 夜雨聆风
夜雨聆风

🎵 本文主题曲 叁笙优居 AI 生成 · 空灵民谣
导读: 2026 年 4 月,阿里云、腾讯云、AWS、谷歌云在十天内先后调价。涨价本身不稀奇,稀奇的是这次涨的方向——从便宜往贵调。互联网做了二十年的"规模越大、单价越低"的曲线,在 AI 这一代,头一次被摁着反了过来。
2026 年 4 月 18 日清晨,一封来自阿里云的客户通知静静躺在很多创业公司 CTO 的邮箱里。
邮件很短,措辞克制。大意是:因上游算力成本持续上行,阿里云部分 AI 推理产品将在五月起逐步调整价格,部分高端 GPU 实例的按需价格上调区间在两成到三成之间。没有发布会,没有热搜话题,甚至连公众号的推文都没发一条。
但在开发者的群里,这封邮件炸开了锅。
我感觉之前没抢7.8、8.8元/月的Coding plan损失了一个亿。
一位做 AI 陪伴应用的朋友当天发了条朋友圈。他算了一笔账:产品月活刚过五万,每月光是大模型 API 的调用支出就占到收入的六成。四月这一轮调价之后,这个比例会顶到七成出头。他加了一句:"不是我们跑不通模型,是模型跑不通我们。"

这不是阿里云今年第一次动价格。根据公开的服务条款历史,阿里云在 2026 年已经是第三次调整 AI 相关产品的价格结构——三月一次、四月上旬一次、四月十八日又一次。每次幅度不算夸张,但方向高度一致:朝上。
更耐人寻味的是,这不是阿里云一家的动作。
往前翻十天。腾讯云调整了混元系列的 API 计费模型,新的 HY2.0 高阶版本单位价格相比上一代,据开发者社区测算涨幅接近四倍。再往前一周,百度云文心系列的部分企业套餐悄悄上调了 5% 到 30% 不等。字节的火山引擎、京东云,也分别在这段时间把自家大模型的推理单价往上挪了一档。
海外更热闹。AWS 把 p5e 实例的按需价格从每小时三十四美元出头,拉到接近四十美元;谷歌云部分 Gemini 相关实例的对外报价最高翻了一倍;Azure 紧跟着调整了 OpenAI 系列的企业端配额和计费规则。
一个正常的市场,不应该这么整齐。
要看懂这件事,得把时间轴再往前拉一点。
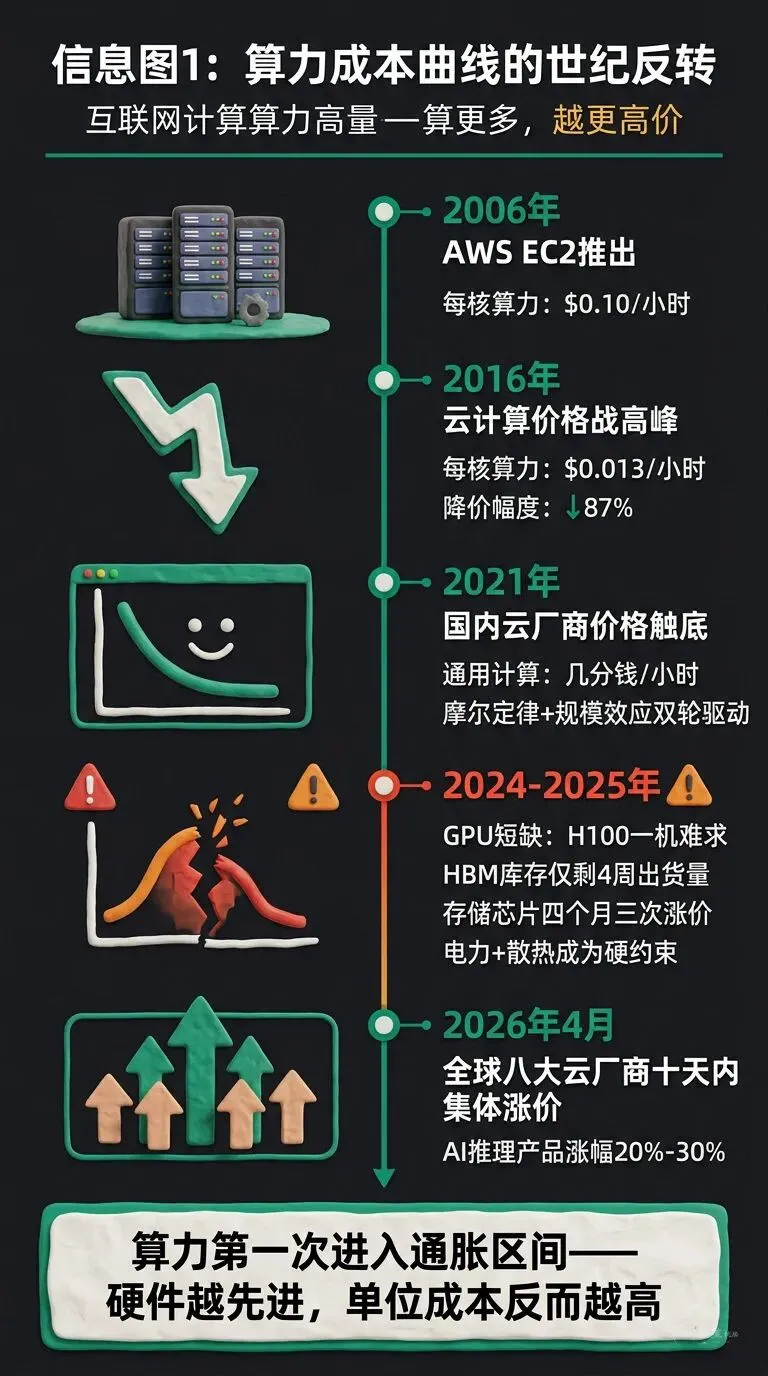
2006 年,AWS 正式推出 EC2 的那一年,英特尔至强处理器的每核算力价格是每小时 10 美分。2016 年,AWS 同档位实例的价格,被打到每小时 1.3 美分。到了 2021 年前后,以阿里云、腾讯云为代表的国内云厂商,把最便宜的通用计算资源压到每小时一两分钱人民币。
这就是过去二十年所有互联网从业者默认的那条"微笑曲线":芯片越做越密,机房越建越大,单位算力的价格一路朝下,而且看上去没有尽头。
摩尔定律 + 规模效应,两个轮子一起转。
互联网这二十年所有的商业模式——免费邮箱、免费搜索、免费社交、亿级月活的短视频、全行业的 SaaS——全部是建在这条向下的曲线上。"先把用户搞上来,后面服务器成本只会越来越便宜",这是 2010 年到 2020 年,几乎所有互联网创业者和投资人的底层共识。
AI 来之前,这个共识没出过问题。
出问题是从 2024 年下半年开始的。

一位长期跟踪云计算行业的分析师给我讲过一个细节。2024 年 Q3,他去某家头部云厂商的机房出差,发现机柜密度被临时调整过——一整排原本设计能装 42 台服务器的标准机柜,实际只装到 24 台左右。工程师跟他解释,不是买不到服务器,是电和散热撑不住。塞满了,功率会超上限,跳闸。
从那之后,云厂商卖的不再是"算力",而是"电力配额 + 散热配额 + 芯片配额"这三样东西的合计许可。任何一样短缺,整条线的定价逻辑都会被迫重写。
2025 年全年,这三样短缺同时发作。
英伟达的 H100、H200 在公开市场上一机难求。据多家媒体报道,头部云厂商的 H100 整机租赁价格在 2025 年一年之内涨幅超过 40%;Meta、微软、谷歌、甲骨文,加上国内的几家大厂,把 2025 年出厂的 H 系列 GPU 几乎全部吃光,二级市场开始出现"插队费"。
HBM 紧跟着出事。HBM 是贴在 GPU 旁边的高带宽显存,一颗顶级 GPU 的性能高低,有时候取决于 HBM 够不够。据公开的产业链信息,2025 年底 SK 海力士的 HBM3E 成品库存曾一度只剩下 4 周左右的出货量。
再加上 DRAM、NAND 在 2025 年下半年的涨价潮——全球存储芯片三大厂在四个月内先后三次上调合约价——整个 AI 算力的上游,进入了一个几乎所有人都没经历过的"硬件侧通货膨胀"区间。
老的那条微笑曲线,从 2025 年底开始,事实上被拧断了。
如果你最近读过黄仁勋在 2026 年 GTC 上的那场 keynote,你会注意到他讲了一句后来被反复引用的话。
大意是:"这一代最重要的商品,不是手机,不是汽车,是 Token。Token 就是这一代的石油。"
这句话听上去像是讲给投资人听的故事。但如果你把目光移到国内,阿里巴巴集团 CEO 吴泳铭在 2026 年初的一封内部信里,讲了一件更具体的事——他把阿里云的未来战略,重新编组成了一个叫"Token Hub"的内部项目,把模型调用量、API 调用量、推理请求量、训练任务量,全部统一成一个指标:Token。
一切可计价、可调度、可结算的 AI 服务,都折算成 Token。
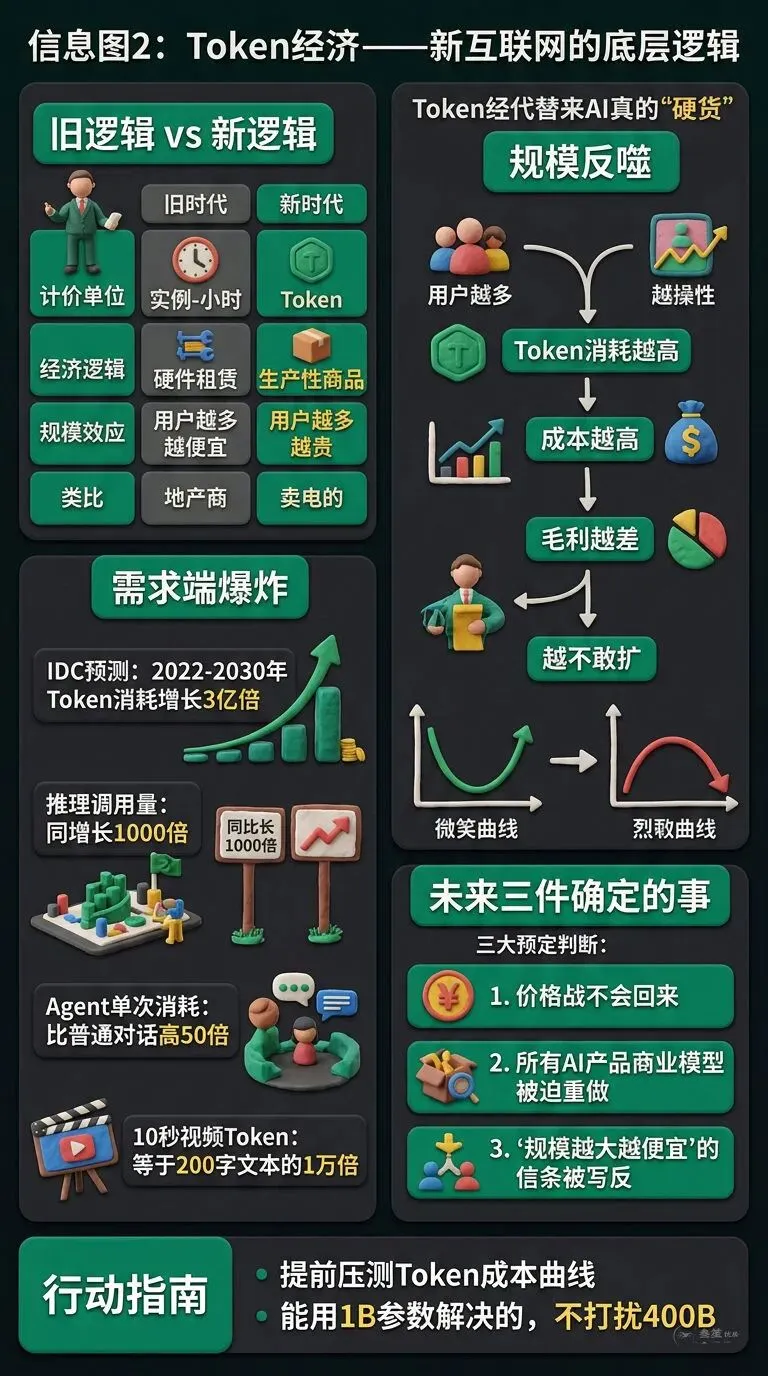
这是云厂商集体涨价背后的第二层变化——定价单位,从"实例-小时"切换到了"Token"。
这两个单位的差别看起来只是换了个名词,本质上是两套完全不同的经济学。
实例-小时定价,是典型的"硬件租赁逻辑":我把机器租给你,机器本身有折旧曲线、有规模摊销、有闲置损失。用户越多,单位时间就能越便宜。
Token 定价,是典型的"生产性商品逻辑":我把可消费的计算产出卖给你,背后是实时消耗的电、实时烧损的显卡、实时占用的带宽。用户越多,系统越紧,单位反而越贵。
一位头部互联网大厂的基础设施负责人私下说过一句话:"做云的这十年,我们一直把自己当地产商。现在我们发现,我们其实是卖电的。"
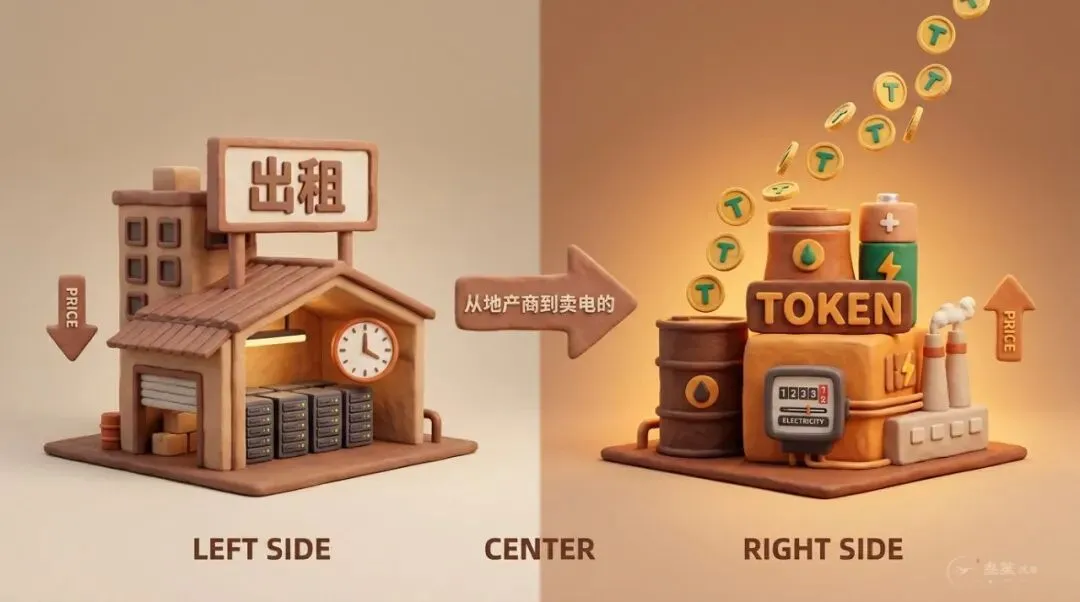
卖电的生意,是没有"规模越大越便宜"这一说的。夏天用电高峰,电价不会因为全国空调开得多就跌下去,只会因为紧张而一档一档往上涨。Token 经济,正在把整个云计算行业,从地产逻辑重新改造成能源逻辑。
对应的商业现象就变得好解释了。
Anthropic 2026 年初一次小范围的调整,把部分 Claude 订阅套餐的每月 200 美元档位,在后台设置了一个"软性配额"。超过这个配额继续使用,后续生成会走更贵的按量计费。据英文开发者社区披露的截图,有重度编码用户在一个月内被统计到的理论算力消耗超过了 5000 美元——放在一年前,200 美元档位几乎是随便用的。
OpenAI 这一年也开始把 Pro 和 Enterprise 两个档位的实际可用量拉开差距。在开发者论坛里,你能看到大量类似的描述:同样的订阅费,去年能跑完一整个项目,今年跑到下旬就开始被限流。
降级的不是产品,是那个"按月固定付费、算力随便用"的旧商业模式。
国内这边,字节、阿里、百度的大模型 API 几乎都在 2026 年上半年完成了从"每千 Token 免费/象征收费"到"清晰阶梯定价"的过渡。Token 终于从营销噱头,变成了真正的计价单位。
我见过一家做 AI 辅导产品的小公司。两位创始人,三个工程师,一个运营,年初刚拿了一笔 Pre-A。
他们的产品很受欢迎,上线半年 DAU 干到 6 万,朋友圈里都在夸这个团队能打。
但三月底我再见他们,创始人愁眉苦脸。他给我看后台的一张曲线图:用户数在往上涨,毛利率在往下掉。
原因简单粗暴:用户越多,单日 Token 消耗越大,而上游 API 单价在涨。他算了一笔账,如果维持现在的定价(月费 29 元),DAU 超过 10 万的那一天,他们会净亏损。
他们最后的选择,不是扩用户,而是主动收缩免费额度、引导高付费用户、把低活跃用户逐步清洗出去。
这在互联网的上一个时代是匪夷所思的操作。过去所有互联网产品的本能反应都是:先增长,后变现。现在这群创业者的动作反过来了:先变现,再增长。
这就是 AI 产品侧正在发生的规模反噬。
用户越多 → Token 消耗越高 → 成本越高 → 毛利越差 → 越不敢扩用户。原来的"微笑曲线"在 AI 产品这里,被折成了一条皱眉线。

类似的剧情正在不同规模的玩家身上反复上演。
• Cursor、Windsurf 这类编码 IDE,在 2026 年调整了计费模型,把"无限使用"改成按请求次数/按模型消耗计价 • 国内多家 AI 搜索产品,默默降低了免费版单日请求上限 • 某家头部的 AI 陪伴产品,公开内部数据显示,月活破百万之后的单用户算力成本比月活二十万时高出了接近一倍
这些现象叠在一起看,就是一个共同的结论:
2026 年 3 月,IDC 发布了一份关于全球 Token 消耗量的研究报告。里面有一个数字被很多朋友发给我问是不是打错了。
报告的原话大意是:从 2022 年到 2030 年,全球累计 Token 消耗量将增长约 3 亿倍。
三亿倍。不是三十倍,不是三千倍,是三亿倍。
这个数字如果成立,意味着现在整个人类已经消耗掉的 AI Token,在 2030 年看,大概就是一粒砂。
我去查了一下这份报告的测算逻辑。它基于三个假设:一是推理替代训练,成为未来 Token 消耗的主力;二是 Agent 化大规模铺开,单次交互不再是一问一答,而是模型自己在后台调用几十步思考和工具;三是多模态常态化,视频、语音、图像全部计入 Token 统计。
这三件事,2026 年上半年都在同步发生。
• 推理层面:国内某头部云厂商公开披露,其 2026 年 Q1 的推理 Token 调用量同比增长超过 1000 倍——两年前的同一口径数据基本可以忽略 • Agent 层面:以 Claude Code、Gemini CLI、Cursor Agent 为代表的编程 Agent,单次任务平均 Token 消耗比普通对话高 50 倍以上 • 多模态层面:生成一段 10 秒视频所需的 Token,是生成一段 200 字文本的一万倍起步
这三个东西共同作用的结果就是:需求端的增长速度,远远超过供给端的硬件扩产速度。
英伟达建不了那么多 fab,台积电先进制程产能就那么多,SK 海力士的 HBM 产线扩产需要至少 18 个月。短期内,需求涨一个数量级,供给只能涨一个零头。
剪刀差一旦形成,价格就一定会涨。
这就是今年四月这一轮集体调价的底层原因:不是云厂商想多赚钱,而是它们自己的进货成本也在一口气往上蹿。
把上面所有的事情连起来看,未来 12 到 24 个月几乎可以确定会发生三件事。

第一件事:云厂商之间的价格战不会回来,至少不会在 AI 算力上回来。
过去十年,云厂商之间的价格战是常态——经常一年能看到两三轮官宣的降价。现在不会了。当上游硬件本身在涨,下游互相打价格战没有意义。更大概率看到的是:各家把定价模型精细化,推出更多"峰谷电价"式的阶梯产品——白天贵、夜里便宜;常规模型便宜、推理密集型贵。
第二件事:所有 AI 产品的商业模型会被迫重做一次。
订阅制无限用,注定难以维持。取而代之的会是分档订阅 + 超额按量、算力预算上限、模型降档使用等新的产品结构。这对用户不见得是坏事——你会更清楚自己到底在为什么付钱,便宜模型和贵模型的体验差异也会被显性化。
第三件事,也是最本质的:
过去一个好产品的评价标准是:能不能做到服务十亿人的时候,比服务一百万人的时候单用户成本更低。
未来一个好 AI 产品的评价标准,会变成:能不能在服务十亿次调用的时候,和服务一百万次调用时单位成本基本持平。
这个转变不小。它会重塑一整代产品经理的工作方式,会重塑一整代创业者的融资叙事,会重塑一整代 VC 看 AI 项目的估值模型。
写到这里,必须收一收。不是所有人都关心云厂商后台的价格曲线。但这轮涨价,对两类普通人真的值得留个心眼。
一类是做 AI 产品和内容的个人/小团队。
建议认真做两件事:
1. 把你的 Token 成本曲线提前压成可预测。 选供应商时,不要只看当下单价,要看"量上去之后的分档价"。跑一个简单的模型:如果我的 DAU 翻十倍,我的月成本会翻几倍?翻五倍以下说明计价合理,翻十倍以上就有踩坑风险。 2. 不要浪费在大模型上做小事。 很多小事完全可以用开源模型本地跑,或者用蒸馏后的小模型。能用 1B 参数解决的问题,不要去打扰 400B 的旗舰模型。省下来的钱,可以是你团队的工资。
另一类是每个月在用 Claude、ChatGPT、Gemini Pro 的普通用户。
老实说,如果你现在每月订阅费还能正常用下来,就好好珍惜。过去一年订阅价没涨过、但可用量在悄悄缩水,本质上是一次"隐性涨价"。未来你大概率会看到的是:同样的钱,能用的额度越来越少;或者加钱升级到更贵的档位。这不是哪家公司变坏了,这是整条产业链的成本在往下游转移。
互联网做了二十年的"越多越便宜",第一次停了下来。
它停下来的那一刻,很安静,没有仪式感——只是一封平平无奇的涨价邮件,躺在某个创业者的收件箱里。
但回头看,这封邮件很可能就是下一代互联网故事真正的开头。
如果你最近也在做 AI 相关的产品/应用,评论区聊两句:你被算力成本"教育"过吗?你现在是怎么处理这条成本曲线的?
📎 信息来源
• 阿里云官方客户通知邮件(2026年4月18日) • IDC 全球 Token 消耗量研究报告(2026年3月) • 黄仁勋 GTC 2026 Keynote 演讲 • 阿里巴巴集团 CEO 吴泳铭 2026 年内部信 • AWS EC2 历史定价数据(2006-2026) • SK 海力士 HBM3E 产能与库存公开信息 • Anthropic Claude 订阅计费政策调整公告 • 国内外云厂商 2026 年 Q1-Q2 公开调价公告
 |
 |
 |
