 夜雨聆风
夜雨聆风透视AI:全面解构重构世界的数字生命体 算力:"骨与肉" 计算模块:GPU/ASIC,CPU 数据模块:SRAM、HBM、DDR5、eSSD、HDD 传输模块:服务器,交换机,光模块,电模块,互联芯片 支援模块:封装、组装、测试电源、散热
整合模块:服务器、IDC、云服务 算法:"灵与智" 数据:"血与经" 能源:"光与气"
PART 01
PART 02
易失性存储(Volatile,俗称"内存"):以DRAM(动态随机存取存储器)为代表。它使用极其微小的电容来存储电荷。好比一个"漏水的杯子",充放电极快,因此速度能达到纳秒级(ns)。但致命的弱点是,为了防止数据消失,系统必须每秒钟成千上万次地给它重新充电(刷新)。一旦断电,"杯子"里的水瞬间漏光,数据灰飞烟灭——它注定只能作为计算时的临时工作台。
非易失性存储(Non-volatile,俗称"硬盘"):以NAND Flash(闪存)为代表。它通过量子隧穿效应,将电子硬生生"轰"进一个绝缘的微观笼子(浮栅或电荷捕获层)里。电子被死死关住,哪怕断电十年也不会丢失,实现了永久记忆。但代价是,把电子轰进去和抽出来的过程极其暴力且缓慢(微秒至毫秒级延迟),并且每一次擦写都会对绝缘层造成不可逆的物理磨损(寿命受限)——它注定只能作为长期保存数据的仓库。
PART 03

越靠近计算核心,速度越快,密度越低,价格越贵,容量越小; 越远离计算核心,速度越慢,密度越高,价格越便宜,容量越大。
PART 04
PART 05
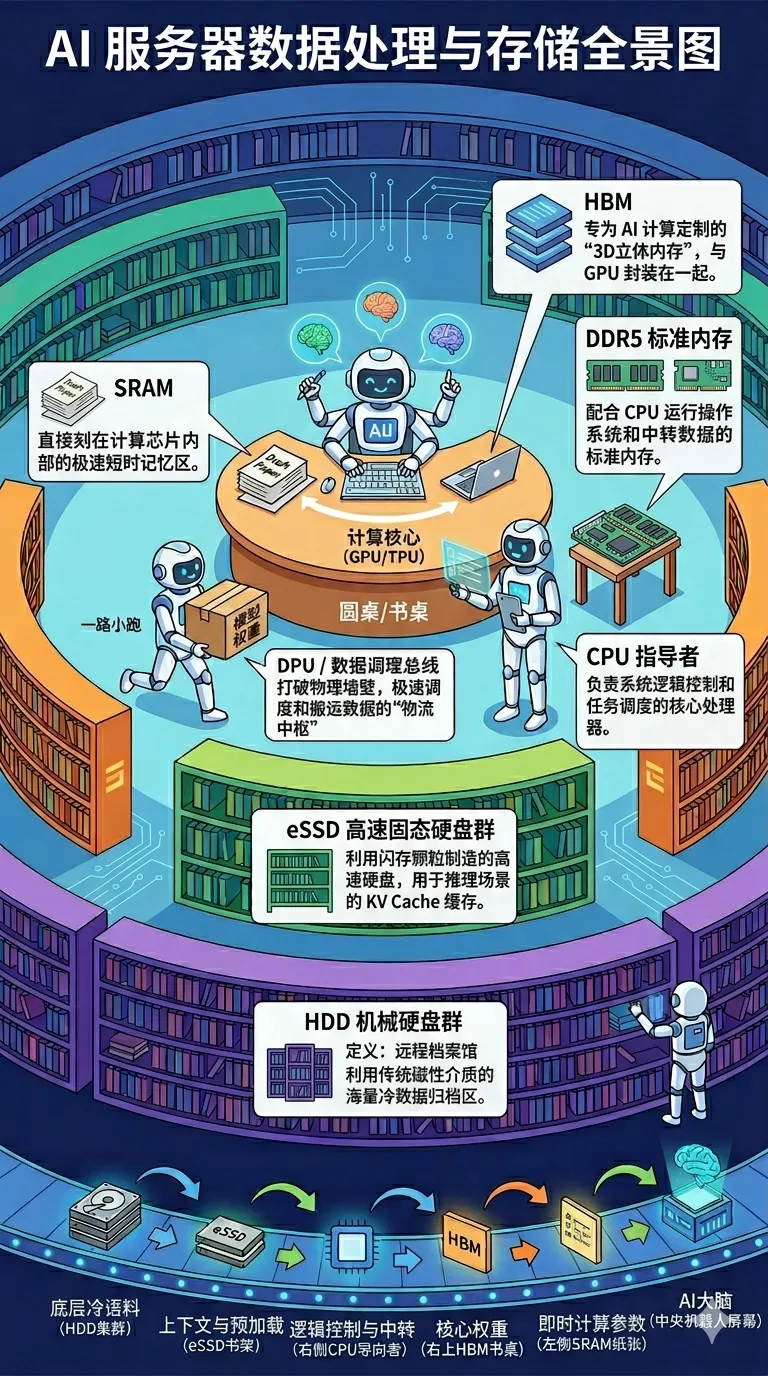
速度:响应延迟低于1纳秒;在H100 GPU中,L1缓存片内聚合读写带宽约119 TB/s,L2缓存对外聚合带宽约33 TB/s(远快于HBM的3.35 TB/s)。 密度:台积电N2(2nm GAA)节点已将SRAM单元面积压缩至约0.0175 μm²,面密度约38 Mb/mm²;英特尔18A约31.8 Mb/mm²,落后台积电N2约20%。 容量:H100 GPU的L2缓存仅有50 MB——与HBM的80 GB相比,小了约1,600倍。 价格:极度高昂,由于直接内嵌于芯片,其成本反映在GPU整颗芯片的售价中,无法单独购买。 玩家:SRAM是一个"无法独立存在"的市场——它被直接打包进GPU/CPU的硅片中,因此这个赛道的门票,就是晶圆代工的顶级制程。台积电(TSMC,2330.TW)、三星代工(005930.KS)是全球唯二能量产最先进节点的晶圆厂。要进入这个赛道,你不需要开发SRAM,而是需要掌握整个先进制程,这意味着: 数百亿美元的建厂资本开支:台积电每年资本开支超400亿美元,一座先进制程晶圆厂造价约200亿美元以上; 数十年的工艺Know-how积累:GAA晶体管、SRAM微缩、EUV光刻三件套,缺一不可; EUV光刻机的物理封锁:ASML(ASML.US)每年仅能生产约60台极紫外光刻机(EUV),而全球对顶级制程的需求远超于此。
速度:H100集成6个HBM3E堆栈,合计3.35 TB/s内存带宽;HBM4最高可达2 TB/s/堆栈,多栈叠加后整卡带宽将突破8 TB/s以上。 密度:HBM的单Die面密度约0.16 Gb/mm²(SK海力士HBM3数据),远低于DDR5(~0.3–0.4 Gb/mm²)——这是TSV通孔占据了大量芯片面积的代价。但通过8–12层Die的3D垂直堆叠,单个封装体的有效容量可达80–192 GB,弥补了单Die密度的不足。 容量:H200 GPU单卡搭载141 GB HBM3E,B200为192 GB HBM3E,HBM4时代单卡容量将突破200 GB。 价格:极度高昂(业界戏称"HBM税")。每GB成本约100–200美元,是DDR5的约30–60倍。
SK海力士(000660.KS):赢者通吃的"黑马王者"。以约53%–62%的市场份额稳坐霸主之位,首度超越三星成为全球DRAM营收第一。英伟达消耗了SK海力士约90%的HBM产量。其HBM4产品传输速率已达10 GT/s,预计继续成为英伟达Rubin平台的首要供应商。
三星(005930.KS):失守的巨人,与艰难的王者归来。HBM3E时代因良率问题跌至约17%(Q2 2025),至Q3回升至约35%。在HBM4赛道,三星举集团之力全力反扑;其12层HBM3E模块提供高达1,280 GB/s带宽和36 GB容量,已于2025年底向主要客户发运HBM4样品,实现11 Gbps引脚速率。预计HBM4量产后份额有望回升至30%以上。
美光(MU.US):押注AI的黑马转型者。2025年底宣布全面退出消费级内存与存储市场,将全部产能押注AI数据中心。HBM市场份额约11%–21%(不同季度数据)。已向客户发运速率高达11 Gbps的HBM4样品,并与台积电合作开发HBM4E。
第一道门槛:顶级DRAM基础能力。HBM的本质是多层DRAM Die的垂直堆叠,因此必须首先是一家世界级DRAM制造商,这本身就已经将绝大多数公司拒之门外——全球能够量产先进DRAM的公司,历史上从来不超过十家,现在仅剩三家。 第二道门槛:TSV(硅通孔)打孔工艺。这是HBM区别于普通DRAM的核心制造工艺——在厚度仅有几十微米的DRAM晶圆上,精准地刻蚀出数以千计、直径仅有几微米的垂直通孔,并填充金属互联。这项工艺的良率控制,是让大多数厂商望而生畏的物理难题。据悉,三星在HBM3E时代的部分批次良率问题,正是TSV环节的缺陷导致的。 第三道门槛:高精度键合(Bonding)工艺。将多层Die精准地叠放在一起,并用非导电薄膜(NCF)或热压键合(TCB)完成互联,整个过程的位置精度要求在亚微米级别。这需要极其专用的封装设备和专有的工艺配方,是长期Know-how积累的产物。 第四道门槛:极其漫长的客户认证周期。即便你真的做出了HBM,英伟达的供应商认证流程以严格著称——三星的HBM3E在2024年就"做出来了",但直到2025年中才通过英伟达认证并开始出货。认证壁垒,本身就是一道时间意义上的护城河。
速度:响应延迟约40–60纳秒,单条DDR5-6400带宽约51–96 GB/s;一台配置8根DDR5的AI服务器,系统总内存带宽可达约400–800 GB/s(远低于HBM,但够用)。 密度:约0.3–0.4 Gb/mm²(以美光D1β工艺为例,约0.435 Gb/mm²),是HBM单Die密度的2–3倍(HBM密度低是因为TSV占用了大量面积)。 容量:单台AI服务器系统内存通常为1–4 TB,价格适中,是整体服务器BOM中相对"白菜"的一环。
极端的资本密集度:DRAM制程每代更新都需要数百亿美元的新设备投入,而价格战周期往往在"下行"时让小玩家直接亏光家底。历史上,日本DRAM产业(NEC、日立、富士通等)就是在1990年代的价格战中被打垮、整合的;德国的奇梦达(Qimonda)在2009年直接破产。
制程节点的持续竞赛:DRAM节点不断收缩,每一代都需要下注EUV设备,稍有落后则成本竞争力全面崩溃。这是一场没有终点的军备竞赛,只有最强的资产负债表才能撑到最后。
软件+系统生态的锁定:DRAM的标准由JEDEC制定,但头部厂商的优化参数(XMP超频配置、时序调校)已与英特尔、AMD的平台深度绑定,形成了事实上的生态粘性。
速度:响应延迟约50–200微秒,读取带宽约7–14 GB/s(企业级NVMe PCIe 5.0单盘),SSD阵列可达100+ GB/s的聚合带宽。 密度(NAND颗粒层面):3D NAND通过垂直堆叠(现已达200+层)大幅提升等效密度。以QLC(四层单元)为例,等效平面密度可高达4–8 Gb/mm²(优于DRAM),并且仍在随层数提升而不断增长;SLC(单层单元)速度更快但密度低约75%。 容量:单盘1 TB至61.44 TB(铠侠CD9P Series),价格约为每GB0.10–0.30美元。 AI对eSSD的核心需求主要包括:KV Cache存储(超长上下文推理的中间状态缓存)、模型检查点(Checkpoint)保存、以及HBM与HDD之间的热数据缓冲层。
| 闪迪(SanDisk,SNDK.US) | ~19亿美元 | 12.4% |
2025年2月(上市初):SNDK开盘价约28–38美元,市值约55亿美元。彼时,整个市场对这家"被拆出来的NAND资产"的估值,还停留在商品半导体的周期性框架里——低谷期,悲观预期。
2025年Q3–Q4:AI对eSSD的结构性需求爆发,NAND价格开始急速攀升;闪迪的数据中心营收占比从约6%快速攀升至约12%,Pure-play NAND的故事开始被资本重新定价。
2025年10月:股价突破130美元,市值约197亿美元,较上市初涨约215%。
2026年4月(撰稿时):股价约919美元,市值约1,260亿–1,360亿美元,52周最高触及965美元。自上市至今约14个月,股价涨幅约32倍;年初至今(2026年YTD)涨幅约300%。
3D堆叠技术的迭代需要极度专用化的生产设备:3D NAND的核心工艺是将存储单元垂直堆叠(现主流为200层以上),需要深宽比极高的刻蚀工艺(HAR Etch),以及极其精密的薄膜沉积(ALD)设备。这些设备高度定制化,价格极其昂贵,且只有少数设备商(如泛林集团Lam Research、应用材料Applied Materials)能够供应,形成了设备层面的天然准入壁垒。
向下一代迭代的成本巨大:从200层到300层,再到1,000层(铠侠2031年目标),每一次层数的跃升都意味着新工艺的全面突破——堆高会带来电荷干扰加剧、制造良率下降、读写速度降低(需新型架构如CMOS-bonded-array来补偿)。这条路,没有百亿美元量级的研发预算,根本走不下去。
生态绑定:各大NAND原厂的SSD控制器芯片(或与Silicon Motion、Phison等合作伙伴深度定制的固件),以及配套的AI纠错预测算法,已与数据中心的具体工作负载深度绑定,形成了事实上的切换成本。
速度:响应延迟约3–10毫秒(极慢),带宽约200–500 MB/s(低),但这是HDD唯一被允许慢的原因——它从来不需要"快",它只需要"多"和"便宜"。 密度(磁道层面):以希捷Mozaic 4+ HAMR技术为例,磁道密度约1–2 Tb/in²(太比特/平方英寸),并且仍在持续提升。但与半导体类密度的概念不同,HDD密度的提升靠的是更精密的磁头写入和激光热辅助,技术路径完全不同于芯片行业。 容量:单盘容量已达30–44 TB,集群可扩展至数十PB以上。 价格优势:每GB成本约0.015–0.030美元,与企业SSD(约0.10–0.30美元)相比,仍高出约10–15倍的性价比优势。当数据量以EB(百亿亿字节)为单位增长时,这个差距是无法被忽视的现实。
32 TB及以上规格HDD的交货周期,从数周暴涨至52周以上(超过整整一年)
希捷(STX.US)CEO宣布:"我们2026年全年的近线产能已全部售罄,预计2027年上半年才能重新接受新订单。"
西部数据(WDC.US)CEO证实,公司2026年全年产能已全部锁定,主要采购方是其排名前七的超大规模云厂商,长期协议已签至2027–2028年
HDD均价在2025年Q2已创下自1998年以来的历史最高水平,部分规格价格在半年内上涨约46%–50%
磁头与盘片的技术壁垒极高:现代HDD磁头的读写间距只有几纳米,盘片表面平整度要求在埃(Å,0.1纳米)级别。制造这样的器件,需要长达数十年在材料学、精密加工、机械工程上的专有积累。这是与半导体制程截然不同的一套技术体系,新进者几乎无处下手。
极致规模经济的护城河:HDD的利润极度依赖规模,固定成本分摊是关键。当三家巨头已各自建立了每年亿级规模的量产体系,新进者的单位成本将高得无法参与竞争——这是一个典型的"规模者通吃"的市场。
供应链的深度纵向整合:希捷、西数、东芝对磁头(Read/Write Head)、盘片(Media)、伺服电机(Spindle Motor)的关键组件,大多选择内部自研生产,而非外购。这种纵向整合产生了极难被外部供应链颠覆的护城河。
PART 06
SRAM,是卡死在制程之上的"芯片内政",没有EUV的中国,在这一环节只能以时间换空间,差距短期内难以弥合,但国产芯片设计企业仍可在架构层做有效的优化补偿。
HBM,是本轮AI内存革命中确定性最强的超级赛道,SK海力士是无可争议的最大赢家,三星正在强势反扑,美光是押注最决绝的黑马。长鑫存储的HBM3突围,是中国AI自主算力体系"从无到有"的战略性一步,其A股IPO与后续的产能爬坡,将是未来两年值得高度关注的重要事件。
DDR5,是最稳健的周期性红利,长鑫存储在这一赛道的进展已足以令国际同行警惕。
eSSD,正在经历一场历史级别的结构性行情。而2025年最戏剧性的故事,属于从西部数据分拆独立上市的闪迪(SNDK)——从28美元涨至920美元,14个月32倍,这不只是一个股价的故事,更是整个AI存储时代被资本重新定价的宣告书。长江存储的技术实力被长期低估——尽管枷锁犹在,那把达摩克利斯之剑的锋芒,从未消散。
HDD,是所有人意想不到的"硬通货",希捷与西部数据的卖方市场,或许还将延续至2027年。在这里,中国的参与主要体现在系统集成层,而非原器件制造层。
