 夜雨聆风
夜雨聆风什么是markitdown
一个将文件(pdf/word/xls等)转换为 Markdown 的 Python 工具,官方反馈还支持Youtube URL地址、图片、音频等。 因为Markdown格式是现在AI的通用语言格式。
Github 地址 https://github.com/microsoft/markitdown
如何安装
因为要测评这个工具,所以我们先初始化一个干净的Python环境
1、初始化环境
1 2 3 4 5 6 7 cd test-mitd# 使用uv 初始化环境(当前前提是在电脑上已经安装了 uv 管理工具 )# 要求Python 3.8+ # pip install uv uv venv --python=3.12 .venv# 激活环境source .venv/bin/activate
2、安装markitdown 及依赖
1 2 3 4 5 6 # 这里选择安装全部依赖,另外注意,如果你用的是 zsh ,请使用 uv pip install 'markitdown[all]' ,主要需要用引号括起来uv pip install markitdown[all]# 如果是安装指定的依赖uv pip install markitdown[docx]# 或者指定多个uv pip install markitdown[docx, pdf, xlsx, xls]
3、验证安装
1 2 # markitdown --versionmarkitdown 0.1.5
测评
Tip
在正式测试之前我们先准备几个样例文件
测试文件介绍
1 2 3 4 5 6 7 ├── Word转Markdown测试.docx # 简单的Word,包含标题一、标题二、正文、有序无序列表和图片├── PDF转Markdown测试.pdf # 基于上面的docx另存为的PDF文件├── ai_dify_llm.csv # 两列的QA问答样例数据├── ai_dify_llm.xls # 基于上面的csv 另存为 xlx├── ai_dify_llm.xlsx # 基于上面的csv 另存为 xlx ├── 微软MarkItDown工具介绍.pdf # 基于豆包生成的pptx 另存为的 pdf (为了测试更复杂的pdf)└── 微软MarkItDown工具介绍.pptx # 基于豆包生成的pptx
我们这里直接使用 markitdown的命令行模式来测评。
1 2 3 4 5 6 7 8 9 10 11 12 13 # 测试基本的Wordmarkitdown Word转Markdown测试.docx -o Word转Markdown测试-v1.md# 测试基本的PDFmarkitdown PDF转Markdown测试.pdf -o PDF转Markdown测试-v1.md# 测试 cvs/xls/xlsxmarkitdown ai_dify_llm.csv -o ai_dify_llm-from-csv.mdmarkitdown ai_dify_llm.xls -o ai_dify_llm-from-xls.mdmarkitdown ai_dify_llm.xlsx -o ai_dify_llm-from-xlsx.md# 测试pptxmarkitdown 微软MarkItDown工具介绍.pptx -o 微软MarkItDown工具介绍-from-pptx.md
上面的这些基本文档类型测试都没有问题,打开对应的markdown文件,发现也都是基本解析成功的,
为啥说基本解析成功,因为
• docx 中的图片 默认解析出来是 是截断的图片base64编码。 需要添加--keep-data-uris参数可以获取到完整的base64编码• /pdf中的图片直接是没有解析到
然后测试下特殊的PDF
1 2 3 4 5 # 测试负载的PDFmarkitdown 微软MarkItDown工具介绍.pdf -o 微软MarkItDown工具介绍-from-pdf.mdCould not get FontBBox from font descriptor because None cannot be parsed as 4 floatsCould not get FontBBox from font descriptor because None cannot be parsed as 4 floats... ...
发现是报错的,这里的 FontBBox的含义是
Font Bounding Box,字体边界框,格式为
[x_min, y_min, x_max, y_max]的 4 个浮点数
某些特殊 PDF(尤其是由 Google Docs、Canva 等 生成的文件)会使用 Type3 自定义字体,这类字体的 FontBBox 可能只存在于字体规格(spec)中,不在 FontDescriptor 里。
参考资料 https://github.com/pdfminer/pdfminer.six/issues/1162
提示让升级 pdfminer.six 到最新版本
1 uv pip install --force-reinstall pdfminer-six
最终升级到最新版本 pdfminer-six==20260107再次执行还是同样的问题
特殊PDF解决方案
Tip
使用第三方包 pymupdf4llm
这里给出可运行的验证程序
1 2 3 4 5 6 7 8 9 10 11 12 13 import sysfrom pymupdf4llm import to_markdownpdf_path = sys.argv[1]md_output = sys.argv[2] if len(sys.argv) > 2 else pdf_path.replace(".pdf", ".md")# 直接输出 Markdown(自动处理表格/标题/列表)markdown_text = to_markdown(pdf_path)with open(md_output, "w", encoding="utf-8") as f: f.write(markdown_text)print(f"✅ 转换完成: {md_output}")
再次测试转化
1 2 3 4 5 6 7 8 9 10 11 12 uv run python convert_with_llm.py 微软MarkItDown工具介绍.pdf 微软MarkItDown工具介绍-pdf-v2.mdwarning: No `requires-python` value found in the workspace. Defaulting to `>=3.12`.Image too small to scale!! (2x36 vs min width of 3)Line cannot be recognized!!=== Document parser messages ===Using Tesseract for OCR processing.OCR on page.number=0/1.OCR on page.number=1/2.OCR on page.number=2/3.OCR on page.number=3/4.✅ 转换完成: 微软MarkItDown工具介绍-pdf-v2.md
pptx / pdf 转化的限制
• pptx 和之前的 docx 一样,它知道有图片,但是无法获取到具体的图片,给出来给你图片的引用 但实际当前目录下根本没有Picture4.jpg这个图片
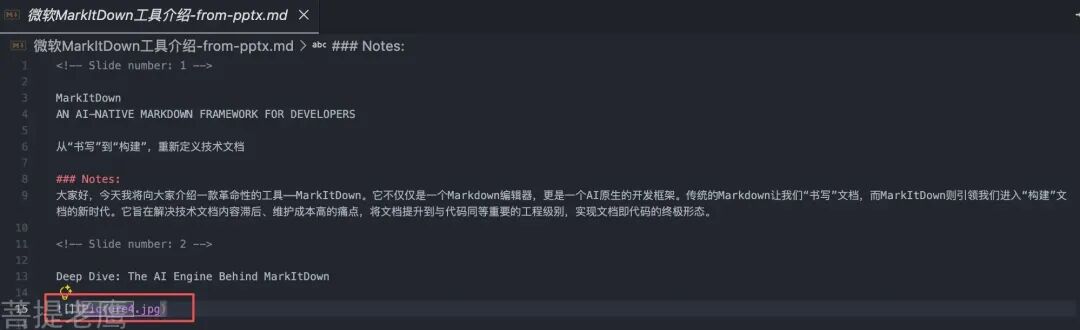
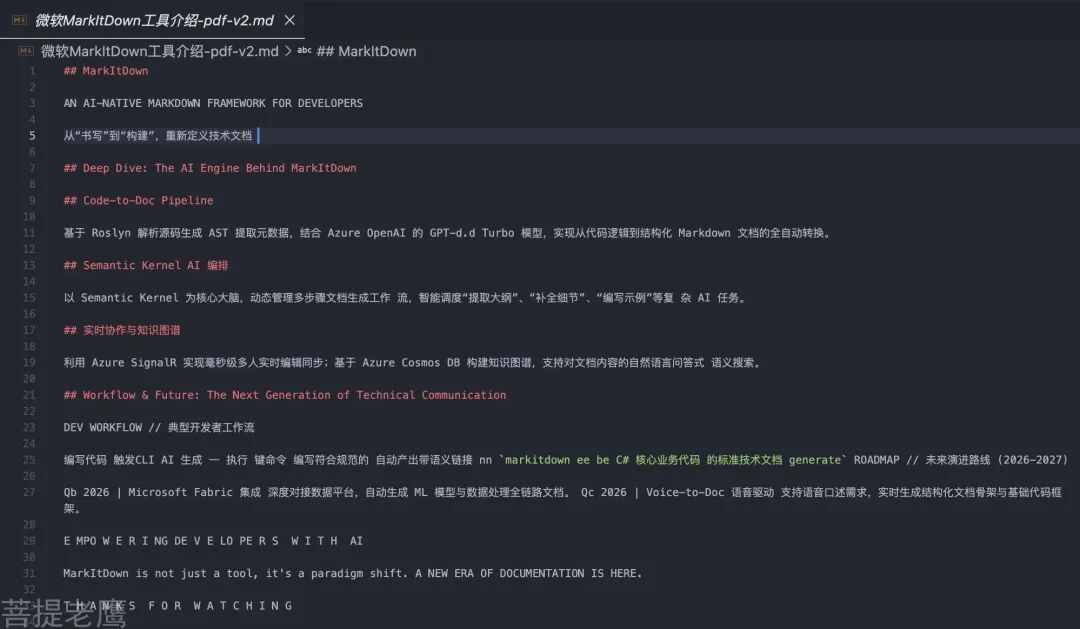
• pdf 也和前面提到的一样,感知不到图片的存在,而且这种复杂的PDF解析出来和原文想要的结果差异较大 • 另外pdf 无法获取到“格式” 比如一级标题、二级标题、无序列表等
音视频转化
其实针对音视频转化不能说是转化,应该说是转写 transcribe
这里拿mp3音频做测试,在测试之前先说明几点
1、音视频转写依赖于 openai的whisper模型2、markitdown 命令行工具无法加载本地的whisper模型, 要联网但是又受限于国外网络环境
接下来我们就测试下mp3 转写
准备工作
1 2 3 4 5 6 # 安装对应的模块pip install openai-whisper# 下载对应的量化模型,这里用base模型mkdir -p ~/.cache/whispercurl -L -o ~/.cache/whisper/base.pt https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt
脚本测试
1 2 3 4 5 6 7 8 9 10 11 # translate_mp3.pyimport whisper# 加载基础模型 (会自动加载 ~/.cache/whisper/base.pt )# 这里名字一定要是 base.ptmodel = whisper.load_model("base")# 转录音频文件result = model.transcribe("your_audio.mp3")print(result["text"])
Tip
这里有个细节需要主要下
• 如果是常规的录音问题,比如会议录音,或者自己录制的一段话之类的都是没有问题。 • 但如果是类似歌曲这种,除了语音内容之外,掺杂了很长的配乐之类的。 • 第一 transcribe 建议加上 language="zh"• 第二转写出来的结果和实际感觉还是有点差异(难道是有隐藏的语音被检测出来了?)
比如这里我用 《星月神话》这首歌的MP3 来测试的结果如下
1 {'text': ' Yea我爱你我爱你我爱你我爱你我爱你我爱你我爱你我的一生最美好的长情我的一生最美好的长情..... '
文章由个人纯原生写作,无AI痕迹
