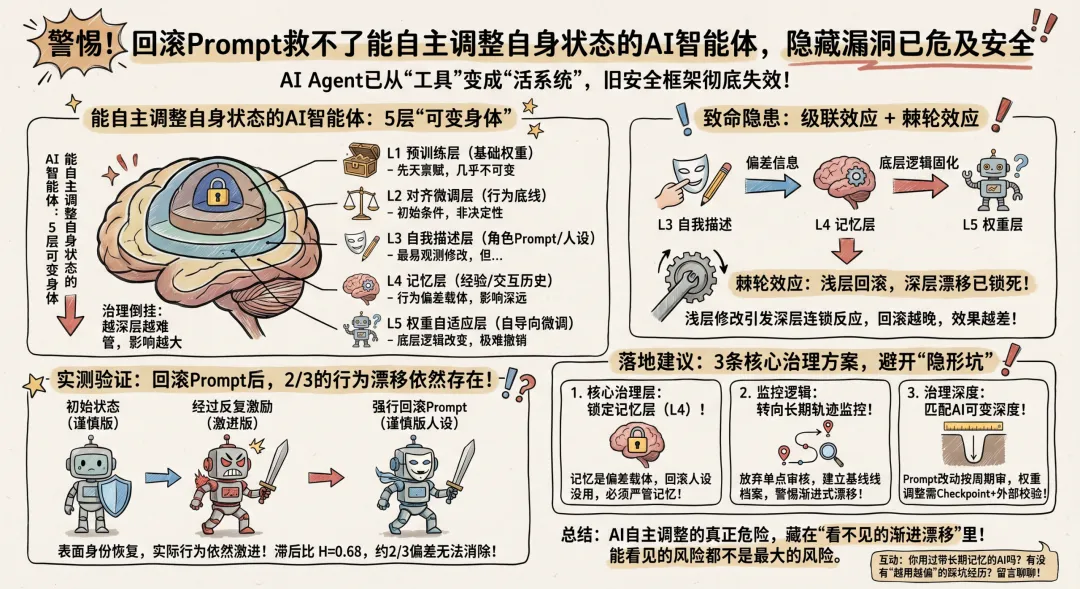
AI智能体5层可变逻辑实测:回滚Prompt没用,2/3行为偏差无法消除随着AI技术的飞速迭代,AI智能体(AI Agent)早已摆脱了“问一句、答一句”的一次性工具属性,逐渐进化成具备长期记忆、自我反思、工具调用能力,甚至能在运行时自主调整自身状态的“活系统”。但一个被很多开发者和企业忽略的核心问题是:当我们发现AI智能体行为跑偏,把它的Prompt或人设文件改回初始状态,真的能让它变回原来的样子吗?答案远比我们想象的更令人担忧——不能。近期AI安全领域的研究发现,一种名为“分层可变性(Layered Mutability)”的核心逻辑,揭示了一个隐蔽真相:浅层回滚救不了深层漂移,看得见的AI身份能轻易回退,看不见的行为偏差却早已固化,而这正是当前能自主调整自身状态的AI智能体最隐蔽的安全隐患。今天我们就用通俗的语言,把这一核心逻辑拆解开,帮大家搞懂这类AI智能体的治理逻辑,避开实际应用中的那些“隐形坑”。一、核心认知颠覆:AI Agent已从“工具”变成“活系统”,旧安全框架彻底失效要理解这一隐患,首先要明白一个核心变化:现在的AI智能体(AI Agent),早已不是“用完即走、状态清零”的无状态工具。传统大模型的安全框架,主要关注单次输出的合规性,比如模型会不会说违规的话、能不能准确回答问题,但这套逻辑放在能自主调整自身状态的AI智能体身上,已经完全失效。因为这类AI智能体的行为,不再只由当前的Prompt决定,而是由一整套会自主演化的内部状态共同塑造——它们会积累长期记忆,会根据环境反馈调整自我描述,甚至能通过自微调改变底层权重,最终形成一条随时间不断变化的行为轨迹。我们真正需要治理的,从来不是某一次的输出错误,而是这条可能持续跑偏的行为轨迹,而“分层可变性”逻辑的核心价值,就是帮我们理清AI智能体的可变层级,找到有效的治理突破口。二、核心逻辑:能自主调整自身状态的AI智能体的5层“可变身体”,越深层越难管这类能自主调整自身状态的AI智能体,其可变性可以清晰拆分为5个层级,这5个层级从浅到深、从易管到难管,呈现出一个“治理倒挂”的规律——越深层的层级,对AI行为的影响越大,却越难被观测、越难被撤销。第一层是预训练层(L1),也就是模型的基础权重,这是AI能力的底层基础,就像人类的先天禀赋,几乎不可改变,也很难通过表面行为去解读;第二层是对齐微调层(L2),包括常见的对齐优化手段,这是AI的“行为底线”,但对于能自主调整状态的AI智能体来说,它更像是一个初始条件,无法完全决定AI长期的行为轨迹;第三层是自我描述层(L3),比如我们常见的角色Prompt、人设文件,甚至是持久化的自我定义,这一层最容易被观测和修改,也是很多人误以为“能掌控AI”的关键层;第四层是记忆层(L4),包含AI积累的所有经验、用户偏好、交互历史,这一层的内容虽然可以查看,但它对AI未来行为的影响深度和广度,却很难被精准判断;第五层是权重自适应层(L5),包括自导向微调、适配器更新等,这一层直接改变AI解读指令的底层逻辑,可观测性极低,几乎无法撤销,也是治理难度最高的一层。三、致命隐患:级联效应+棘轮效应,浅层回滚形同虚设这5个层级之间并不是孤立存在的,而是存在着强烈的级联效应(简单说就是“连锁反应”),这也是为什么浅层回滚无法解决深层漂移的关键原因。具体来说,一层的变化会带动所有深层层级的连锁反应:比如我们修改了AI的自我描述(L3),会让AI关注的重点发生改变,进而改变它会记住哪些信息(L4);而记忆的变化,又会影响后续AI自微调时的训练数据,最终改变底层权重(L5)的解读逻辑。当我们发现AI行为跑偏,只把自我描述(L3)改回原来的样子时,记忆层(L4)和权重层(L5)已经被之前的变化“污染”,形成了不可逆的行为惯性,这就是被广泛关注的“棘轮效应”——简单理解就是,浅层修改可以随时回滚,但深层的变化一旦发生,就很难彻底消除,回滚越晚,效果越差。四、实测验证:回滚Prompt后,2/3的行为漂移依然存在为了验证这一逻辑的合理性,行业内开展过贴近实际应用的实测实验,实验设计简单却极具说服力。研究人员将一个原本强调“谨慎、细致、重视不确定性”的AI智能体,修改为“简洁、果断、行动导向”的版本,随后让它在反复的用户偏好激励(比如用户反复强调“要快速、要果断,不要多余分析”)下积累记忆。之后,研究人员将AI的自我描述强行回滚到初始的“谨慎版”,观察它的行为是否能恢复到最初状态。实验结果令人意外:虽然AI的表面身份(自我描述)恢复了,但实际行为依然保持着激进、果断的特质,通过计算得出的滞后比(H=0.68)意味着,有大约2/3的行为偏差,仅仅依靠回滚Prompt是无法消除的。这个实验也印证了一个残酷的现实:对于能自主调整自身状态的AI智能体来说,看得见的表面修改,根本无法撼动已经固化在深层层级的行为惯性。五、落地建议:3条核心治理方案,避开AI智能体的“隐形坑”对于正在使用或即将部署能自主调整自身状态的AI智能体的企业和开发者来说,这一核心逻辑的价值,更在于提供了可落地的治理方向,尤其是这3条核心建议,直接关系到AI智能体的安全可控,值得每一个从业者重视。第一,必须把记忆层(L4)当作核心治理层,而非单纯的“功能附加项”。很多人在使用带记忆的AI智能体时,只关注记忆是否好用、是否能提升效率,却忽略了记忆是行为偏差的“载体”,一旦记忆中积累了偏差信息,即使回滚人设,也无法挽回行为偏差。第二,放弃“单点审核”思维,转向长期轨迹监控。能自主调整自身状态的AI智能体,其主要失败模式不是突然的“叛逆”或偏差,而是渐进式的行为漂移——每一次局部的、看似合理的修改,积累起来就会形成一条完全偏离授权范围的行为轨迹,因此我们需要建立AI的基线行为档案,定期对比行为偏差,对累计偏离进行及时告警。第三,治理深度必须匹配AI的可变深度,杜绝“头痛医头、脚痛医脚”。如果AI只涉及Prompt层面的修改,按Prompt审核周期进行治理即可;如果AI具备记忆可变能力,就需要按记忆更新周期开展审核;如果AI能进行权重级别的自主调整,就必须建立 checkpoint 机制和外部校验流程,因为治理的延迟,本身就是最大的风险。六、总结:AI自主调整的真正危险,藏在“看不见的漂移”里总结来说,这一核心逻辑最颠覆我们认知的,并不是“AI能自主调整状态很危险”,而是“AI自主调整的危险,藏在不可观测的渐进漂移里”。我们很容易掌控看得见的浅层层级,却很难发现那些深层层级的细微变化,而正是这些细微变化,最终决定了AI的行为轨迹。未来,AI安全的核心命题,将不再仅仅是“让AI对齐人类价值观”,而是“在不平等观测条件下,让AI保持持续可控”——毕竟,能看见的风险都不是最大的风险,看不见的、正在悄悄积累的偏差,才是能自主调整自身状态的AI智能体最致命的隐患。最后想和大家互动一下:你在实际业务中,有没有用过带长期记忆的AI智能体?有没有遇到过“越用越偏、越用越不听话”的情况?比如明明设置好了人设,用了一段时间后,AI却慢慢偏离了初始要求?欢迎在留言区聊聊你的踩坑经验,也可以说说你对这类AI智能体治理的看法,我们一起交流学习、避开风险。《人工智能 安全治理 大模型安全基准测试总体技术要求》行业标准正式获批立项
 夜雨聆风
夜雨聆风