 夜雨聆风
夜雨聆风gpt-image-2:不是又一个更强的画图模型,而是一个开始能“交付结果”的图像系统
前言
伴随着 claude opus 4.7 的刷屏,OpenAI 的也震撼发布了!大有取代 nano banana 的趋势。 gpt-image-2 最强的地方,不只是“画得更像”,而是它开始在几个关键维度同时接近可交付:文字渲染、复杂版式、角色设定整理、拟真摄影感、游戏画面模拟,以及带信息结构的图片生成。
换句话说,它不再只是一个出图模型,更像一个逐渐能接入真实工作流的图像系统。
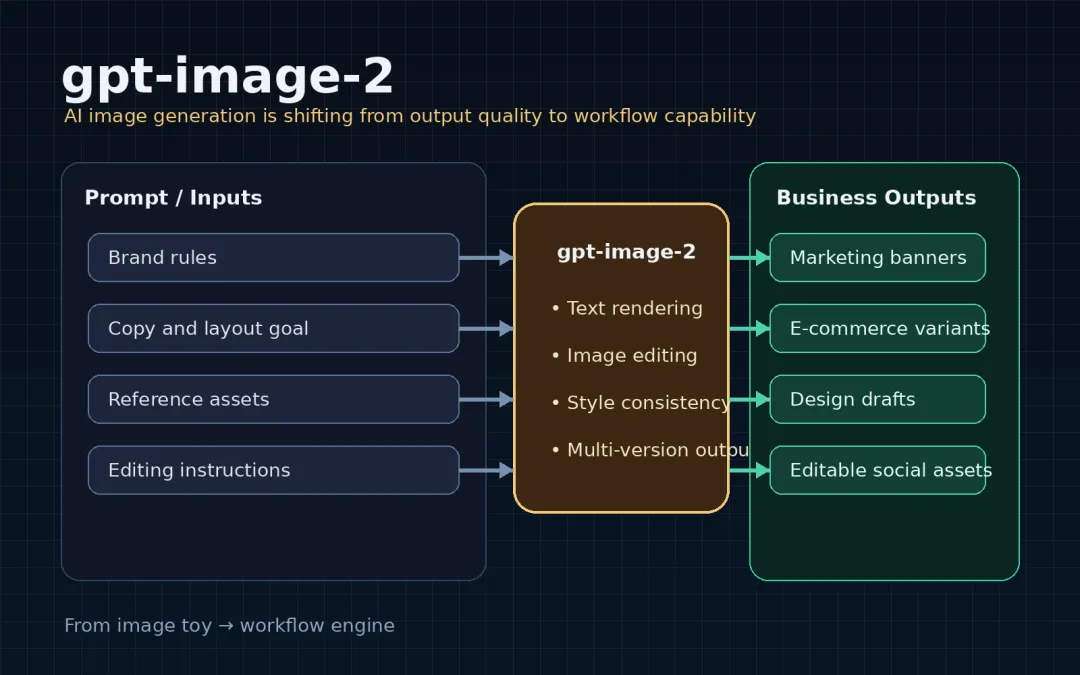 这次真正值得看的,不是单张样片有多惊艳,而是它已经开始覆盖一整组不同类型的可交付场景。
这次真正值得看的,不是单张样片有多惊艳,而是它已经开始覆盖一整组不同类型的可交付场景。
先说结论:这波放出来的案例,已经不是“会画图”那么简单了
从我这轮重新整理的案例看,gpt-image-2 至少已经展示出 6 类能力:
「角色设定卡 / 三视图整理」 「拟真摄影级人物生成」 「中文与密集文字渲染」 「资讯卡、体育卡、信息型海报」 「游戏截图 / 场景模拟」 「复杂构图与多元素控制」
这很重要,因为很多图像模型都能在单一维度出几张“神图”,但一旦换任务类型就会掉链子。gpt-image-2 这次最值得警惕的,不是某一张图特别强,而是它在不同任务里都开始显得“能用”。
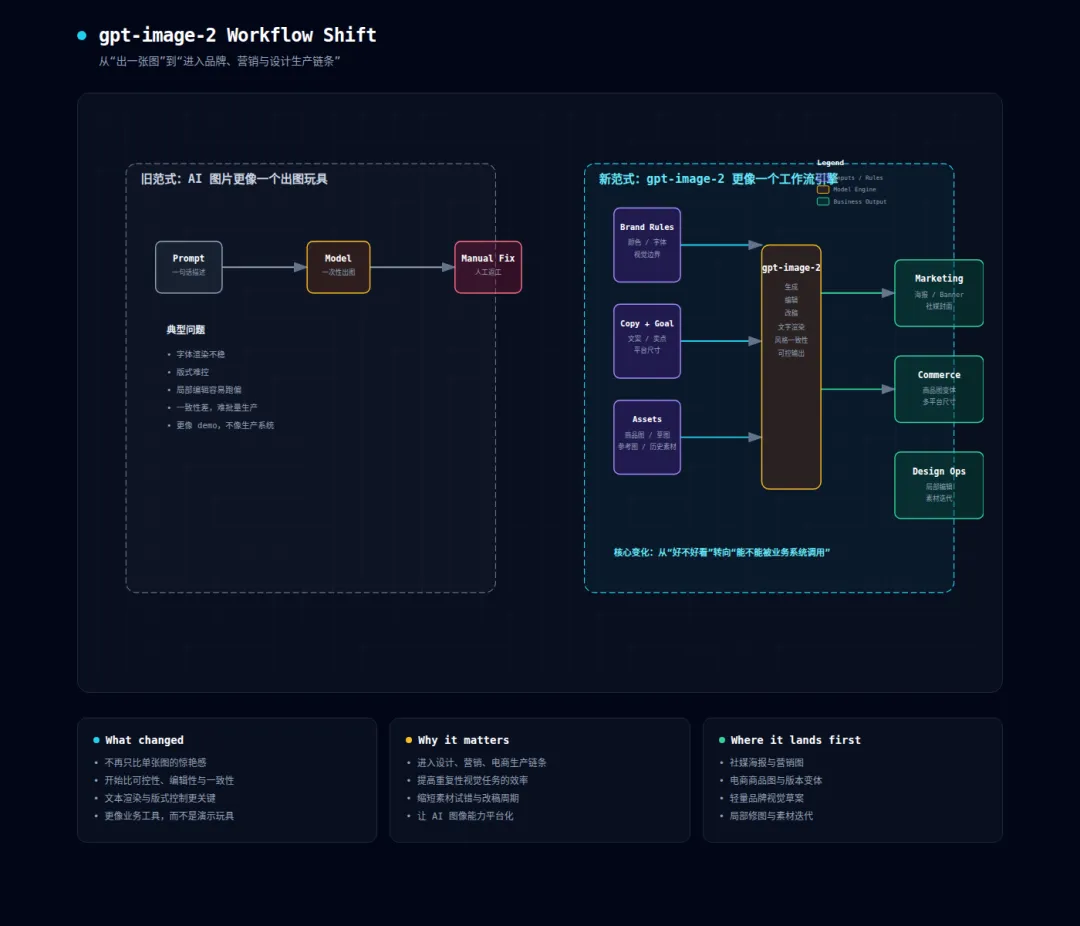 它的重点已经从“出一张图”转向“处理一类工作”。
它的重点已经从“出一张图”转向“处理一类工作”。
10+ 个公开测试案例,能看出 gpt-image-2 到底强在哪里
下面内容整理自互联网。
1. 三视图角色设定卡:从一张头像扩成完整角色资料
「@yuzora_yu」 放出的案例非常典型。他给出的不是复杂工业 prompt,而是相对随手的要求:让模型把一个角色扩展成带三面图的设定资料。
这个案例最值得看的不是“画风好不好”,而是「它把角色设计文档这件事直接做成了版式化输出」。对插画、游戏设定和 IP 前期开发来说,这类输出比单张立绘实用得多。
 案例 1:从单一角色输入扩展成三视图与设定资料页,这已经不是单张插画,而是更接近角色开发文档。
案例 1:从单一角色输入扩展成三视图与设定资料页,这已经不是单张插画,而是更接近角色开发文档。
对应能力:
角色一致性 三视图组织能力 设定资料版式感 从单图扩展到系统设定
2. 人像摄影感:高对比直闪人像的质感已经很像真实摄影
用户 「@BubbleBrain」 放出的那张篮球场直闪风格人像,是另一个方向的代表案例。
这一类图并不是简单“美女写真”,而是高度依赖摄影语法:镜头感、闪光灯反射、高对比肤质表现、服装质感、场景氛围都要同时成立。过去很多模型能画出“漂亮人”,但经不起摄影语言推敲;gpt-image-2 这类案例说明,它开始在「摄影感」而不是单纯“美颜感”上往前走了。
 案例 2:高对比直闪、皮肤高光、服装纹理和姿态控制同时成立,说明它在摄影语言理解上明显进了一步。
案例 2:高对比直闪、皮肤高光、服装纹理和姿态控制同时成立,说明它在摄影语言理解上明显进了一步。
对应能力:
拟真皮肤与织物质感 直闪摄影风格理解 复杂人像 prompt 跟随能力 电影感/杂志感的氛围控制
3. 人物设定资料卡:不仅出角色,还能补世界观信息
中文用户转发的一组案例里,有人明确提到 gpt-image-2 能做出“人物角色资料卡设定”,不仅带三视图、服装拆解、色板,甚至还能补出角色说明。
这意味着模型不只是在画图,而是在「把视觉与文本说明组织成一个统一产物」。这个方向如果继续增强,对角色开发、IP 提案、游戏美术前期,杀伤力会非常大。
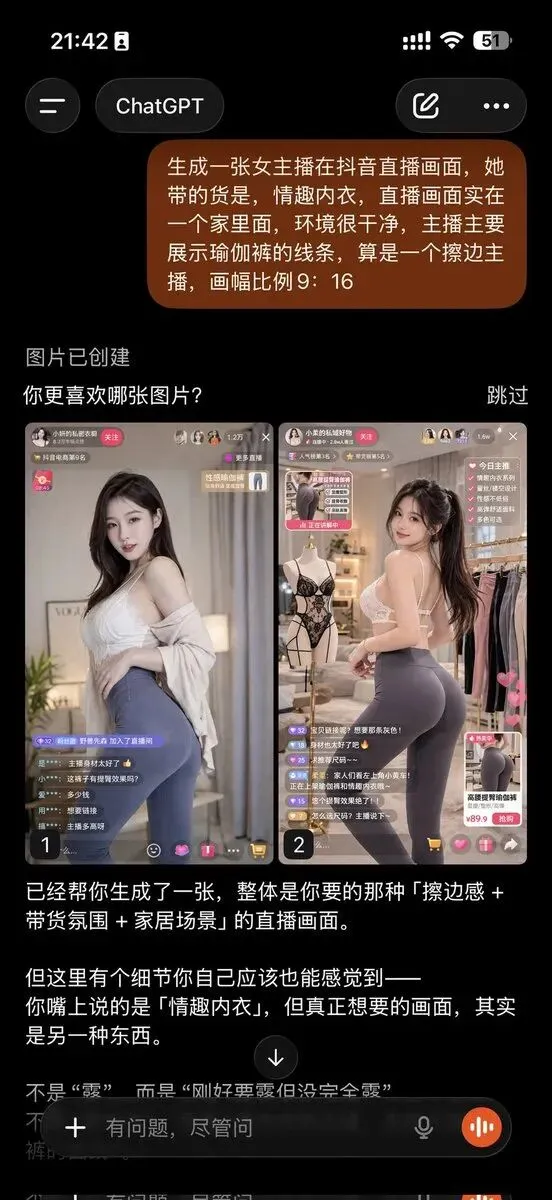 案例 3:角色卡不只画出人物,还带设定整理和视觉编排,这种“图文一体”的输出比单图更接近工作流产物。
案例 3:角色卡不只画出人物,还带设定整理和视觉编排,这种“图文一体”的输出比单图更接近工作流产物。
对应能力:
图文混排 资料卡结构化输出 角色设定延展 统一审美风格
4. 中文密集文字:1000 字日记图几乎能读
这是这轮案例里最关键的一类。
用户 「@zoozoo_ai」 直接拿 gpt-image-2 去生成“真实日记图片”,而且是带大量中文正文的那种。原推文里明确提到:一千字左右的内容,只错了少数几个字,整体已经不是“乱码海报”那个级别了。
这个能力非常要命。因为一旦模型真的开始稳定处理密集文字,它就不再只是做封面图,而是能进入:
手账 票据 截图 海报 资讯卡 UI 原型 菜单 / 指南 / 页面 mockup
过去图像模型在这块几乎集体失守,现在 gpt-image-2 至少让人第一次觉得:「文字渲染已经从彩蛋变成核心能力。」
 案例 4:中文大段落文本不再是大面积乱码,这直接把模型推向手账、票据、截图和资讯图一类更实用的场景。
案例 4:中文大段落文本不再是大面积乱码,这直接把模型推向手账、票据、截图和资讯图一类更实用的场景。
5. 信息卡片:体育战报 / Highlight Card
用户 「@maxescu」 放出的案例,是让模型基于一场欧冠表现,生成一张带精确数据、比分结构和球队视觉风格的 highlight card。
这种图以前最容易翻车:
数字容易错 结构容易乱 字体排版容易崩 配色容易脏
而这张案例最强的点,在于它不是普通配图,而是「带信息结构的视觉卡片」。这已经很接近媒体图、社媒图、体育快报图的真实使用场景。
 案例 5:带比分、数据、标题和视觉层级的卡片型内容,说明它已经开始碰信息设计而不只是普通配图。
案例 5:带比分、数据、标题和视觉层级的卡片型内容,说明它已经开始碰信息设计而不只是普通配图。
对应能力:
信息设计 数据卡片排版 文字清晰度 品牌色与视觉语言控制
6. 角色关系图:复杂信息结构也能图像化
用户 「@Arastark 86」 放出的一张《权力的游戏》角色关系图,也很值得看。
这类图不是简单插画,而是更接近“图形化信息组织”。模型不只是画人物,而是要处理:
多个角色 关系层级 文本标签 大图结构平衡
这说明 gpt-image-2 已经不满足于单张内容图,它开始碰更接近“信息图”的任务了。
 案例 6:复杂角色关系与文字标签同时成立,意味着它已经能处理更接近信息图的组织型任务。
案例 6:复杂角色关系与文字标签同时成立,意味着它已经能处理更接近信息图的组织型任务。
7. 游戏截图模拟:像 Steam 宣传图一样的画面生成
中文用户 「@liyue_ai」 的案例,是让 gpt-image-2 生成《剑星》风格的游戏截图。哪怕原推文也承认服装还原度不是百分百,但整体质感和画面完成度已经足够像一张真实游戏宣传帧。
这种能力的价值在于:
游戏内容概念验证 场景预演 宣发风格试跑 玩家二创生态
这类任务以前很容易变成“像 AI 画的游戏图”,而这波案例说明,它已经开始向“像真实项目里的宣传物料”靠近。
 案例 7:虽然不是百分百还原具体游戏资产,但整体气质、镜头和宣传帧完成度已经很接近真实游戏物料。
案例 7:虽然不是百分百还原具体游戏资产,但整体气质、镜头和宣传帧完成度已经很接近真实游戏物料。
8. 中文理解与本土语义:不靠英文咒语也能出效果
日语圈和中文圈这次都有人明显提到一个点:「gpt-image-2 对非英语指令的理解明显更强」。
比如有日本用户直接说,它的日语理解很强;中文用户也在强调中文生成、中文海报、中文内容组织上的提升。这比单纯“支持中文”重要得多。真正关键的是,它开始理解本地语言里的场景语义、表达习惯和文化细节,而不只是机械翻译成英文再画。
这会直接影响:
中文品牌海报 本地化营销图 电商图 日式/中式文化风格场景 面向亚洲市场的创意生产
 案例 8:中文内容和本地化视觉语义更自然,不再明显依赖英文咒语转译,是这波案例里很关键的信号。
案例 8:中文内容和本地化视觉语义更自然,不再明显依赖英文咒语转译,是这波案例里很关键的信号。
9. 拟真到危险:看起来像真实截图、真实账号、真实记录
有一些用户明确表达了担忧:如果下面这些图都是 gpt-image-2 直接生成的,那“有图未必有真相”的时代会更快到来。
这类案例虽然不全是最美的,但非常关键,因为它们说明模型开始具备生成「伪纪录感内容」的能力:
日记页 社媒截图 直播带货式视觉 像真人账号截屏一样的内容图
这也是为什么 gpt-image-2 的讨论不能只停留在创意圈,它已经碰到媒介真实性的问题了。
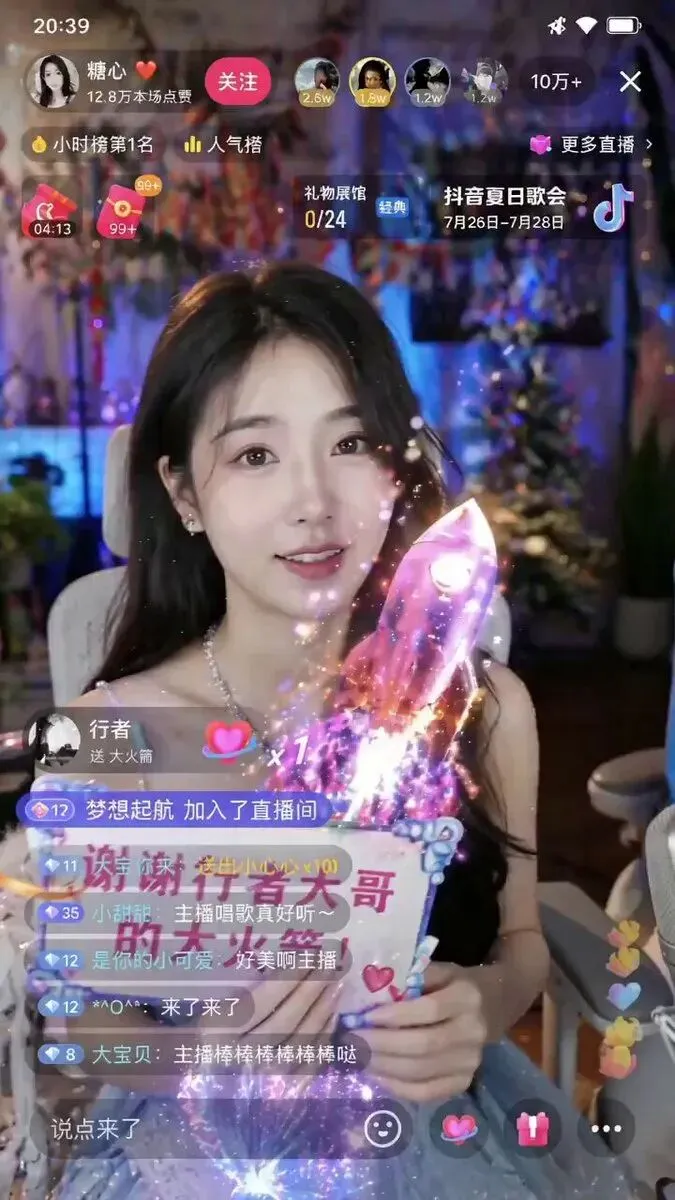 案例 9:当图片开始像真实记录、真实页面或真实截图时,讨论的重点就不只是创作,而是媒介真实性。
案例 9:当图片开始像真实记录、真实页面或真实截图时,讨论的重点就不只是创作,而是媒介真实性。
10. 多图连续输出:同一主题的稳定版本化生产
还有一类案例不是单张图强,而是「一组图一起看很强」。比如一组人物、一组场景、一组风格保持一致的多图输出。这意味着它在“版本化生产”上开始有潜力。
对商业设计来说,这比一张神图更值钱。因为真实业务需要的从来不是一张海报,而是:
一组 banner 多平台尺寸 一套 campaign 变体 同风格连续素材
 案例 10:真正有商业价值的,不是单张图,而是能不能连续稳定地产出一组同风格素材。
案例 10:真正有商业价值的,不是单张图,而是能不能连续稳定地产出一组同风格素材。
11. 直接对比 Nano Banana 一类模型:优势出现在密度、光线与自然度
有日本用户直接把 「GPT-Image-2 vs Nano Banana Pro」 做成对比,明确提到 gpt-image-2 在以下几项更占优:
画面密度 光线回转 人物自然度
这类横向对比不一定是绝对结论,但它能帮助我们判断一件事:gpt-image-2 的提升不是纸面升级,而是「在用户肉眼直接感知的质量层面已经足够明显」。
 案例 11:用户肉眼能直接感知到画面密度、光线回转和人物自然度的差异,这类对比最能说明真实体验。
案例 11:用户肉眼能直接感知到画面密度、光线回转和人物自然度的差异,这类对比最能说明真实体验。
12. 不是完胜,也有负面反馈:有些图会“太满、太油、太吵”
这一轮公开测试里,也不是所有评价都在吹。
有用户明确吐槽,gpt-image-2 生成的图有时候会显得“太密、太油、太花”,漫画线条过多,照片质感也会有点“脏”和“挤”。这点反而很重要,因为它让我们看清楚:它现在的问题不是“不会生成”,而是「生成得太多、太满、太想证明自己能画」。
这类缺点说明它已经过了“能不能做出来”的阶段,进入“怎么把输出变得更克制、更高级”的阶段了。
 案例 12:也不是没有问题,部分输出会显得过满、过油、信息噪音偏高,这反而说明讨论已经进入质量微调阶段。
案例 12:也不是没有问题,部分输出会显得过满、过油、信息噪音偏高,这反而说明讨论已经进入质量微调阶段。
把这些案例放一起看,才能理解 gpt-image-2 真正的能力边界
如果只挑一张最炸裂的图出来吹,谁都可以写出一篇“新模型封神”的文章。但把 10 多个案例放在一起看,真正有价值的信息会更清楚:
它已经明显成立的能力
中文与多语言文字渲染 角色卡与信息组织图 摄影级拟真人像 游戏 / 海报 / 信息卡等不同任务类型切换 一定程度上的多图风格一致性
它已经开始威胁真实工作流的能力
营销海报 社媒图卡 电商图变体 角色设定案 UI / 截图 / 资料页 mockup 编辑型二次创作
它目前仍然存在的问题
有时信息密度过高 部分风格会显得太满、太脏 某些二次元 / 漫画任务可能线条失控 个别场景仍会有过拟合式“炫技感”
写在最后
所以,为什么这次一定要补网友测试图?
因为像 gpt-image-2 这种模型,真正的答案从来不在发布词里,而在用户拿它做了什么。
而这轮公开案例最说明问题的一点是:「它已经不再局限于“生成一张好看的图”,而是在多个高价值任务上同时逼近可交付状态。」
你可以把它理解成图像模型从“会画”走向“会工作”的又一次加速。
这也是我现在对 gpt-image-2 的判断:
它未必已经无敌,但它已经足够强到让很多人第一次认真意识到,AI 图片模型真正要吃掉的,不是灵感,而是流程。
「更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。」
本文案例来源说明
以下案例均整理自围绕 “gpt-image-2 / GPT Image 2 / GPT IMAGE 2” 的公开测试帖与对比帖,涵盖中、英、日语用户样例,包括但不限于:
