 夜雨聆风
夜雨聆风Zotero里躺着300篇文献,Obsidian里有零散的笔记,PDF批注散落各处。你知道答案就在某个地方,但就是找不到。
这不是你的问题。这是工具的问题。
我花了两天时间,开发了一个完整的学术研究工作流 skill。它做一件事:让文献管理变得自动化、结构化、可追溯。
整个流程如下:
自动根据用户需求进行多源搜索论文 → 自动下载PDF和元数据 使用MIneru 解析PDF → 提取表格、公式、图片 (如果zotero有PDF)会读取你的zotero批注 → 按颜色分类整理 生成结构化笔记 → 自动嵌入图表和引用链接
1. 多源文献搜索
一条命令,搜索5个数据库:
Semantic Scholar(计算机/AI领域) PubMed(生物医学) arXiv(预印本) bioRxiv / medRxiv(生物医学预印本) Google Scholar(全学科)
找到论文后,自动下载PDF到你的Obsidian仓库。文件名不是乱码,而是规范的 Chen2024_Low_Valence_Platinum_Single_Atoms_on_Covalent_Organic_Frameworks.pdf。
2. MinerU智能PDF解析
这是关键技术。
普通PDF工具只能提取文字。MinerU能做到:
提取表格:保留原始格式,转为Markdown表格 识别公式:LaTeX格式,可直接复制 分离图片:每张图单独保存,带编号 解析结构:自动识别Abstract、Methods、Results、Discussion各部分
支持200+页的长文档。扫描版PDF也能OCR识别。
3. Zotero集成:Better Notes 8色标注系统
如果你用Zotero的Better Notes插件做PDF批注,这个工作流会自动识别你的颜色系统:
🟡 黄色 → 背景/文献综述 🔴 红色 → 理论框架 🟢 绿色 → 数据/实验结果 🔵 蓝色 → 研究假设 🟣 紫色 → 实验方法 🩷 品红 → 结论 🟠 橙色 → 分析/讨论 ⚪ 灰色 → 重要标注
这是我根据zotero8 的style 插件默认内置的,你当然可以根据情况自己改,直接告诉AI来改就行
你的批注会按颜色自动分类,整理到Obsidian笔记的对应章节。
4. Obsidian自动生成结构化笔记
生成的笔记不是简单的模板填充。它会:
从MinerU提取内容:
研究背景(Introduction部分) 研究方法(Methods部分) 主要结果(Results部分) 讨论与结论(Discussion部分)
嵌入图表:
*Loss vs compute for different model sizes*整合你的批注: 把你的🟡黄色批注放在"研究背景"下,🟣紫色批注放在"研究方法"下,🟢绿色批注放在"主要结果"下。
自动创建链接: 提取关键概念,生成wikilink:[[单原子催化剂]]、[[光催化析氢]]。
5. 知识图谱构建
批量处理Zotero文献集合时,自动:
提取论文间的引用关系 识别共同的研究主题 生成Obsidian Canvas知识图谱
你能看到15篇论文如何相互关联,哪些是核心文献,哪些是方法学参考。
使用流程演示
场景:你想研究"CRISPR基因编辑"
第1步:搜索论文
"搜索CRISPR基因编辑相关论文"AI自动搜索PubMed和Semantic Scholar,返回10篇高引用论文。
第2步:下载并解析
"下载Doudna 2014年那篇,并解析"PDF下载到 Zotero Notes/Doudna2014_CRISPR_Cas9_Gene_Editing.pdfMinerU解析,提取23张图表 输出到 mineru-output/Doudna2014_CRISPR_Cas9_Gene_Editing.md
第3步:提取Zotero批注
"提取我在Zotero里的批注"你之前用🔴红色标注了理论部分,🟢绿色标注了实验数据,🩷品红标注了结论。AI自动读取这些批注。
第4步:生成笔记
"生成文献笔记"30秒后,Literature/Papers/Doudna2014_CRISPR_Cas9_Gene_Editing.md 生成完毕。
打开一看:
完整的元数据(作者、年份、DOI、PDF链接) 你的批注按颜色分类整理 MinerU提取的研究背景、方法、结果、讨论 23张图表全部嵌入,带标题 自动生成的概念链接: [[Guide RNA]]、[[Cas9 Protein]]
安装配置指南
前置要求
Claude Code CLI(AI助手)或者opencode等 Obsidian(笔记软件) Zotero(文献管理) MinerU CLI(PDF解析工具)
5分钟快速配置
第1步:安装MinerU CLI
Windows用户:
irm https://cdn-mineru.openxlab.org.cn/open-api-cli/install.ps1 | iexMac & Linux用户:
curl -fsSL https://cdn-mineru.openxlab.org.cn/open-api-cli/install.sh | bash验证安装:
mineru-open-api --version配置MinerU MCP服务器(用于AI客户端集成):
{"mcpServers": {"mineru": {"command": "uvx","args": ["mineru-open-mcp"],"env": {"MINERU_API_TOKEN": "your-token" } } }}获取MinerU API Token:
访问 https://mineru.net/apiManage/token 创建免费token(每月有免费额度) 将token填入上述配置的 MINERU_API_TOKEN字段
“有token才能提取表格和公式。没有token只能提取纯文本。
第2步:配置ai4scholar MCP
安装ai4scholar MCP服务器:
pip install ai4scholar-mcp如果已安装,升级到最新版本:
pip install --upgrade ai4scholar-mcp验证安装成功:
python -m ai4scholar_mcp.server --help获取API Key:
访问 https://ai4scholar.net/ 注册账号 在个人中心获取免费API Key
配置MCP服务器(根据你使用的AI客户端选择):
Claude Code用户:(推荐cc-switch工具进行配置)
{"mcpServers": {"ai4scholar": {"command": "python","args": ["-m", "ai4scholar_mcp.server"],"env": {"AI4SCHOLAR_API_KEY": "<your-api-key>" } } }}OpenCode用户: 在OpenCode设置中添加上述配置到MCP服务器列表。
“注意:本地模式(stdio)将MCP服务器运行在你的电脑上,相比云端SSE模式有两大优势:
PDF下载:可以直接下载PDF到你的电脑 校园网限制:在校园网环境下,可以利用学校IP下载付费论文(Springer、Nature、Wiley、Elsevier、IEEE等),无需额外付费
第3步:配置Zotero MCP(xxx需要改为你实际的端口),在设置-zoteroMCP插件里面复制即可
claude mcp add --transport http zotero-mcp http://127.0.0.1:xxx/mcp第4步:设置Obsidian路径(这里AI第一次使用时会提示你)
export OBSIDIAN_VAULT_PATH="/path/to/your/vault"第4步:创建文件夹(选择MinerU解析文件输出文件夹和zotero笔导出位置)
mkdir -p "$OBSIDIAN_VAULT_PATH"/{mineru-output,Zotero\ Notes,Literature/{Papers,Concepts},Canvases}第5步:获取MinerU API Token(可选,但强烈推荐)
访问 https://mineru.net/apiManage/token 创建免费token 设置环境变量: export MINERU_API_TOKEN="your-token"(电脑系统不同可能命令有所区别)
有token才能提取表格和公式。没有token只能提取纯文本。
安装skill
下载skill文件夹,放到 ~/.claude/skills/academic-research-workflow/
重启Claude Code,输入:
"搜索机器学习相关论文"如果返回搜索结果,说明配置成功。
效果展示
这里我用opencode进行演示:
键盘输入:WIN+R,弹出命令框,然后输入cmd出现命令行窗口(黑色的那个),复制粘贴下面的命令:
npm i -g opencode-ai等待安装完成后,输入opencode
“可能有时需要重新启动命令行窗口,即重复前面的步骤
接着,就配置自己的模型,我这里以订阅的kimi coding plan计划套餐为例
其他API提供商类似,都是在官网新建一个API key复制下来
回到opencode,输入/connect
输入kimi后,选择Kimi for code模型
配置好模型后,就是安装好skills,不会安装的可以直接发送一下命令给Kimi: 请你帮我安装下面的skills,地址如下:
https://github.com/luffysolution-svg/academic-workflow-skills配置好skills就可以直接使用了,前提是zotero MCP配置好,然后ai4scholar API,MinerU及其API也配置好才可以进行使用
“这里我不细讲ai4scholar MCP的配置,因为这个自己申请免费semantic API和使用免费crossref API、PubMedAPI,也能力的甚至web of science和Elsevier的API也可以配置,不过配置比较繁琐,有需要的可以自行问AI,然后根据你的文献源修改我这份skills,因为我闲麻烦,我就使用ai4scholar作为文献检索平台,这里是官网:https://ai4scholar.net/search,因为本文主要是介绍skills的用法和功能,这里不着重讲MinerU和数据库API的配置
然后下面是我自己使用这份skills的效果:
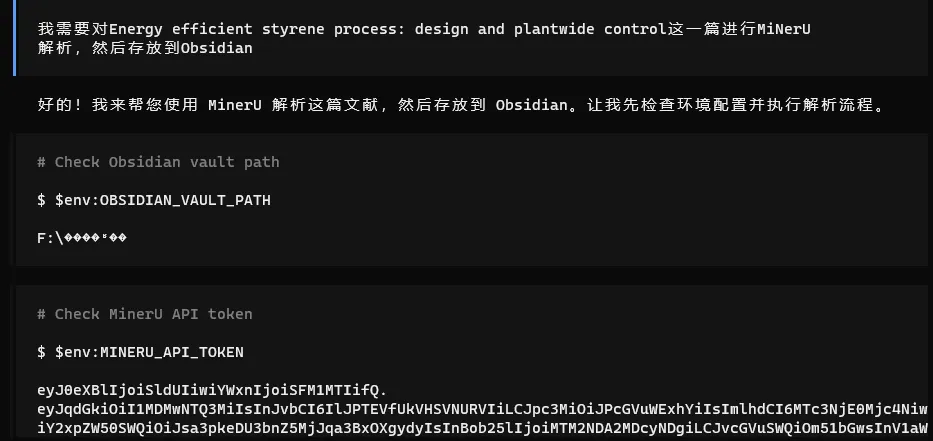
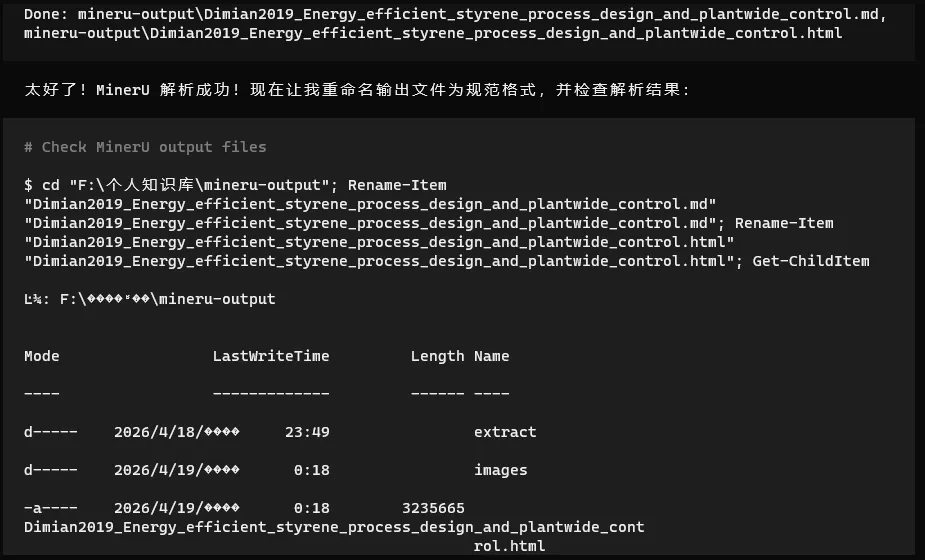
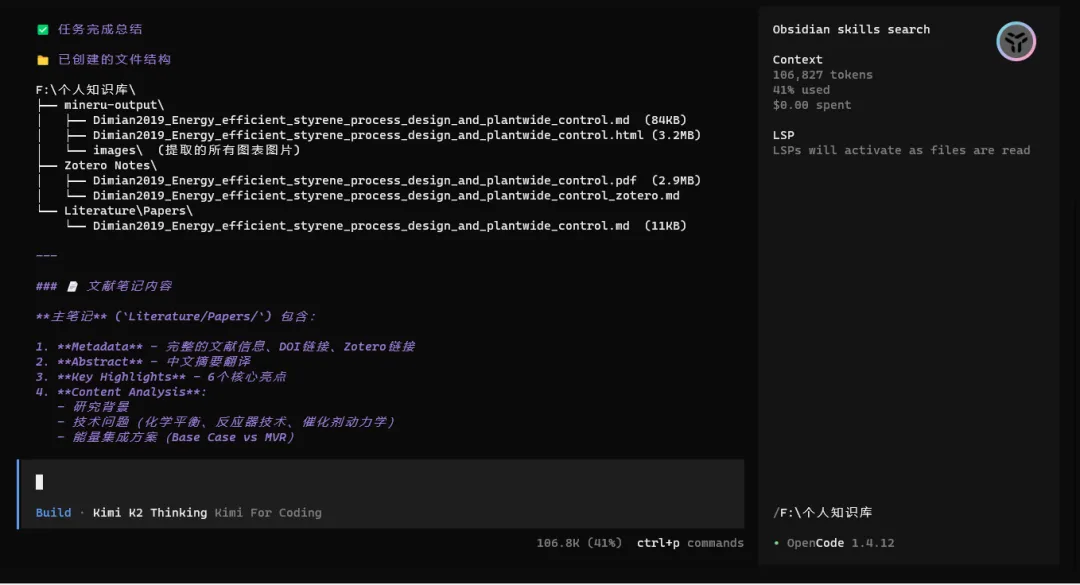
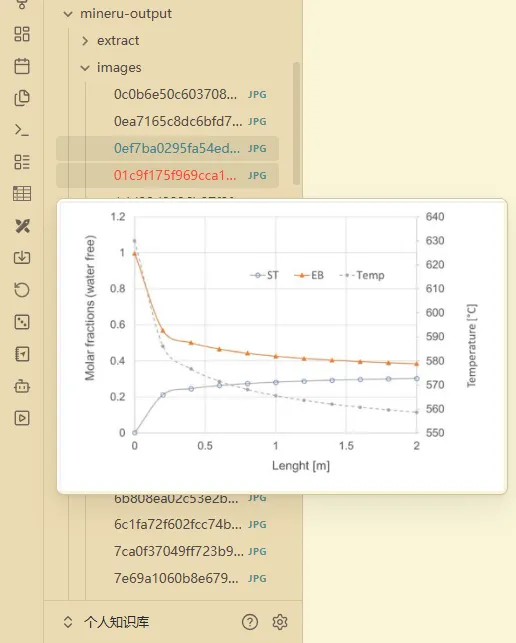
感觉还行,其实skills还可以再让AI继续迭代优化,不过作为初版效果还是比较出色的
后面我的github项目会持续更新,补充更多个人开发的实用科研skills
今天分享就到这里吧,麻烦点个赞留下吧,你的支持就是我持续创作的动力😄
资源参考
核心工具
MinerU: https://mineru.net/ - PDF智能解析工具,支持表格、公式、图片提取 MinerU API管理: https://mineru.net/apiManage/token - 获取免费API Token ai4scholar: https://ai4scholar.net/ - 学术文献检索平台,整合多个数据库 OpenCode: https://github.com/opencodeai/opencode - 开源AI编程助手 Claude Code: https://claude.ai/code - Anthropic官方AI编程助手
文献数据库
Semantic Scholar: https://www.semanticscholar.org/ - AI驱动的学术搜索引擎 PubMed: https://pubmed.ncbi.nlm.nih.gov/ - 生物医学文献数据库 arXiv: https://arxiv.org/ - 预印本论文库 bioRxiv: https://www.biorxiv.org/ - 生物学预印本 medRxiv: https://www.medrxiv.org/ - 医学预印本 Google Scholar: https://scholar.google.com/ - 全学科学术搜索
辅助工具
Zotero: https://www.zotero.org/ - 开源文献管理软件 Obsidian: https://obsidian.md/ - 本地知识管理工具 Better Notes: https://github.com/windingwind/zotero-better-notes - Zotero批注增强插件 Zotero MCP: https://github.com/zotero/zotero-mcp - Zotero的MCP服务器
项目地址
Academic Workflow Skills: https://github.com/luffysolution-svg/academic-workflow-skills - 本文介绍的工作流技能包
