 夜雨聆风
夜雨聆风我先说一个真实的数字对比。
多年前,我做一个临床数据的逻辑回归分析,从拿到数据到出可以给导师看的结果,花了整整一个下午,四个多小时。
上个月,一个完全陌生的数据集,同样类型的逻辑回归,加上结果整理成论文表格,一个小时二十分钟,包括中途去接了一杯水。
做的事是一样的。变了的,是每一步遇到问题时的处理方式。
这篇文章不是教你AI怎么用,是写我自己工作状态真实变化的三件事。你可以对照着看,判断自己现在是哪种状态。
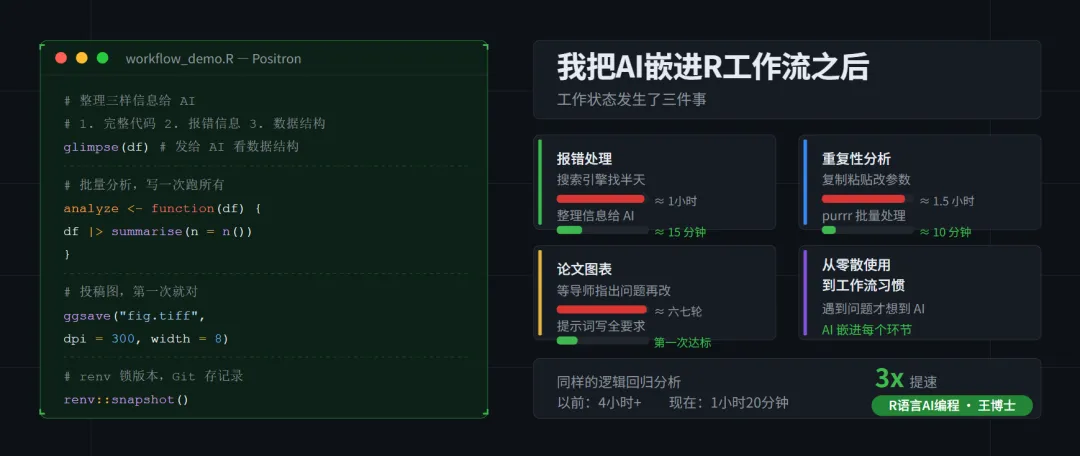
01 第一件事:报错从"焦虑时刻"变成了"顺手的事"
以前遇到报错是什么感觉,很多人应该懂。
打开搜索引擎,把报错信息复制进去,搜到一堆Stack Overflow的帖子,翻了几条,发现情况不太一样,改了试试,还是不对,再搜,再改,来回折腾半个小时,最后可能靠一个完全不相关的答案歪打正着解决了,也不知道为什么能解决。
更惨的是那种搜不到任何有用东西的报错。就只能盯着屏幕,或者去翻文档,或者问能问的人,有时候一个报错真的能卡一整天。
现在的处理方式完全不一样了。
遇到报错,我做的第一件事是把三样东西整理好:完整的代码(不只是报错那一行)、完整的报错信息(从Error到最后一行),加上数据结构(直接跑一下glimpse(df),把输出复制过来)。
然后把这三样东西发给AI。
不是"帮我看看这个报错",是把完整的上下文都给它。
结果的差别很明显。给完整信息的时候,AI的回答是针对我的具体情况的——"你这里的问题是xx列被读进来的是factor类型,不是numeric,需要在这一步加一个类型转换"。给模糊描述的时候,AI的回答是通用的,要自己再判断对不对,来回多跑几轮。
这个变化带来的不只是时间上的节省。
以前报错是会打断工作节奏的,焦虑一下,思路散了,回来还要找状态。现在遇到报错的感受变了——它就是一个需要处理的问题,整理好信息发出去,等一下,改一行,继续写。整个过程的情绪是平的。
对我来说,这个情绪变化比时间节省更值得说。
02 第二件事:重复性工作从"复制粘贴改参数"变成了"写一次跑所有"
这件事是某天我突然意识到的。
我当时在做一个医院数据分析,需要对十几个科室分别跑同样的描述统计,每次就是复制代码,把科室名改掉,运行,再复制,再改,再运行。我已经这么做了半年多了,觉得这是正常流程。
然后有一天,我让AI帮我把这个流程重构一下,它给了我一个用purrr::map()批量处理的方案——把分析步骤封装成一个函数,然后一行代码跑完所有科室。
# 把分析步骤封装成函数analyze_dept <- function(df) { df |> summarise( n = n(), age_mean = mean(age, na.rm = TRUE), age_sd = sd(age, na.rm = TRUE), male_pct = mean(gender == "男", na.rm = TRUE) )}# 一行跑完所有科室results <- patient_data |> group_by(department) |> group_split() |> map(analyze_dept) |> list_rbind()原来一个多小时的工作,现在不到十分钟。
但这件事让我更在意的不是时间,而是我意识到自己在重复做一件本来不需要重复的事,这件事持续了半年多,我一直没有想着去改变它。
用AI之前,遇到重复性工作,我的反应是接受——这就是要做的,一步一步来。用AI之后,我开始有一个新的反应:这件事能不能只写一次,让代码来重复?
这个思维方式的变化,比具体的代码更有价值。
03 第三件事:论文图表从"靠运气达标"变成了"第一次就对"
做科研的人对这个场景应该不陌生。
ggplot2跑出来了一张图,自己觉得还行,发给导师或者投稿,结果被指出一堆问题:字体不符合期刊要求、分辨率不够、图例位置不对、坐标轴缺单位……每次被指出一个问题,改一个,再被指出另一个,前后改了好几轮才达标。
我以前也是这样过来的。期刊对图表的要求是有规律的,但这套规律没有集中写在哪里,是在一次次投稿返修里零散积累的。
用AI之后,这个流程变了。
我现在写提示词的时候,从一开始就把投稿要求放进去:
用ggplot2绘制KM曲线,要求:- 字体:Arial 11pt- 主题:黑白主题,无网格背景- 图例:移到图内右上角- 导出:TIFF格式,300DPI,宽8英寸- 坐标轴:x轴"随访时间(月)",y轴"生存率"出来的代码已经包含了所有这些要求,不需要试探,不需要被动等导师指出问题,第一次就能达到投稿标准。
有时候我会让AI直接解释它给的代码里某个参数的含义。比如我不理解为什么要用theme_classic()而不是theme_bw(),一问,AI会解释两者的具体区别,以及在什么场景下用哪个更合适。
这种"顺手学到了一个知识点"的感受,是以前靠自己搜索很难复现的。
04 说到底,变的是什么
写到这里,我想说一个更本质的东西。
上面三件事,看起来是三个独立的变化,但背后是同一件事:我和AI之间的协作方式变了,不再是"遇到问题才想到AI",而是AI嵌进了每一个工作环节。
遇到报错,我知道该整理哪三样信息。做重复性工作,我知道该怎么描述需求让AI帮我重构。出论文图,我知道从一开始就把所有要求说清楚。
这套方式形成之前,我用AI是零散的——有时候想到,有时候忘了,用了之后觉得效果一般,因为我不知道该怎么描述需求。
这套方式形成之后,它变成了一个工作习惯,不需要每次想"这件事能不能用AI",它就是工作流的一部分。
05 现在是最好的时机
最后说一件事。
我见过两类人用AI学R:
一类是先把R学好,再去学AI用法。这类人学R的时候走了很多弯路,习惯固化了之后再加入AI,需要改的不只是工具,是整个工作方式。
另一类是从一开始就把AI带进来,边学边用,每一步遇到不会的地方就问AI,逐行理解代码,逐渐养成这套工作习惯。
第二类人走的路,比第一类省力很多。
如果你现在正在学R,或者用R但还没有形成AI协作的习惯,现在是最好的时机——不是因为AI有多厉害,是因为现在开始的成本最低。
这套AI嵌进工作流的方法,我整理了一套完整的提示词框架,覆盖数据清洗、统计建模、可视化、报错调试十个高频场景,每个场景一个可以直接复制的模板。
加我微信发“R模板”,直接发给你,免费的。
扫码添加👇

如果你身边有同样在用R做科研、但还没开始用AI的朋友,欢迎把这篇转发给他。有时候看到一个真实的变化,比看十篇教程更容易开始行动。
你现在用R做分析,哪个环节最耗时间——报错调试、出图格式,还是结果整理?评论区说说,我来聊聊怎么优化。
