夜雨聆风
夜雨聆风链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
https://www.mizhushare.com/docs/
按地区拆分:为每个省份或城市生成独立的数据文件,便于分区域汇报; 按年份拆分:将长周期数据按年度切割,生成历年数据文件; 按实验组别拆分:分组建立独立文件,以便单独建模或归档。
【统计分析软件SPSS】48、拆分文件
拆分文件:逻辑拆分。并非真正将数据文件分割成多个物理文件,而是在分析时按照分组变量对数据进行分层处理。所有数据仍然保存在同一个文件中,只是在执行统计分析时,SPSS会自动按照指定的分组分别计算并输出结果。 拆分为文件:物理拆分。统会根据分组变量的不同取值,将原始数据实际写入磁盘,生成多个独立的 .sav 数据文件。

该数据为不同车型的销售数据,本次将使用表示车辆类型的「type」变量作为分组变量,将数据拆分为Automobile和Truck两个单独的数据文件。
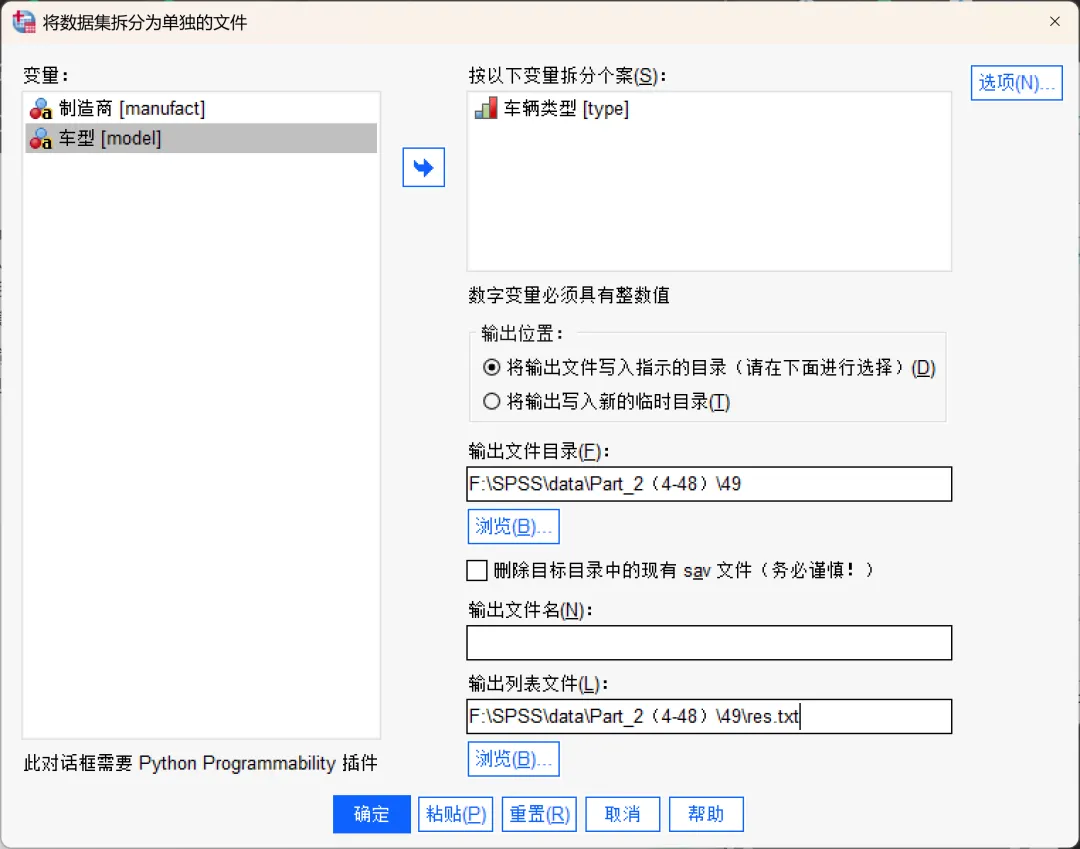
点击顶部菜单栏的【数据→拆分为文件】,在打开的对话框中进行相应设置。
主对话框:
变量:当前数据集中所有可用变量。
按以下变量拆分个案:指定拆分依据的变量。可以指定一个或多个变量。
输出位置:用于设置拆分后文件保存的位置。其中,「将输出文件写入指示的目录」表示将拆分后的文件保存到指定文件夹;「将输出写入新的临时目录」表示SPSS将自动创建一个临时文件夹保存拆分后的文件,关闭SPSS后临时目录会被删除。
输出文件目录:指定拆分后所有新 .sav 文件的保存路径。
删除目标目录中的现有sav文件:勾选后,SPSS在执行拆分前,会先清空目标文件夹内所有的 .sav 文件。
输出文件名:用于设置拆分后生成的数据文件的命名方式。默认情况下,SPSS会按照将所有拆分变量的值或值标签组合在一起,不同变量之间使用下划线「_」分隔的规则自动生成文件名。也可以自定义命名方式,例如,使用固定文件名(必须与目录模式结合使用,否则所有拆分后的数据都会写入同一个文件,从而导致原有数据被覆盖)、文件命名模式(Pattern),按照变量值自动生成不同文件名。
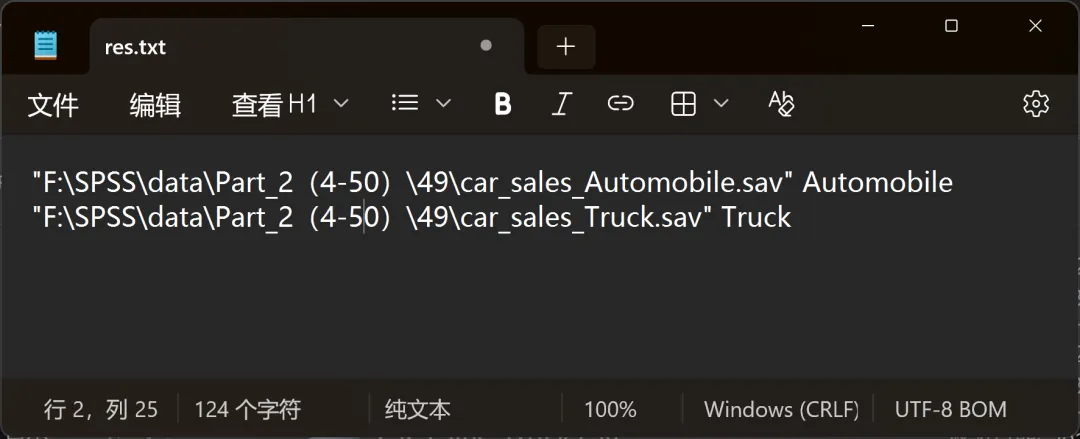
输出列表文件:该选项用于生成一个记录文件,用于列出本次拆分操作创建的所有 .sav 数据文件。
选项对话框:
输出文件名:系统提供三种策略来自动生成拆分后的文件名。
①、基于拆分变量的值:直接使用拆分变量的原始数据值作为文件名的主体。
②、基于拆分变量的值标签:使用拆分变量定义的值标签作为文件名主体。
③、按顺序编号:按照拆分组的顺序,从0001开始依次递增编号。
名称前缀:勾选该选项后,下方的文本框中输入的自定义文本将作为前缀,添加到每个生成文件名的开头,前缀文本与后续的文件名主体(由上述三种方式生成)之间会自动添加下划线「_」分隔。
显示写入的文件的列表:选中该选项后,将在查看器中生成一个列表,其中包含写入的文件以及相关联的拆分变量值
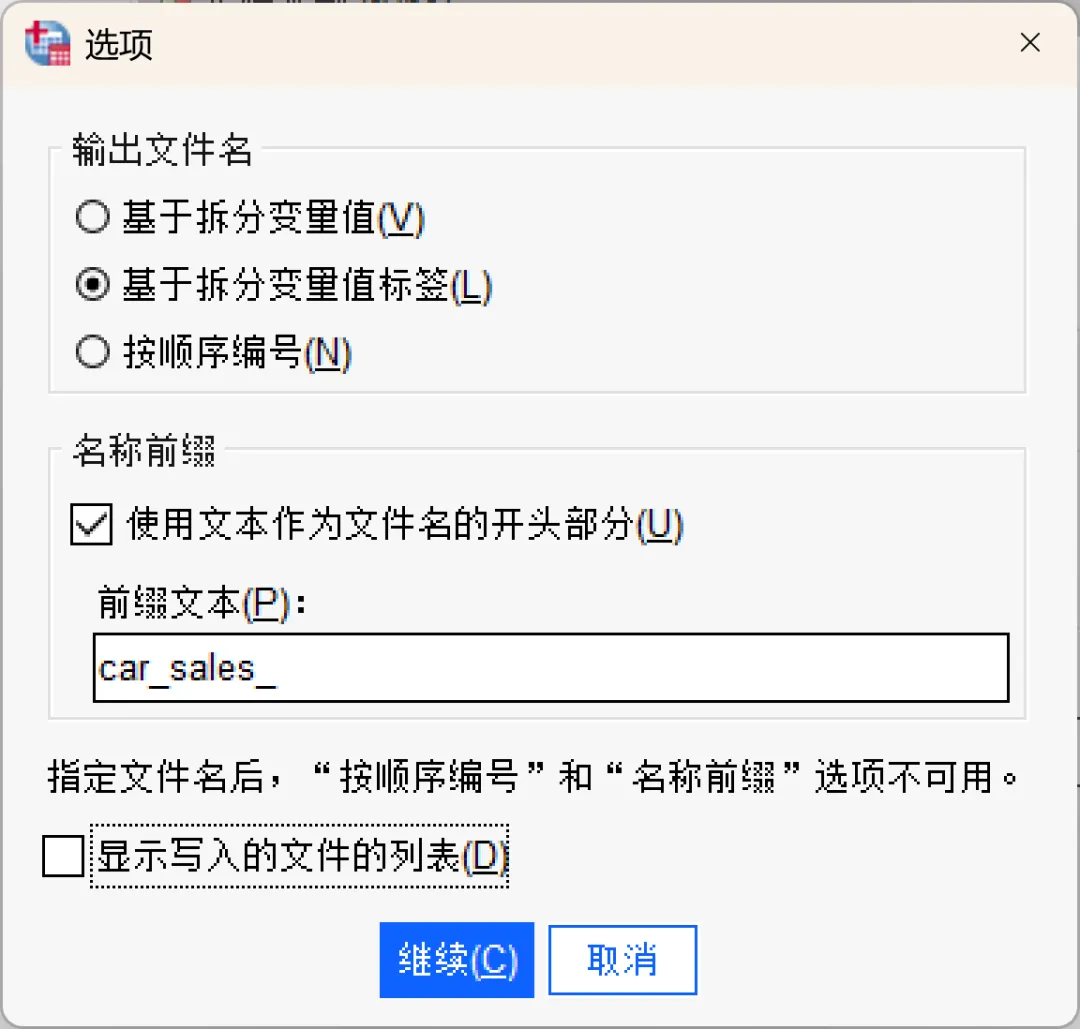
设置完成,点击确定,SPSS将依据「type」变量的值标签,自动生成2个独立的数据文件,并同步创建名为「res.txt」的输出列表文件以记录本次拆分操作创建的所有数据文件。