 夜雨聆风
夜雨聆风





openclaw爆火,自己也算阴差阳错赶了趟时髦。
openclaw并不算划时代的产品,仅仅是一个框架,得益于大模型能力的提升,它能够做更多的事情。
作为一个agent,它可以操作电脑,这使它不再是传统的对话机器人,而是能够帮助人做一些工作,让人有更多的时间来做其他有价值的事。
从我的角度来讲,无论是定时提醒,还是自动化的简单任务,或者能够随时记录我自己的想法,虽然有一定作用,但并不值得我为它支付订阅费用。
思来想去,还是本地知识库的搭建更有意义。通过将我需要用到的法律文件、保险条款以及自己过往总结的相关知识放到知识库,再结合openclaw的记忆能力,无论是内容输出,还是客户服务,都能为我提供不小的价值。
整个过程其实不难,网上都有开源的方案,我们要做的只是部署。
本质上是利用embedding模型将我们的资料向量化,变成易于大模型理解的方式存储到向量库。之后如果有使用知识库的需求,只需要让大语言模型去做检索就可以了。
用openclaw的意义在于它本身有自己的身份定义,也有在我们的使用过程中积累的记忆,这样它在检索加工之后生成的内容会更符合我们的需求。
事实上,如果openclaw安装飞书官方插件的话,本身就可以把飞书云文档作为知识库。我们选择本地部署的优势有两点,一是数据全在本地,符合隐私要求;二是飞书云文档只支持关键字检索,而我们搭建的知识库包括关键字、语义以及混合检索三种模式。
关键字检索的局限性比较大,比如关键字是“重大疾病”,那么检索“重疾”就没有用。而语义检索可以兼容错别字、同义词、中英文,所以对于知识库来说,语义检索是刚需。
下面我把自己搭的思路完整说一下。



一开始考虑的方案是ragflow,毕竟去年deepseek火的时候曾经折腾过一段时间本地知识库,用的就是ragflow方案,相对熟悉一点。
但是ragflow的缺点是资源占用比较多,我16G内存的机子上,embedding本地模型总是被系统后台错杀,所以选择更为轻量的qdrant向量库,embedding模型选择对中文更友好的bge-m3,本地部署。
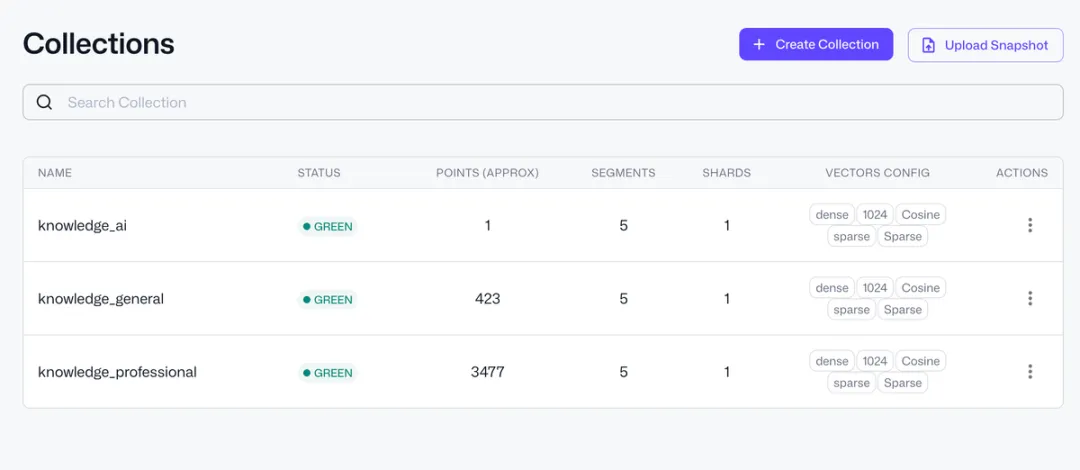



做好这些之后就是写一个文件监控脚本,我们在本地放一个名为知识库的文件夹,实现文件进入知识库时自动进入向量库,当文件移出、删除时,自动删除向量库中的相关内容,以实现知识库的无感更新。



有了向量库之后,最重要的是利用openclaw对话,实现对知识库的检索,让openclaw基于知识库的内容作出回答。
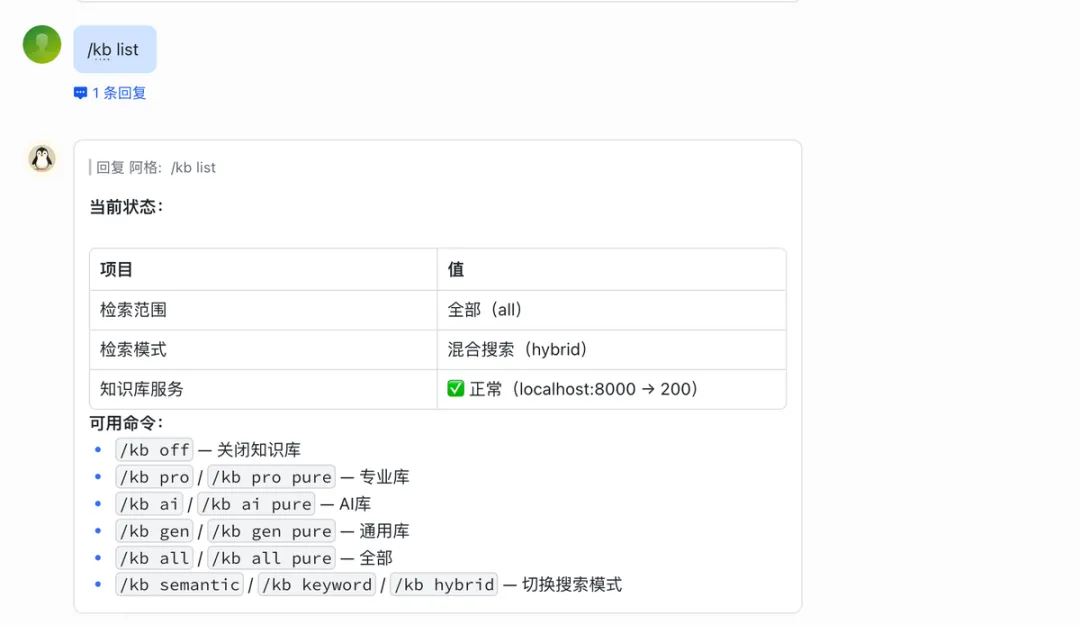
为此我做了一个skill,通过命令的方式让openclaw实现检索的开关、检索模式的切换、回答模式的切换。
/kb semantic/kb keyword/kb hybrid— 切换关键字检索、语义检索、混合检索 /kb pro/kb gen等 — 切换不同知识库 /kb pure— 纯知识库检索,只基于知识库内容作答 /kb off/kb on— 知识库开关 /kb list— 查看当前状态及所有命令
最后设置开机启动,并设置重启机制,当知识库服务挂掉时能够自动拉起。
至此,我们的知识库搭建以及openclaw的对接就完成了,以后不需要再进行过多的配置,可以无感使用。
示例:
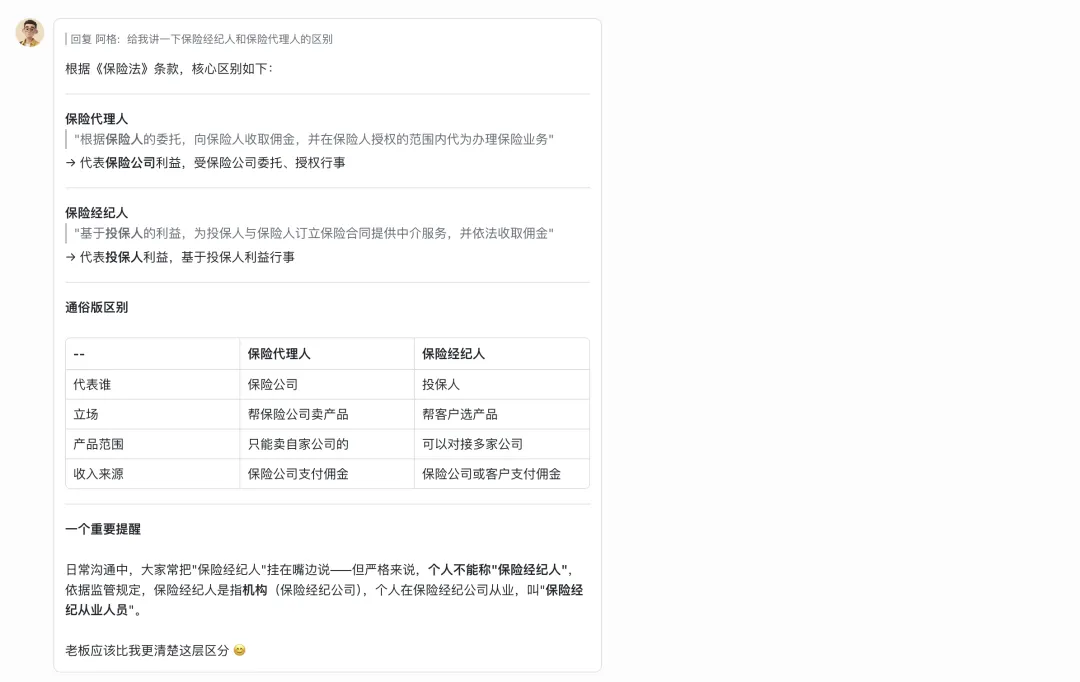
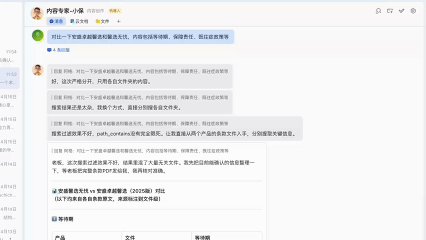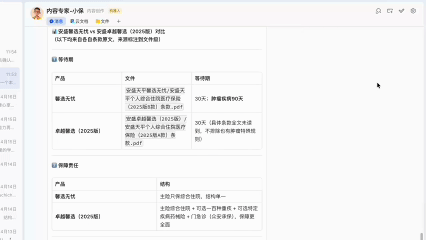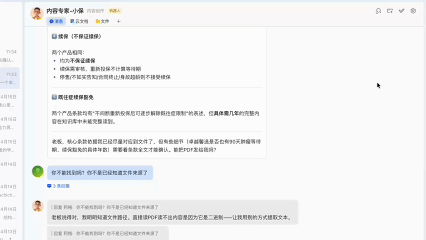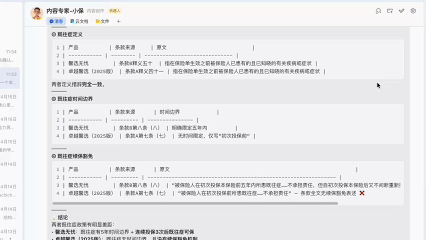
还是很有用的,比如这里关于安盛馨选无忧的等待期,肿瘤类、心脑血管类等疾病是90天,这点我以前并没有注意到。
当然,由于文件入库是对文件进行切片,很可能会丢失上下文,所以对于保险产品对比这种比较严谨的事情来说,还是要设置更多的规则和流程,最好能做成skill,否则很容易出现幻觉,把A产品的条款混到B产品中。



整个过程听起来有点复杂,事实上大部分工作openclaw都可以帮你完成,我们要做的其实只是告诉openclaw自己的需求,并设定相应的规则。
从我的使用体验来延伸,对于保险、律师、财务这类需要参考大量数据的工作来说,openclaw这类产品很可能会成为刚需,能够大幅提升工作效率。
回到开头说的,openclaw本身并不稀奇,但好就好在它开源,重度使用的成本很低,而且可以基于自身的需求高度个性化。我越来越觉得,这样的工具不是锦上添花,谁先用起来,用得好,很可能甩开同行一个身位。


