 夜雨聆风
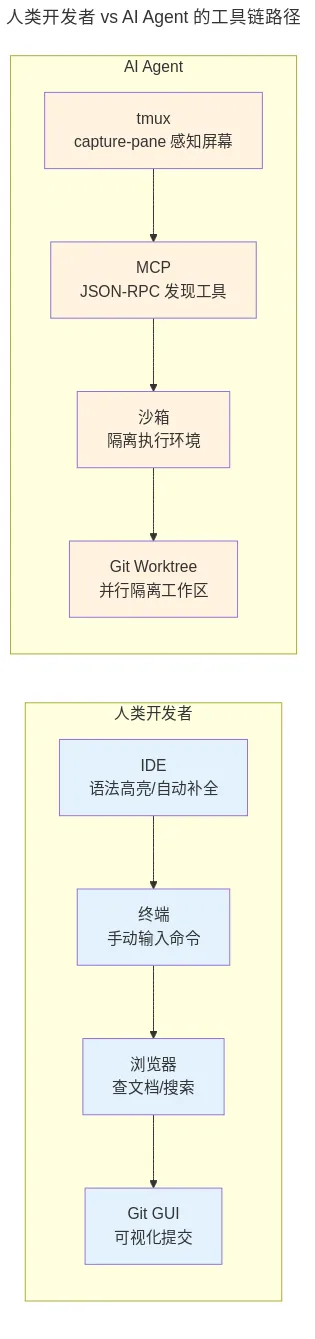
夜雨聆风你用 VS Code 写代码,用 iTerm2 开终端,用 Chrome 查文档。这套工具链陪了你好几年,顺手得像呼吸一样自然。
但 AI Agent 不这么工作。
Agent 不需要语法高亮——它直接读 AST。Agent 不需要标签页管理——它同时操作 20 个终端窗格。Agent 不需要"撤销"按钮——它需要整个文件系统可以快照回滚。
2025 年底到 2026 年初,一批新工具密集出现:dmux、workmux、NTM、AgentFS、cmuxLayer……它们的名字你可能没听过,但它们代表了一个清晰的趋势——开发工具正在为 AI 重新设计。不是在旧工具上加个 AI 插件,而是从 Agent 的感知方式、行动方式、协作方式出发,重新思考"工具"应该长什么样。
这篇文章拆解 6 个这样的工具范式。每一个都回答同一个问题:当使用者从人变成 AI,工具的设计逻辑会发生什么变化?
IDE 语法高亮/自动补全
一、tmux:不是窗口管理器,是 Agent 的感知-行动接口
tmux 诞生于 2007 年,最初是给运维工程师用的——SSH 断了会话还在,分个屏左边看日志右边敲命令。人类用了它快 20 年,用法基本没变。
但 2025 年开始,tmux 突然成了 AI Agent 圈子里的热门话题。Robert Travis Pierce 写了一篇广为流传的文章,标题直接说:「tmux 就是你已经拥有的多 Agent 编排层」。Rohan Verma 用 tmux 编排了一个本地 LLM 集群。claude-tmux、dmux、NTM、workmux、amux、cmuxLayer——半年内冒出来至少六个基于 tmux 的 Agent 编排工具。
为什么是 tmux?
答案藏在两个命令里。
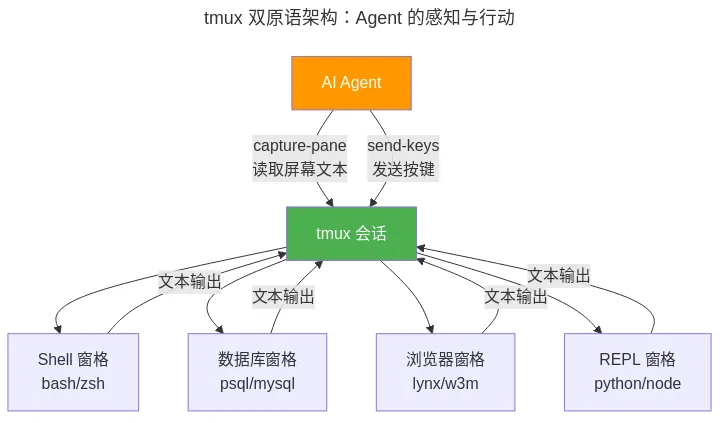
capture-pane:Agent 的眼睛。 这个命令返回终端窗格当前屏幕上的文本内容——就是你盯着屏幕看到的那些字。加上 -J 参数合并折行,加上 -S -50 参数往上多看 50 行。Agent 调一次 capture-pane,就获得了和人类"扫一眼屏幕"完全等价的信息。
# Agent 的"看一眼屏幕"lines = pane.cmd("capture-pane", "-p", "-J", "-S-50").stdoutsend-keys:Agent 的手。 这个命令往窗格里发送按键,和人类敲键盘一模一样。Agent 不需要调 API、不需要 SDK,直接"打字"。
# Agent 的"敲一行命令"pane.send_keys("grep -r 'TODO' src/", enter=True)这两个原语的对称性是关键:Agent 用和人类完全相同的方式感知(看屏幕)和行动(敲键盘)。终端里运行的任何工具——grep、psql、python REPL、curl——都不知道操作者是人还是 AI。tmux 成了一个"万能适配器",把所有终端工具都变成了 Agent 可以操作的工具,零集成成本。
AI Agent
实际应用中,tmuxinator 让你用 YAML 声明式地定义 Agent 拓扑:哪些 Agent、各自的工作目录、权限级别、窗格布局。一条 tmuxinator start agents 命令,整个 Agent 编队就位。
Agent 之间的协调也分两层:异步层靠共享磁盘文件(markdown 状态文件),同步层靠 send-keys 广播命令。想让所有 Agent 立刻重新读取配置?一个 for 循环遍历所有窗格,每个窗格发一条 /sync。
# 广播同步命令到所有 Agent 窗格fortargetin"agents:1.1""agents:2.1""agents:3.1"; dotmuxsend-keys-t"$target"'/sync'Entersleep0.5done这不是什么新框架。这是一个 2007 年的终端工具,因为设计上恰好满足了 Agent 的核心需求——文本感知 + 按键行动——在 2026 年焕发了第二春。
二、Git Worktree:不是分支管理,是多 Agent 并行的物理隔离层
人类开发者用 Git 分支做什么?切换功能开发上下文。git checkout feature-x,改几个文件,提交,切回去。一次只在一个分支上工作,因为工作目录只有一个。
Agent 的需求完全不同。当你同时跑 5 个 Agent,每个负责一个独立任务——一个写前端组件,一个修后端 API,一个跑测试,一个做代码审查,一个写文档——它们不能共享同一个工作目录。文件锁冲突、.git/index.lock 争抢、半写入状态的文件被另一个 Agent 读到……这些问题在人类开发中几乎不存在(因为你一次只做一件事),但在多 Agent 场景下是致命的。
git worktree 解决了这个问题。它让你从同一个仓库创建多个独立的工作目录,每个目录检出不同的分支,共享同一个 .git 对象存储。不需要 clone 五份仓库,不需要额外磁盘空间,每个 Agent 有自己的文件系统视图,互不干扰。
# 为每个 Agent 创建独立工作区gitworktreeadd../agent-frontendfeature/new-uigitworktreeadd../agent-backendfeature/api-refactorgitworktreeadd../agent-testsfeature/test-coverage围绕这个能力,2025-2026 年出现了一批专门的编排工具:
dmux 是一个开源 CLI/TUI,支持 11 种以上的 Agent(Claude Code、Codex、Gemini CLI 等),自动为每个 Agent 创建 worktree + tmux 窗格。一条命令启动,一个 TUI 面板监控所有 Agent 状态。
workmux 用 Rust 写的,理念是"一个 worktree、一个 tmux 窗口、一个 Agent"。它还支持 Zellij 和 Kitty 等终端,不绑定 tmux。
NTM(Named Tmux Manager) 加了冲突检测——如果两个 Agent 试图修改同一个文件,NTM 会发出警告。它还有广播功能,一条命令同时给所有 Agent 发指令。
claude-tmux 是 Python 包,专门为 Claude Code 设计,带 TUI 仪表盘和"注意力系统"——当某个 Agent 需要人类输入(权限请求、确认问题)时,自动跳转到那个窗格。
这些工具的共同点:它们不是在教 Agent 怎么用 Git,而是把 Git worktree 变成了 Agent 的"物理隔离间"。每个 Agent 在自己的房间里工作,改完了提 PR,由人类或另一个 Agent 做 review。
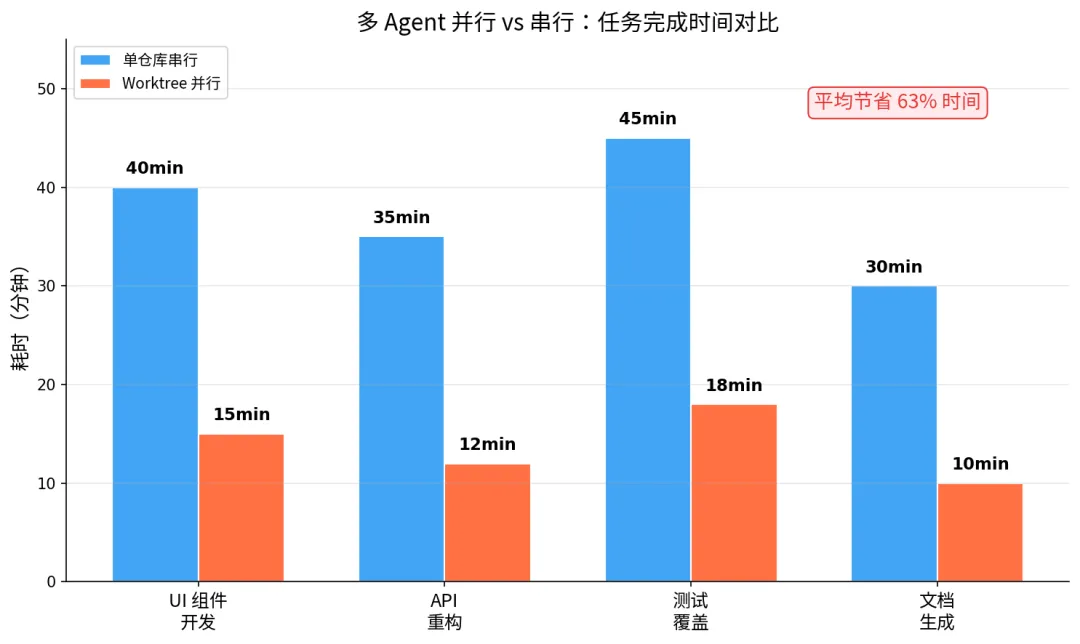
柱状图:四组任务对比,蓝色柱表示单仓库串行耗时分别为 40/35/45/30 分钟,橙色柱表示 Worktree 并行耗时分别为 15/12/18/10 分钟,并行模式平均节省 63% 时间
什么时候该用 worktree 隔离?一个简单的判断标准:如果两个 Agent 的任务可能修改同一个文件,就必须隔离。如果它们操作完全不同的文件集(比如一个改前端、一个改后端),共享工作目录也能工作,但隔离仍然更安全。
三、沙箱执行环境:不是安全合规,是让 Agent 放心试错的"可丢弃世界"
人类开发者在本机跑代码,出了问题 Ctrl+Z 撤销,或者 git stash 暂存。我们对自己的操作有直觉——不会随便 rm -rf /,不会在生产数据库上跑未测试的 SQL。
Agent 没有这种直觉。
一个被要求"清理旧文件"的 Claude Code 会话,可能删掉花了几周搭建的配置目录。一个被要求"优化数据库查询"的 Agent,可能在生产表上跑了 ALTER TABLE。这不是 Agent 恶意——它们在尽力完成任务,只是对"后果"没有人类的本能判断。
沙箱的意义不是"防止 Agent 作恶",而是"让 Agent 可以大胆尝试"。在一个可丢弃的环境里,Agent 可以自由执行代码、安装依赖、修改文件,试错成本为零。
当前的沙箱方案分三个层级:
容器级(Docker): 最常见,启动快,但共享宿主机内核。如果 Agent 生成的代码利用了内核漏洞(虽然概率低),隔离就被突破了。适合可信度较高的场景。
MicroVM 级(Firecracker/gVisor): 每个沙箱有独立内核,启动时间约 150ms。E2B 和 Modal 等平台底层用的就是这个。安全性接近虚拟机,性能接近容器。这是目前生产环境的主流选择。
文件系统级(AgentFS): Turso 团队做的项目,用 SQLite 数据库模拟文件系统。Agent 的所有文件操作都发生在 SQLite 里,支持 copy-on-write——Agent 修改文件时,原始文件不动,只记录差异。可以随时快照、回滚、审计每一步操作。

Docker 容器
有意思的是,这三个层级不是互斥的。一个典型的生产部署可能是:外层 Firecracker MicroVM 提供内核隔离,内层 AgentFS 提供文件级快照和审计。Agent 在 MicroVM 里自由执行,每一步文件操作都被 AgentFS 记录,出了问题可以精确回滚到任意时间点。
E2B 是目前最流行的托管沙箱平台,提供 API 让你在 200ms 内启动一个完整的 Linux 环境,Agent 可以在里面跑任意代码。Modal 更偏向计算密集型任务,支持 GPU。Daytona 则专注于完整的开发环境沙箱,包括 IDE 和预配置的工具链。
对于个人开发者,最简单的起步方式是 Docker + 限制权限:
# 最小权限沙箱:只读挂载源码,可写临时目录dockerrun--rm\--read-only\--tmpfs/tmp\-v$(pwd)/src:/workspace/src:ro\-v$(pwd)/output:/workspace/output\--networknone\python:3.12-slim\python/workspace/src/agent_task.py--read-only 让容器文件系统只读,--network none 断网,-v :ro 只读挂载源码。Agent 只能往 /tmp 和 /workspace/output 写东西。简单粗暴,但有效。
四、MCP 协议:不是 API 集成,是 Agent 的"万能适配器"
人类开发者接入一个新服务,流程大概是:读文档 → 找 SDK → 装依赖 → 写集成代码 → 处理认证 → 调试。每个服务都要走一遍。
Agent 面对的问题更严重。一个通用 Agent 可能需要操作数据库、读写文件、调用 API、发消息、查日志……每个工具都有自己的接口格式。如果每个都要写定制集成,Agent 框架会变成一个巨大的"胶水代码"集合。
MCP(Model Context Protocol)是 Anthropic 在 2024 年 11 月开源的协议,到 2026 年 4 月,公开目录里已经有超过 2300 个 MCP Server,Claude、Cursor、Windsurf、VS Code 等 200 多个工具原生支持。
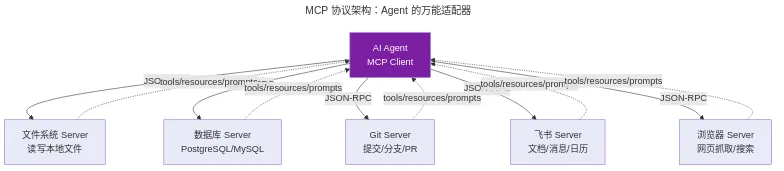
它的核心思路很简单:定义一个标准的 Client-Server 协议,让 Agent(Client)可以通过统一的 JSON-RPC 接口发现和调用任何工具(Server)。
AI Agent MCP Client
每个 MCP Server 暴露三类能力:
- Tools:可执行的操作(查询数据库、创建文件、发送消息)
- Resources:可读取的数据源(文件内容、数据库 schema、API 文档)
- Prompts:预定义的交互模板(代码审查流程、部署检查清单)
Agent 连接一个 MCP Server 后,先调用 tools/list 获取所有可用工具及其参数 schema。不需要提前知道这个 Server 能做什么——运行时自动发现。这和人类"先读文档再写代码"的模式完全不同。Agent 的工具发现是程序化的、即时的。
配置也很简单,一个 JSON 文件搞定:
{"mcpServers": {"filesystem": {"command": "npx","args": ["-y", "@modelcontextprotocol/server-filesystem", "/workspace"] },"postgres": {"command": "uvx","args": ["mcp-server-postgres", "--connection-string", "postgresql://localhost/mydb"] } }}MCP 对 Agent 工具链的意义在于:它把"集成 N 个工具"的问题从 O(N) 降到了 O(1)。Agent 只需要会说 MCP 协议,就能操作任何实现了 MCP Server 的工具。新工具上线?加一行配置,Agent 自动发现它的能力。
这和 tmux 的思路形成了互补:tmux 让 Agent 通过"看屏幕 + 敲键盘"操作任何终端工具(无需集成),MCP 让 Agent 通过结构化协议操作任何服务(标准化集成)。前者是"零成本适配",后者是"一次集成、处处可用"。
五、文件系统监听:不是 CI/CD 触发器,是 Agent 的"事件驱动神经"
人类开发者保存文件后会做什么?看一眼终端有没有报错,或者手动跑一下测试。这是"拉取"模式——你主动去检查。
Agent 更适合"推送"模式——文件一变,立刻触发动作。不需要轮询,不需要定时检查,事件驱动。
Linux 内核的 inotify 子系统从 2005 年就提供了这个能力。inotifywait 命令可以监听目录变化,文件创建、修改、删除都能捕获。但在 AI Agent 场景下,这个能力被赋予了新的意义。
传统用法:文件变了 → 触发构建/测试(CI/CD 场景)。 Agent 用法:文件变了 → 触发 Agent 重新分析 → 自动修复 → 验证 → 提交。
Kiro 的 Hook 机制就是这个思路的产品化实现。你可以定义:当 .ts 文件被编辑时,自动让 Agent 跑 lint 并修复问题。
{"name": "Lint on Save","version": "1.0.0","when": {"type": "fileEdited","patterns": ["*.ts", "*.tsx"] },"then": {"type": "runCommand","command": "npm run lint" }}更高级的用法是链式触发:
- 文件保存 → Hook 触发 lint
- lint 发现错误 → Hook 触发 Agent 分析错误
- Agent 修复代码 → 文件再次保存 → 再次 lint → 通过
这形成了一个自动修复循环。人类开发者需要手动完成的"保存 → 看报错 → 改代码 → 再保存"循环,Agent 通过文件监听 + Hook 自动完成。
在 tmux 场景下,文件监听还有另一个用途:Agent 间通信。多个 Agent 共享一个状态文件,每个 Agent 用 inotify 监听这个文件。一个 Agent 写入新状态,其他 Agent 立刻感知到变化并重新读取。这比轮询高效得多,延迟在毫秒级。
# Agent 监听共享状态文件变化inotifywait-m-emodify/workspace/shared/agent_state.md |whilereadpathactionfile; doecho"状态文件已更新,重新同步..."# 触发 Agent 重新读取状态tmuxsend-keys-tagents:1.1'/sync'Enterdone文件监听对 Agent 的价值不在于"监听"本身,而在于它把 Agent 从"被动等待指令"变成了"主动响应环境变化"。这是从工具到自主体的关键一步。
六、AgentFS:不是存储方案,是可审计、可快照、可回滚的 Agent 状态层
前面提到 AgentFS 是沙箱方案之一,但它值得单独拿出来说,因为它代表了一种全新的设计理念:文件系统本身就是 Agent 的状态管理层。
传统文件系统对 Agent 有几个致命问题:
- 不可审计:Agent 改了哪些文件、改了什么内容、什么时间改的?
ls -la只能告诉你最后修改时间,不能告诉你修改历史。 - 不可回滚:Agent 把配置文件改坏了,除非你提前做了备份或者用了 Git,否则没法恢复。
- 不可隔离:两个 Agent 操作同一个目录,文件冲突是必然的。
AgentFS 的做法是:用 SQLite 数据库替代真实文件系统。Agent 的所有文件操作——创建、读取、修改、删除——都变成了数据库事务。
importagentfs # 创建隔离的 Agent 文件系统fs = agentfs.create("agent-coder-01") # Agent 写文件(实际写入 SQLite)fs.write("/src/main.py", "print('hello')") # 创建快照snapshot_id = fs.snapshot("before-refactor") # Agent 继续修改...fs.write("/src/main.py", "import os\nprint(os.getcwd())") # 出问题了?回滚到快照fs.restore(snapshot_id)# /src/main.py 恢复为 "print('hello')"Copy-on-Write 是核心机制。Agent 修改文件时,原始文件不动,只在 SQLite 里记录一条差异。这意味着:
- 零成本快照:快照只是标记一个时间点,不需要复制文件
- 精确回滚:可以回滚到任意快照点,不是"全部撤销"
- 完整审计:每一步操作都有记录,可以用 SQL 查询 Agent 的行为历史
-- 查询 Agent 在过去一小时修改了哪些文件SELECTpath, operation, timestampFROMagent_operationsWHEREagent_id='agent-coder-01'ANDtimestamp>datetime('now', '-1 hour')ORDERBYtimestampDESC;AgentFS 还支持 FUSE 挂载——把 SQLite 虚拟文件系统挂载到真实路径上,Agent 用标准的文件操作(open/read/write)就能工作,不需要改代码。对 Agent 来说,它操作的就是一个普通的文件系统,但背后所有操作都被记录和隔离。
这个设计的深层意义是:它让 Agent 的行为变得可重放。你可以拿到一个 Agent 的操作日志,在另一个环境里精确重放每一步,看它到底做了什么、为什么做错了。这对调试 Agent 行为至关重要——你不能让 Agent "解释"它为什么删了那个文件,但你可以回放它的操作序列,自己判断。
对照表:人类工具 vs Agent 工具的设计差异
把上面六个范式放在一起看,一个清晰的模式浮现出来:
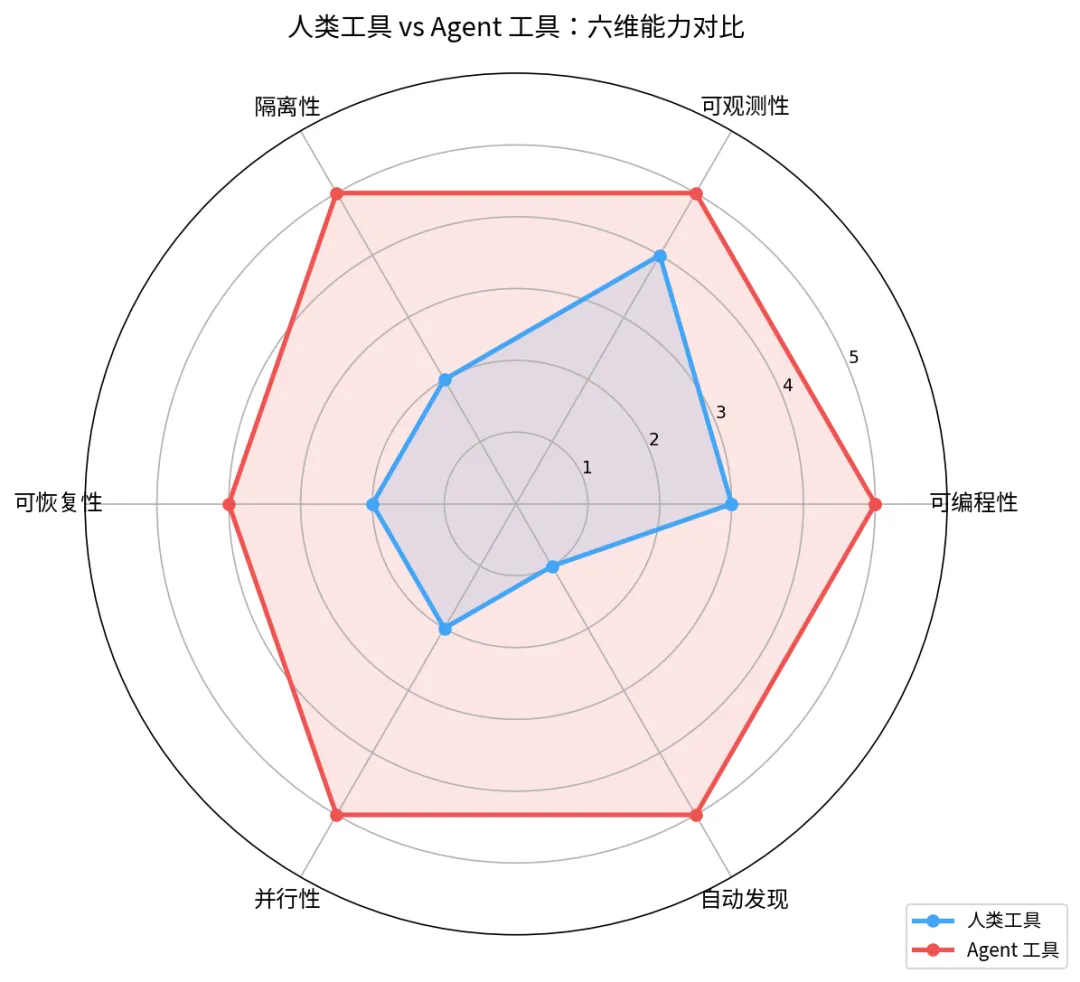
雷达图:六角形对比,蓝色线条为人类工具在可编程性 3 分、可观测性 4 分、隔离性 2 分、可恢复性 2 分、并行性 2 分、自动发现 1 分,红色线条为 Agent 工具在六个维度均为 4-5 分,Agent 工具面积显著大于人类工具
| 维度 | 人类工具的设计假设 | Agent 工具的设计假设 |
|---|---|---|
| 感知方式 | 视觉(GUI、语法高亮、图标) | 文本(stdout、屏幕内容、结构化数据) |
| 操作方式 | 手动(鼠标点击、键盘快捷键) | 程序化(API 调用、send-keys、JSON-RPC) |
| 并行能力 | 单线程(一次做一件事) | 多线程(同时操作多个隔离环境) |
| 错误恢复 | 撤销/重做(Ctrl+Z) | 快照/回滚(文件系统级) |
| 工具发现 | 读文档、搜索、问同事 | 运行时自动发现(MCP tools/list) |
| 环境隔离 | 不需要(只有一个人在操作) | 必须(多 Agent 并行操作同一仓库) |
| 状态管理 | 依赖记忆和笔记 | 结构化状态文件 + 数据库审计 |
| 事件响应 | 主动检查(拉取模式) | 自动触发(推送模式,inotify/Hook) |
这不是说人类工具"落后"了。它们为人类的认知方式优化了几十年,非常好用。但 Agent 的认知方式不同——它不需要"看",它需要"读";它不需要"记",它需要"查";它不需要"一步步来",它需要"同时铺开"。
工具为使用者而设计。使用者变了,工具自然要变。
结语:工具链正在分叉
我们正处在一个有趣的分叉点。
过去 40 年,开发工具的演进方向是"让人类更高效"——从命令行到 GUI,从文本编辑器到 IDE,从手动部署到 CI/CD。每一步都在适应人类的认知习惯:视觉化、交互式、单线程。
现在,一条新的演进路径出现了:"让 Agent 更高效"。tmux 的 capture-pane 比 GUI 截图更适合 Agent 感知。Git worktree 比分支切换更适合 Agent 并行。MCP 比 REST API 文档更适合 Agent 发现工具。AgentFS 比真实文件系统更适合 Agent 管理状态。
这两条路径不会合并。人类不会放弃 VS Code 去用 tmux capture-pane 写代码,Agent 也不会去学怎么点击 GUI 按钮。它们会各自演进,偶尔交汇——比如 Kiro 这样的产品,同时为人类提供 IDE 体验,为 Agent 提供 Hook 和 MCP 接口。
值得关注的趋势:
- tmux 生态爆发:dmux、workmux、NTM、amux、cmuxLayer、Webmux……半年内出现了至少六个 Agent 编排工具,全部基于 tmux。这不是巧合。
- 沙箱成为标配:E2B、Modal、Daytona 等平台的增长说明,"让 Agent 在隔离环境里跑"正在从可选变成必选。
- MCP 协议扩散:2300+ Server、200+ 客户端支持,MCP 正在成为 Agent 工具集成的事实标准。
- 文件系统被重新发明:AgentFS 的 copy-on-write + SQL 审计模式,可能是 Agent 状态管理的未来方向。
下次你看到一个新的开发工具,不妨先问一个问题:这个工具是为人设计的,还是为 Agent 设计的?
答案可能会越来越频繁地指向后者。
参考链接:
- tmux is the multi-agent AI orchestration layer you already have[1] — Robert Travis Pierce 关于 tmux 作为 Agent 编排层的深度分析
- tmux as Agent Habitat[2] — iKangAI 对 tmux capture-pane/send-keys 双原语的技术解析
- Orchestrating a local LLM swarm using tmux and Claude[3] — Rohan Verma 的本地 LLM 集群编排实践
- dmux: A dev agent multiplexer[4] — 支持 11+ Agent 的开源 worktree + tmux 编排工具
- Git worktrees for parallel AI coding agents[5] — Upsun 开发者中心的 worktree 并行实践指南
- The Complete Guide to Sandboxing Autonomous Agents[6] — Agent 沙箱技术的全面综述
- AgentFS: The Missing Abstraction for AI Agents[7] — Turso 团队对 Agent 文件系统抽象的设计思路
- Introducing the Model Context Protocol[8] — Anthropic 官方 MCP 协议介绍
- Webmux: a web dashboard for parallel AI coding agents[9] — Windmill 的多 Agent Web 仪表盘方案
- NTM Review 2026 – Multi-Agent Tmux Orchestrator[10] — NTM 工具的功能评测
参考链接
[1] https://roberttravispierce.com/articles/tmux-multi-agent-ai-orchestration
[2] https://www.ikangai.com/tmux-as-agent-habitat/
[3] https://rohanverma.net/blog/2025/11/19/orchestrating-local-llm-swarm-tmux-claude/
[4] https://github.com/standardagents/dmux
[5] https://devcenter.upsun.com/posts/git-worktrees-for-parallel-ai-coding-agents/
[6] https://www.ikangai.com/the-complete-guide-to-sandboxing-autonomous-agents-tools-frameworks-and-safety-essentials/
[7] https://turso.tech/blog/agentfs
[8] https://www.anthropic.com/news/model-context-protocol
[9] https://www.windmill.dev/blog/webmux
[10] https://vibecoding.app/blog/ntm-review
