享你的优化经验。如果这篇文章对你有帮助,不妨点个赞或分享给同样在为 API 账单焦虑的朋友。

延伸阅读:
• LLMLingua: Innovating LLM efficiency with prompt compression - Microsoft Research[1] - 微软官方对 LLMLingua 压缩技术的深度解析,值得细读 • Models & Pricing | DeepSeek API Docs[2] - DeepSeek 官方定价文档,看完你会明白为什么它这么香 • OpenClaw vs Nanobot: Which AI Agent Framework Should You Use - DataCamp[3] - 第三方对 OpenClaw 和 nanobot 的详细对比,数据翔实 • Agent Loop - OpenClaw[4] - OpenClaw 官方文档,理解 Agent 循环的必读材料 • QwenLM/Qwen-Agent - GitHub[5] - Qwen-Agent 的开源仓库,极简架构的典范
相关标签:#OpenClaw #Token优化 #AI成本控制 #国产Agent #DeskClaw #DeepSeek #企业级AI
引用链接
[1] LLMLingua: Innovating LLM efficiency with prompt compression - Microsoft Research: https://www.microsoft.com/en-us/research/blog/llmlingua-innovating-llm-efficiency-with-prompt-compression/[2] Models & Pricing | DeepSeek API Docs: https://api-docs.deepseek.com/quick_start/pricing[3] OpenClaw vs Nanobot: Which AI Agent Framework Should You Use - DataCamp: https://www.datacamp.com/blog/openclaw-vs-nanobot[4] Agent Loop - OpenClaw: https://docs.openclaw.ai/concepts/agent-loop[5] QwenLM/Qwen-Agent - GitHub: https://github.com/QwenLM/Qwen-Agent
