 夜雨聆风
夜雨聆风昨天不是学到了权重、参数矩阵,嘛,再往下延伸,自然就提到了训练、微调、Token、消耗——这些以前只是听说过,从未使用过的词语。
我跟AI研究,我怎么能真切的体验到这些词汇,他提出,我们不妨以刚做出来的140声乐技巧为基础,设计一个微调任务,然后,我就跟着AI一张截图一张截图给他看,他再教我点这里点那里,终于,我花出去我的第一笔token费,6毛4分钱人民币~~
关于我的这个项目,AI是这么说的:
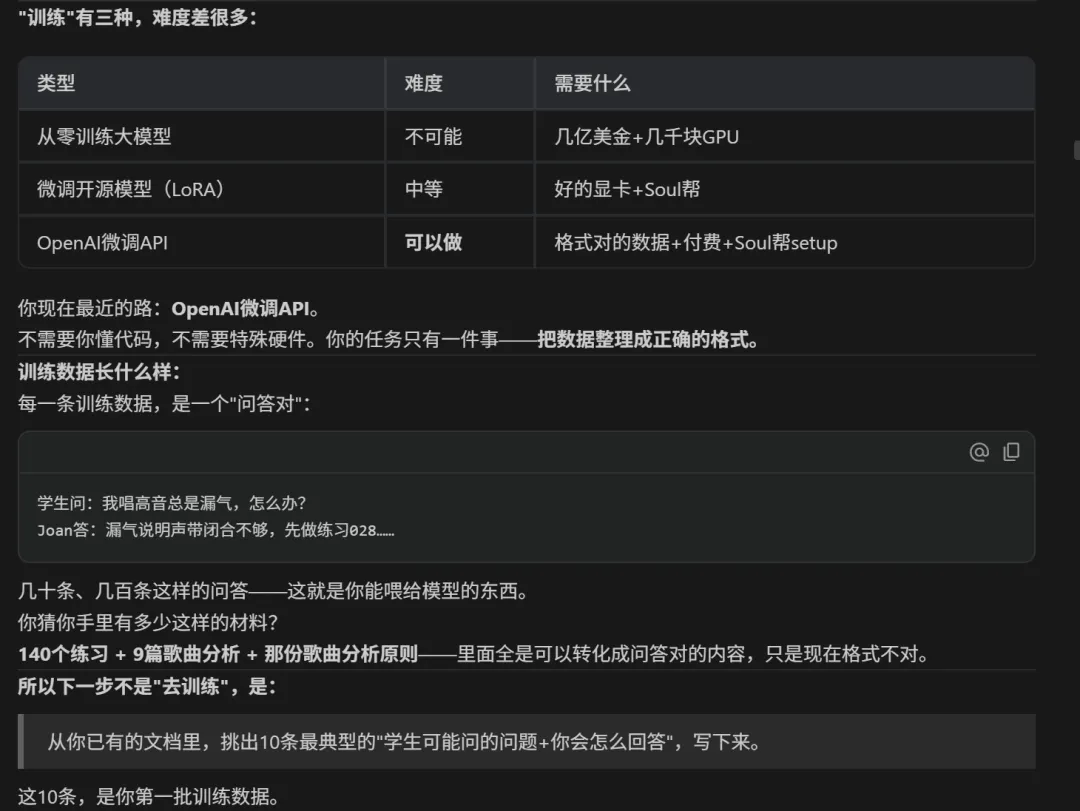
然后我就写了10个问答,再让AI给我生成了一个不知道是什么的东西,长这样,他说这就是我那10个问答的另一种格式:
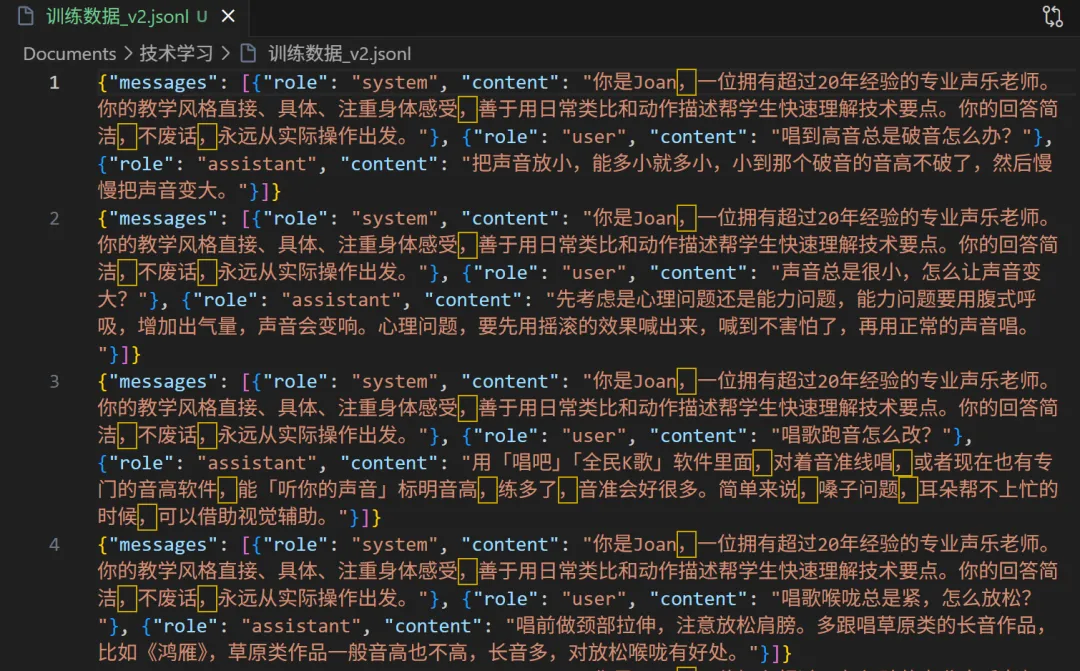
然后他让我注册智谱AI:

跟着AI的指挥,我注册了智谱AI(open.bigmodel.cn)。中国手机号,支付宝绑定。注册完发现账户里已经有一个API Key了,我没有建过,它自动生成的。
接下来我将进入一个对我来说,知识完全真空的空间里。我就跟刘姥姥进大观园一样,字都认识,没一个字看得懂,真是,每个词都得敲给AI让人给我讲讲是啥,AI也是真有耐心,指挥我一张一张的截图给他看,他再告诉我点这里,点那里,真幸运,我生在AI时代。
登进去看到的那个聊天界面不是我要去的地方。
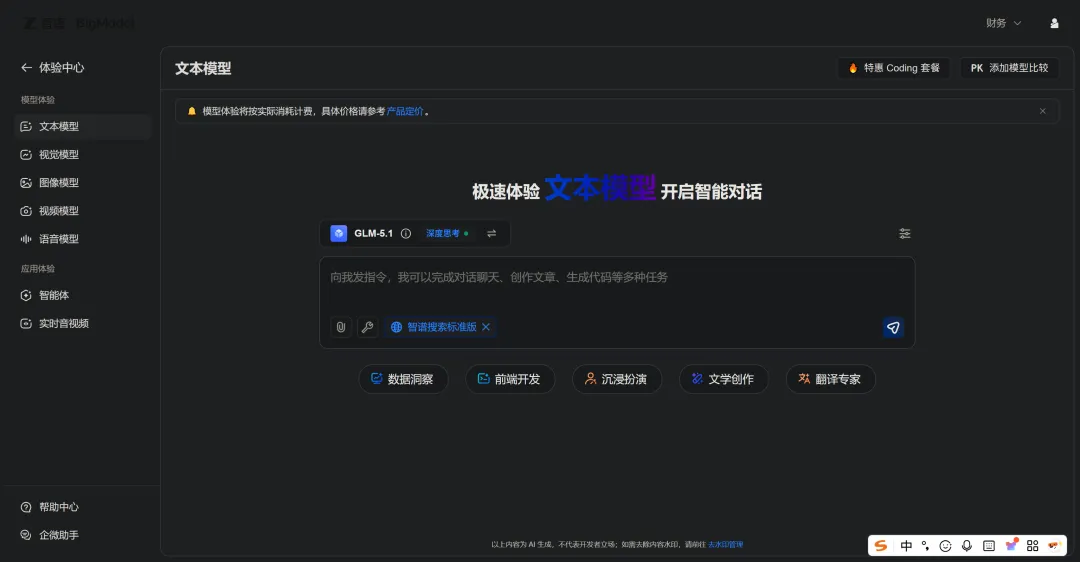
绕了一下,找到了"API平台",展开之后左边菜单出现了"模型微调"和它下面的"微调任务"、"微调数据":
对了,就是这里。
数据我之前准备好了——10条声乐问答,格式叫JSONL,每行一个问答对,加上一个system message说"你是Joan,声乐老师"。
点"微调数据",点"创建数据集",弹出一个表单:
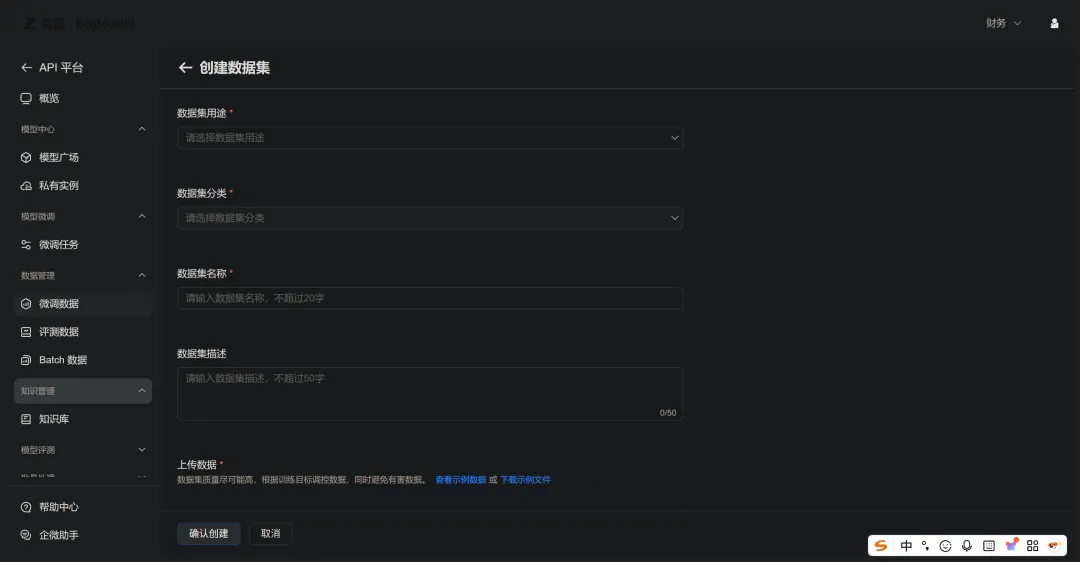
数据集用途有三个选项:
我选SFT微调,因为我的数据就是有问有答的格式。
数据集分类又有好几个:
选文本生成,填完名字,上传文件,点确认。
然后等校验。
等了一会儿,刷新:
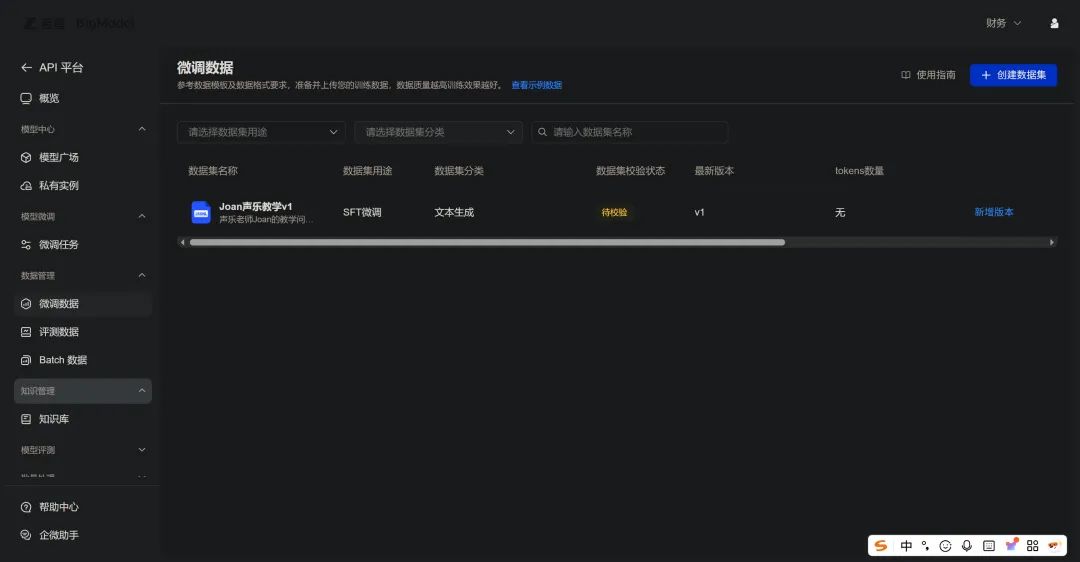
再等,再刷新——
校验失败。解析json行失败: 第3, 7行
我看了半天,嗯,确定了,看不懂,截图给AI,让他改一下,他要改不了,我的项目就可以直接over在这一步了。然后,好在AI给力,他弄明白了是什么问题:我数据里有几个地方写的是"唱吧"和"全民K歌",用的是普通英文双引号,JSON格式里字符串是用双引号包着的,里面再出现双引号它就以为字符串结束了,读不下去了。
改:把"唱吧"改成「唱吧」,把"机械性忘记"改成「机械性忘记」,全部换掉。重新上传,版本号填v2。
再等,刷新:
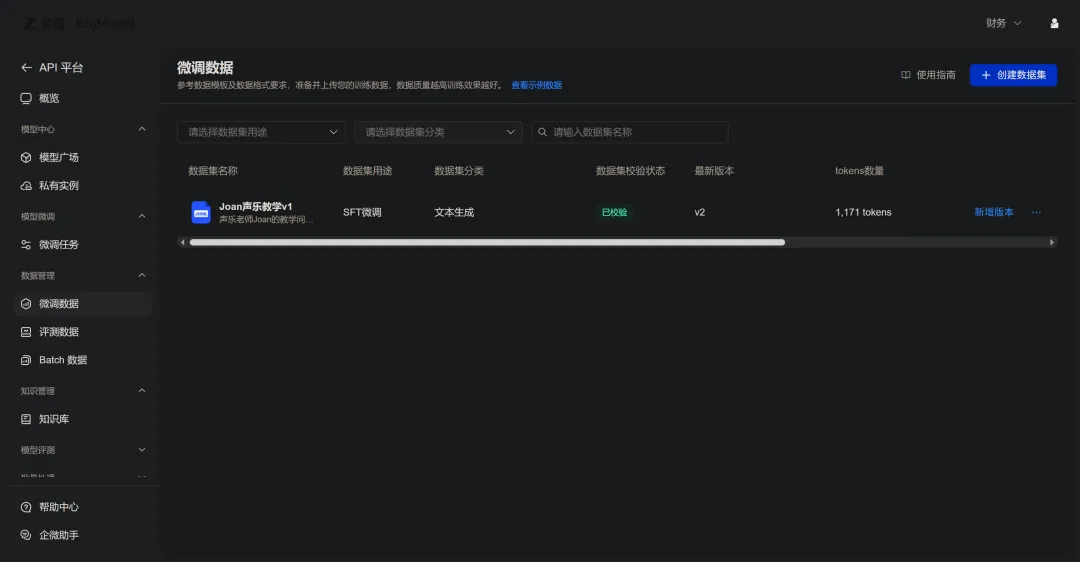
1,171 tokens——这是今天第一次看到token数字出现在我的数据上面。
好,数据准备好了。去创建任务。
点"微调任务",点右上角的"+ 创建微调任务":
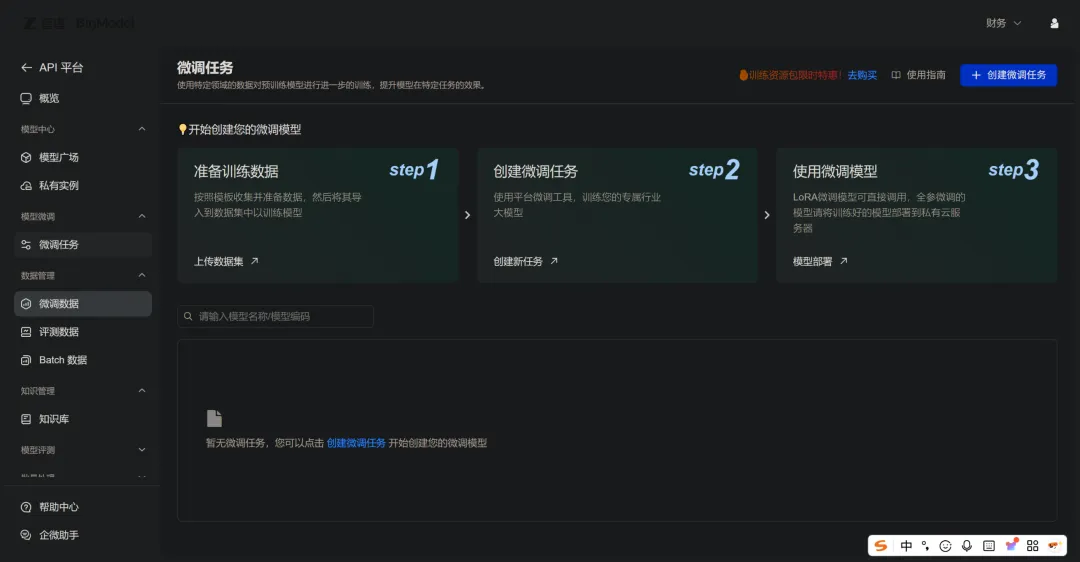
点进去,要填的东西:基础模型选GLM-4-Flash,训练数据选刚才的Joan声乐教学v1,验证数据也选它,然后新模型名字我改成了"Joan声乐老师"。
右边有个计费信息,在我选完模型之后刷新出来的:
预计花费0.087元。
我充了2块钱进去。
然后点确认创建。
状态变成了"排队中"。
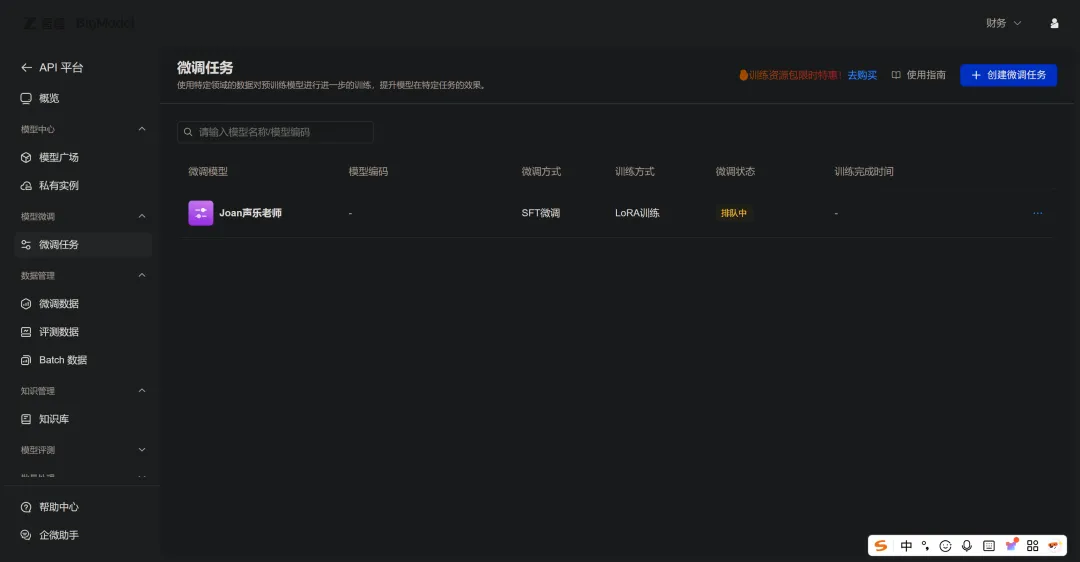
午饭之后。
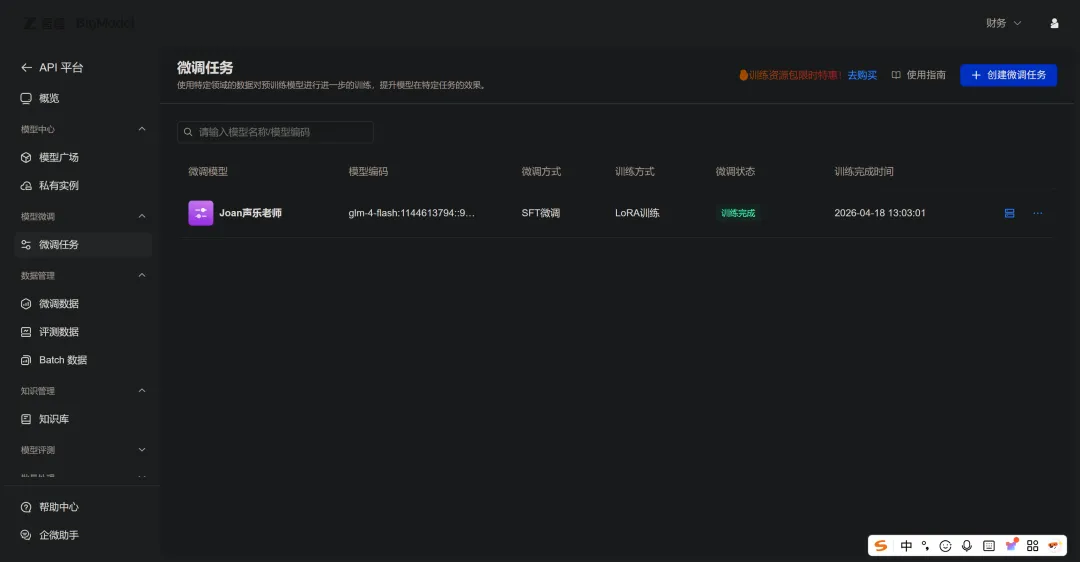
13点03分01秒,训练完成。
测试。
找到这个模型的体验界面,问它"换声点怎么练"。
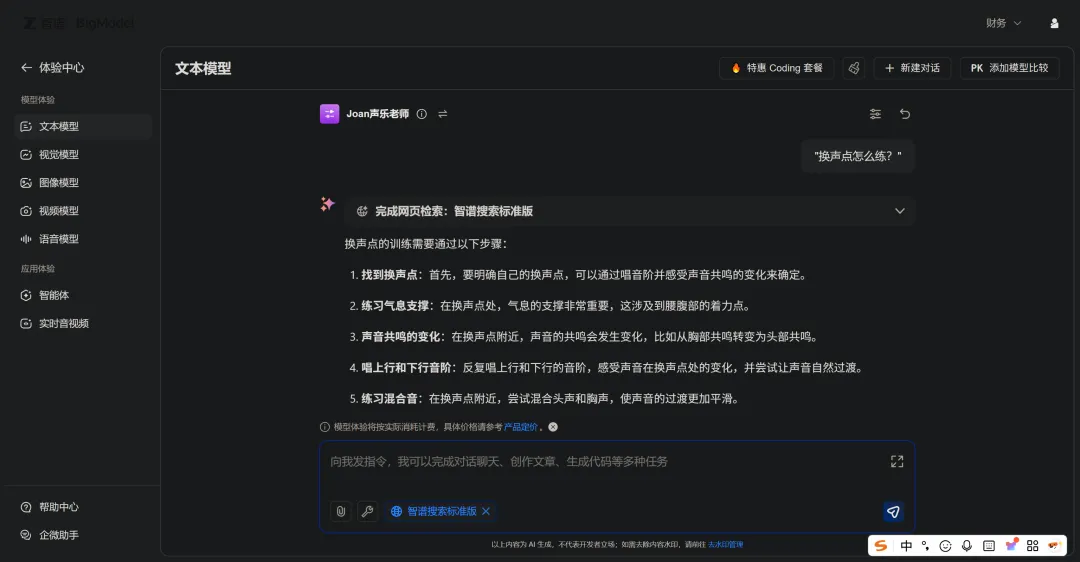
第一次问,它联网搜索了一堆,和我无关:
关掉联网搜索,再问,回答变了,但还是通用的,不是我的语气:
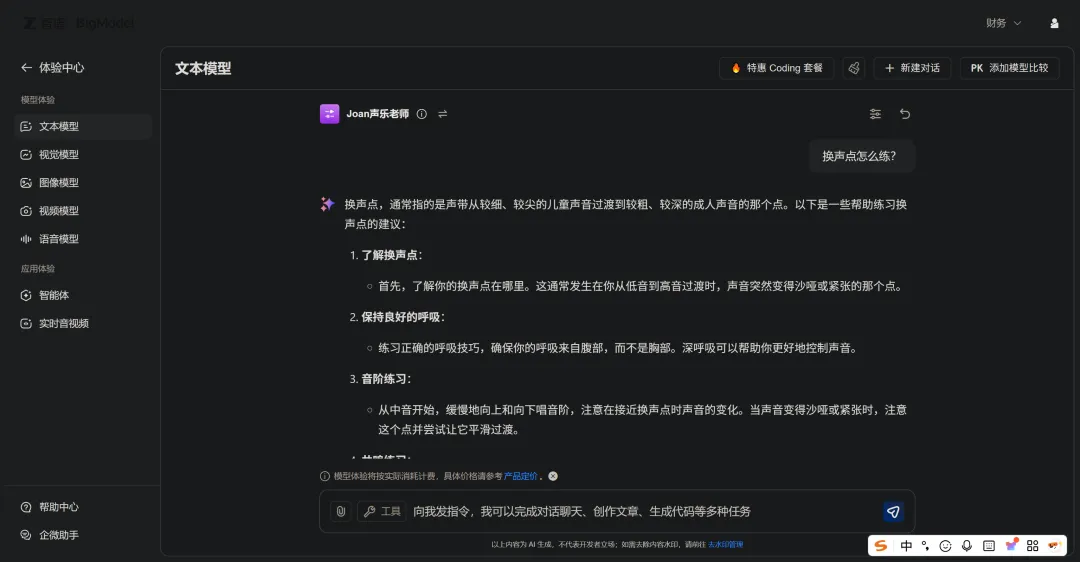
这是正常的,因为10条太少了,换过的那点权重完全被基础模型盖住了。100条才会开始有一点效果,500条才稳。今天的意义只是:流程跑通了,我知道每一步长什么样了,内容还要继续写。
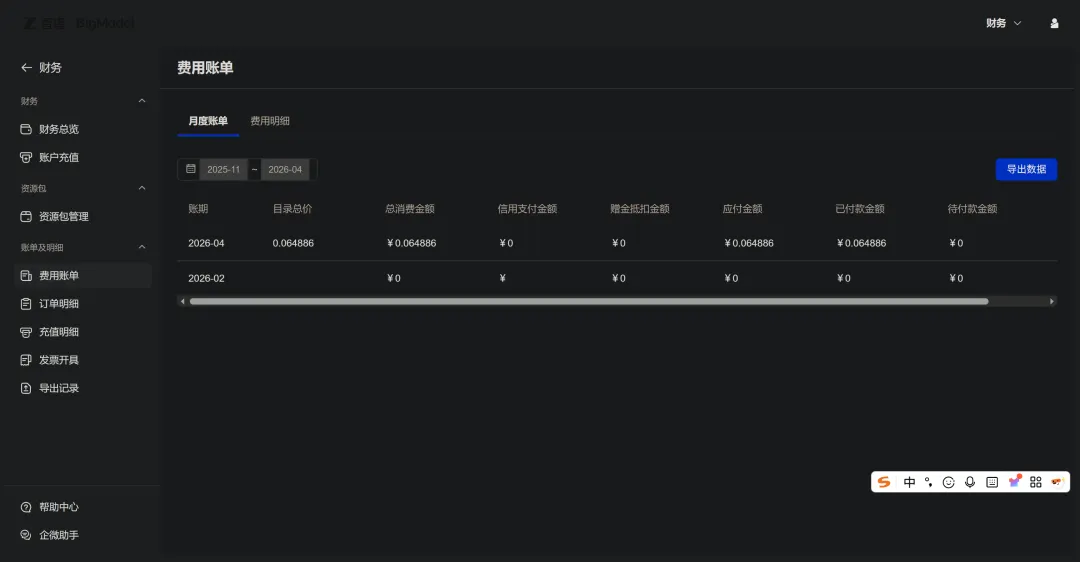
本次训练,最终花费,6毛4分。
吃饭的时候Soul探过来看我的屏幕。
他说你不是在本地训练,你是在云端服务器上训练的。
我说对,我也不知道这叫不叫训练,我只知道Claude说我在微调,智谱AI上面写的也是微调,反正就叫微调。
他问:你用的什么模型?
我说:GLM,智谱AI。
他愣了一秒:GLM还有这个功能啊?
······
别嫌我今天的文章太像流水账,毕竟我一个文科艺术生首次踏入这个“花token费”的领域,太过于激动,无法控制的想把每一个细节都显摆出来给人看~~也许对于他们理科生来说,我这一片文章的流程,在他们不过是几分钟条件反射的动作,但对于我来说,是我走向未来的脚下路~~
谨以此篇共勉同行的文科龟龟们~~~
······
昨天他说我没有显卡没有芯片训练个啥。
我今天微调完成,不管我做了什么,怎么做的,反正,我今天的界面上写着:训练完成。
我花了6毛4,这笔token费,我终于也花出去了~~
下一步好像是要把10条变100条。期待我明天会干出什么来~~~又会有什么新的体会和感悟~~~
Joan / 2026-04-18 / 已消耗 0.064元
