调了3小时 OpenClaw 记忆系统,最后发现元凶是一个「从来没注意过的玩意儿」——node-llama-cpplocal embeddings unavailableCannot find package `node-llama-cpp`
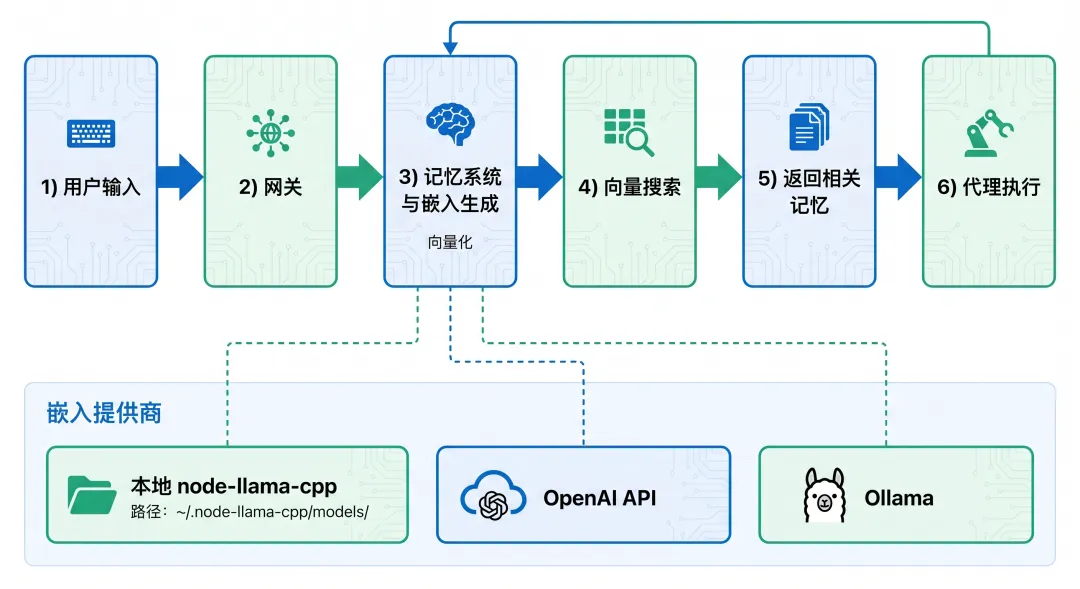
然后去搜 "node-llama-cpp",看到 llama.cpp,下意识以为这玩意儿是跑大模型的。node-llama-cpp 和 Ollama 完全不是一回事。在讲 node-llama-cpp 之前,必须先搞清楚 OpenClaw 的记忆系统是怎么工作的。OpenClaw 的记忆系统采用 向量检索 机制:用户输入 → 转为向量 → 在记忆库中搜索相似内容 → 返回相关记忆 → 注入上下文
这个过程依赖 embedding 模型 ,将文本转换成高维向量。OpenClaw 支持的 embedding 来源| 提供者 | 模型 | 特点 |
|---|
| 本地 (node-llama-cpp) | GGUF 量化模型 | 完全离线,数据不外传 |
| OpenAI | text-embedding-3-small | 需要 API Key |
| Gemini | text-embedding-004 | 需要 API Key |
| Voyage | voyage-3 | 需要 API Key |
| Ollama | 本地 embedding API | 需要 Ollama 服务 |
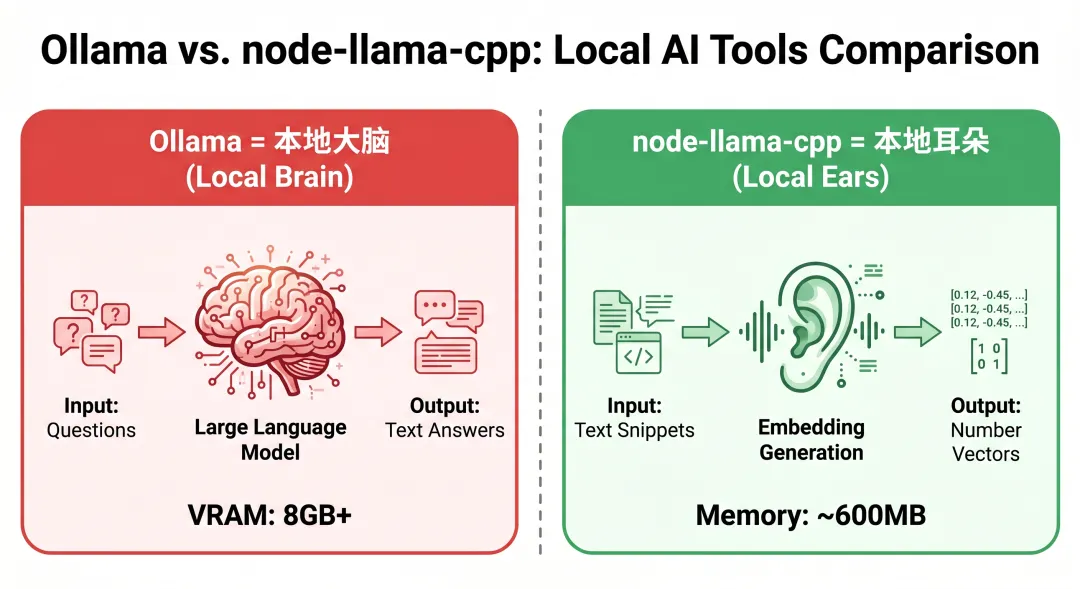
默认优先级 :本地 > Ollama > 云端 APInode-llama-cpp 是 llama.cpp 的 Node.js 绑定 ,用于在 Node.js 环境中运行 GGUF 格式的量化模型。图1:OpenClaw 架构图 - Memory System 通过 node-llama-cpp 生成 embedding,支持本地、OpenAI、Ollama 等多种提供者| 维度 | node-llama-cpp | Ollama |
|---|
| 用途 | embedding 向量生成 | LLM 推理引擎 |
| 模型格式 | GGUF | GGUF / PyTorch |
| 运行什么 | 小型 embedding 模型 | 大型语言模型 |
| 资源消耗 | ~600MB 模型 | 数 GB 到数十 GB |
| 是否必须 | 开启本地 embedding 时必须 | 可选,仅当本地 LLM 时需要 |
node-llama-cpp = 本地耳朵(听清你说的话)图2:Ollama 与 node-llama-cpp 对比 - Ollama 负责 LLM 推理(8GB+ 显存),node-llama-cpp 负责 embedding 向量生成(~600MB)- C++ 编译依赖复杂:node-llama-cpp 需要编译 native 扩展,涉及 llama.cpp 的 C++ 代码
- Windows: 需要 Visual Studio Build Tools
# 安装 Visual Studio Build ToolswingetinstallMicrosoft.VisualStudio.2022.BuildTools# 或者使用 Node.js 的 node-gyp 配置npmconfigsetmsvs_version2022
- macOS: 需要 Xcode Command Line Tools
sudo apt install build-essential
- 下载模型可能失败:模型文件从 HuggingFace 下载,国内网络经常超时
- 用 Ollama embedding 的用户不需要
"让简单的事情保持简单,复杂的事情在需要时才出现"cd ~/.openclaw# 交互式选择要构建的模块pnpm approve-builds
pnpm rebuild node-llama-cpp
~/.node-llama-cpp/models/~/.node-llama-cpp/models/- 从 HuggingFace 下载 GGUF 模型(约 600MB)
- 缓存到 ~/.node-llama-cpp/models/
# 设置 HuggingFace 镜像(国内加速)exportHF_ENDPOINT=https://hf-mirror.comcd ~/.openclaw# 直接触发构建pnpm rebuild node-llama-cpp --ignore-scriptspnpm install --ignore-scripts
cd ~/.openclaw/node_modules/node-llama-cpp# 生成构建文件pnpm build-debug# 或者生产构建pnpm build-release
问题 1:pnpm approve-builds 找不到# 正确做法cd ~/.openclaw# 确认目录结构ls-la node_modules/node-llama-cpp
问题 2:编译时报错 "C++ compiler not found"# 设置国内镜像export HF_ENDPOINT=https://hf-mirror.comexport HF_HUB_ENABLE_HF_TRANSFER=1# 手动下载(备选)# 模型默认路径:~/.node-llama-cpp/models/
问题 4:编译成功但仍报 "Cannot find package"# 清理缓存重新安装cd ~/.openclawrm -rf node_modules/.cachepnpm install# 验证安装node -e "require('node-llama-cpp')"~/.openclaw/config/openclaw.json
{ "memorySearch": { "provider": "local", // local | openai | gemini | voyage | ollama "local": { "model": "default" // 可选:指定模型 } }}# 查看当前配置openclaw config get memorySearch.provider# 设置为云端(跳过 node-llama-cpp)openclaw config set memorySearch.provider "openai"
# 运行诊断openclaw doctor# 或者直接问它关于记忆的问题openclaw chat "你记得上周我问你什么吗?"
node-llama-cpp 支持加载自定义 GGUF 模型:{ "memorySearch": { "provider": "local", "local": { "model": "/path/to/your/model.gguf" } }}常用 embedding 模型(GGUF 格式):下载后放入 ~/.node-llama-cpp/models/ 目录即可。| 问题 | 答案 |
|---|
| node-llama-cpp 是什么? | llama.cpp 的 Node.js 绑定,用于本地 embedding |
| 和 Ollama 的区别? | Ollama 跑 LLM,node-llama-cpp 跑 embedding |
| 为什么默认不装? | C++ 编译复杂,不是所有人都需要 |
| 如何安装? | pnpm approve-builds → 选择 node-llama-cpp |
| 模型在哪? | ~/.node-llama-cpp/models/(约 600MB) |
 夜雨聆风
夜雨聆风