夜雨聆风
夜雨聆风AI 大时代,autoresearch 助力科研
张量产品官 | 原创
有段时间,我对"AI 自主研究"这个方向的态度是:看,但不信。
不是因为它不酷,而是因为这类项目太容易停留在演示层面:看起来像在研究,实际上既不能稳定复现,也很难公平比较。
你很难分清,它到底是在做研究,还是在表演做研究。
直到我认真跑了一遍最近社区讨论比较多的一个自动化研究开源项目,我才意识到:我以前误解的,不是结果,而是它成立的前提。
先说我看到了什么
这个项目是一位知名研究者今年春天开源的,发布四十多天,社区关注度非常高。
我不想用"火了"来形容。开源社区里无聊的东西也会火。我觉得这个数字说明的是:大量工程师看到它之后,心里响起了同一个声音:
"终于有人做出了一个不是在表演的版本。"
我重现了这个实验
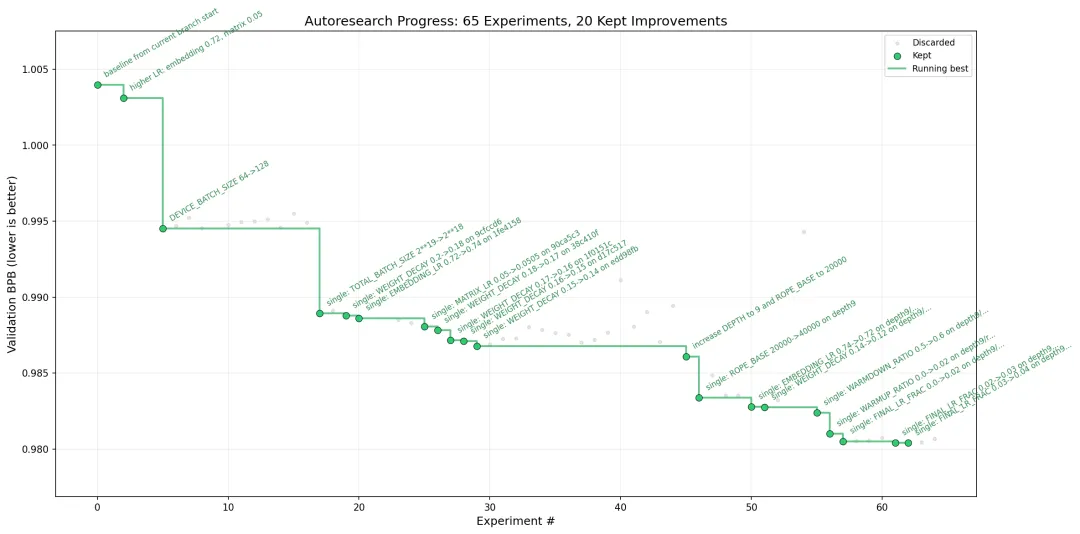
这轮自动研究的最终成果如下:
val_bpb | 1.003983 |
val_bpb | 0.980406 |
| 约 2.35% |
听起来很小,对吧?先别急着下结论。
研究成本有多低?
这是最关键的:
65 次实验 × 5 分钟 ≈ 5.42 H100-hours
换句话说,只用了五个多小时的单卡算力,就跑完了一整轮 65 次实验的自动搜索。
我当时看到这个数字的第一反应,不是兴奋,而是停下来想了半分钟:
这件事的价值到底在哪里?
大多数人关注了错误的地方
很多人看到这个项目的第一反应是:
"哦,loss 又低了一点,然后呢?"
这个问题本身没错。错的是,用这个问题来评判这个项目。 相当于看着一座新建的工厂说:"它今天生产了多少个零件?才这么点?"
你关注的是产出,它交付的是产能。
这个项目真正给出的,不是某一次实验的结果,而是:
一个可以持续运转的研究闭环。
简单到"不可能是真的"的闭环
这个闭环极其简单,简单到我第一眼觉得它"太玩具了,不可能是真的":
1. 读规则( program.md)2. 改训练代码( train.py)3. 跑一次固定 5 分钟的实验 4. 看指标有没有变好 5. 变好就保留,变差就回退 6. 继续下一轮
就这六步,死循环。
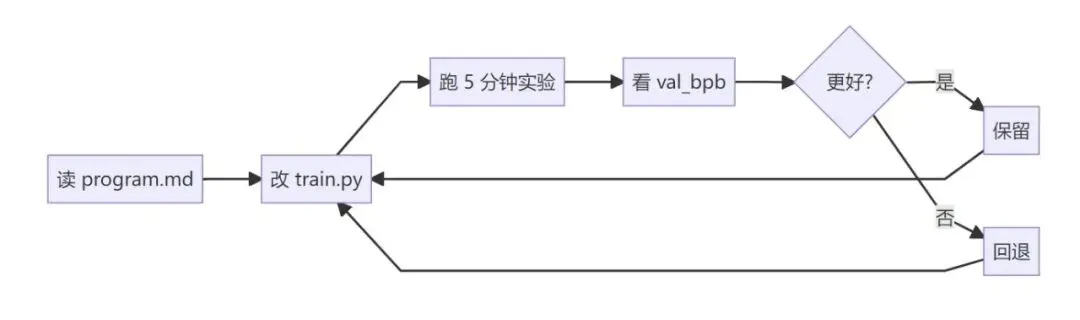
但我越看,越觉得:
简单,才是它真正成立的原因。
有一句话我一直很认同:复杂是功能的坟场。
一个系统越复杂,维持它运转所需要的人的注意力就越多,也越难持续。
这个项目把这件事压到了最小:每一步有明确的输入输出,每一步能自动判断成功还是失败,整条链路不需要人在里面守着。
它不会因为一个工程师请假而停下来。
这才是关键。
它的四个克制,让我改变了判断
我认真想了一下,为什么这个项目能运转起来,而不是像很多"自主 AI"实验一样,最终陷入幻觉循环。
答案是:
它在每一个设计决策上,都比直觉更克制。
① 只让 AI 改一个文件:train.py
研究空间仍然足够大:改优化器、改学习率调度、改模型架构、改数据处理方式,全都可以,组合是无限的。
但 AI 的操作范围被锁死在这一个文件里。
上下文不会爆炸,出了问题有地方追,回退也精准。
② 每次实验固定 5 分钟
这个设计最漂亮的地方在于:它强制让所有想法在同一个"预算"里竞争。
你想到一个改法,它必须在 5 分钟内见效,不然就是没用的想法。
没有"跑一晚上看看",没有"也许跑久了会更好"。
同一把尺子,量所有改动。比较就变得公平。
③ 只盯一个核心指标:val_bpb
这是我认为最容易被忽视的决定。
多目标优化在自动化系统里是个陷阱。质量更好了但推理变慢了,留不留?某个 benchmark 提高了但方差更大了,留不留?
这些问题让人来判断可以开个会,但让系统来判断就是噪音:系统不会"权衡",它只会乱。
所以主循环里只有一个裁判,其他指标顶多做参考。
这是产品取舍,不是技术偷懒。 这两件事之间,差别很大。
④ 人不再参与每轮实验,而是负责设计规则
这一步是我认为最容易被忽视的转变。
人不再是实验员,而是"规则设计师"。
人主要写 program.md,定义这个"AI 研究流程"应该怎么运转;系统负责把规则变成持续实验。
人的注意力从"每次改什么",升级到了**"怎么设计一个好的研究规则"**。
这四件事合在一起,才让我觉得它不是一个"自动脚本",而更像是:
一个研究操作系统的雏形。
雏形,意味着它还很粗糙,很多能力没有;但也意味着,它有一个可以延伸的骨架。
BPB 到底是什么,为什么它适合做唯一裁判
我知道很多读者一看到 val_bpb 就想跳过。但我还是得解释一下。
因为,不理解这个指标,你就很难看懂整个系统为什么这样设计。
BPB 是什么?
BPB,全称 bits per byte。大白话来说:
模型读文本时,还会不会频繁"吃惊"。
想象你在背一篇文章。背得越熟,你对下一个词的预期就越准确,"惊讶感"就越低。
BPB 测的,就是这个"惊讶成本"。
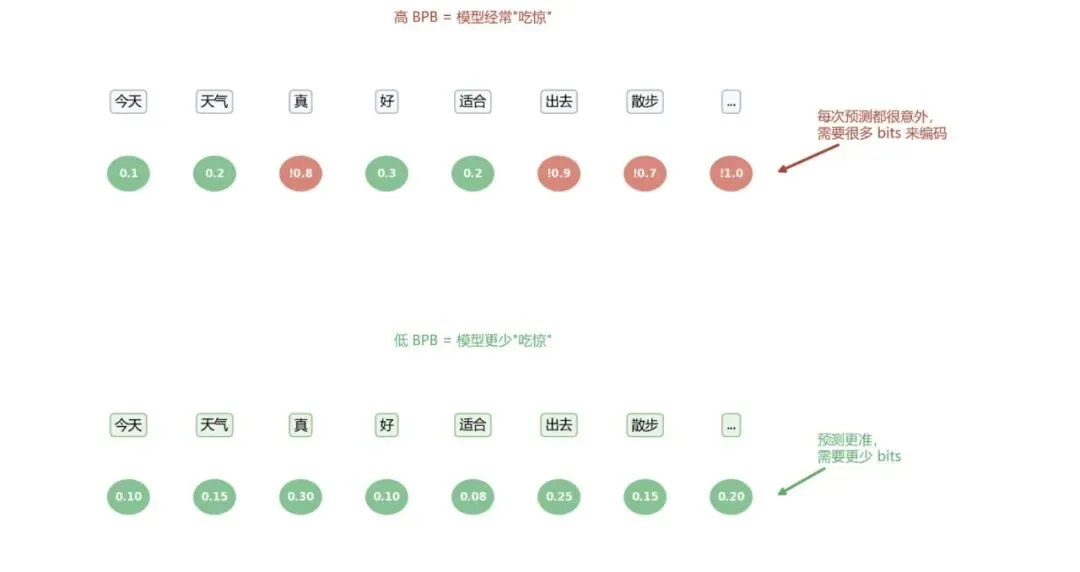
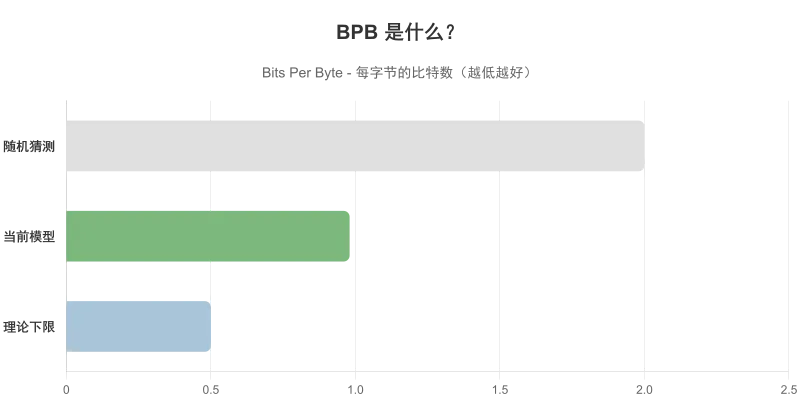
更准确地说:
BPB 更低 = 模型对这种语言的分布掌握得更好,更少感到意外。BPB 更高 = 模型还是经常猜错,基础掌控力还不够稳。
它跟压缩是完全一套逻辑:
你越能准确预测接下来会出现什么,你编码它所需要的信息量就越少,文件就能压得越小,BPB 就越低。
重要的是:BPB 不是在测模型会不会"推理",它测的是模型对语言本身有没有更扎实的内部掌控。
为什么 BPB 适合做主裁判?
在"5 分钟、自动循环、持续试错"这个产品设计里,它同时满足了五个条件:
| 反馈快 | |
| 反馈密 | |
| 可稳定比较 | |
| 和基本能力强相关 | |
| 便于自动决策 |
我的结论是:
在这套产品设计里,BPB 是最适合担当唯一主裁判的指标。
这是产品取舍,不是学术信仰。这两件事之间,差别很大。
然后我把这个思路用到了我正在做的项目里
我正在做一个面向专业文档审阅场景的 AI 助手。
一说这个方向,很多人的第一反应是:
"哦,就是帮忙读读长文档呗。"
不是这样的。 我想做的,比这难得多。
为什么这类场景特别难?
面对长篇、结构复杂、充满嵌套条件和交叉引用的专业文档,有一个特征是很多 AI 场景不具备的:
它对准确性和可追溯性的要求非常高。
你不只是要"看起来答对",你要产出一份经得起反复核对的结论。
审阅的真实过程大概是这样的:
你拿到一份长文档,其中的规则可能有歧义,某些条款之间可能相互影响,某些细节可能存在缺漏。你要把每一个需要判断的点和相关条款逐项比对,给出结论,写明理由,标注证据在第几页第几段,最后生成一份可供他人复核的报告。
这份报告的每一个结论都会被人反复查看,任何一个错误都会被放大。
在这种场景里,模型能力每提升一点,我最先关心的是这几件事:
而 BPB 这个指标,在我看来,是这些结果的上游信号。
模型对语言的基础掌控力越强,它在处理充满歧义和嵌套逻辑的条款时,犯基础性错误的概率就越低。
两件事之间,有一条可以追溯的传导链路。
这件事真正难的,不是技术
说到这里,我想说一件经常被忽视的事:
这件事真正难的部分,不是 AI 能不能改代码、调参数。
这些,现在的大模型已经能做了。
真正难的,是你能不能为你的场景,设计出一个合适的闭环。
设计闭环意味着什么?
意味着你要找到一个指标,它能在你的预算窗口里稳定反馈,还不能太容易被"刷",还要和你真正关心的最终结果有传导关系。
意味着你要设计一套规则,让 AI 知道它能碰什么、不能碰什么、用什么来判断成功。
意味着你要能识别出,哪些改动是真实有效的,哪些只是在你的测试集上过拟合。
这个项目能在语言模型研究这个领域跑通,是因为作者把这些都想清楚了:5 分钟、单文件、val_bpb、自动保留或回退。
每一个决定背后都有权衡。
换到我自己的场景,我面临的问题是:
我的"val_bpb"是什么?
BPB 在语言模型研究里是"模型对语言的掌控力"。但专业文档审阅不一样:我不关心模型"吃不吃惊",我关心的是模型能否像有经验的审阅者一样,给出准确、有据、可复核的结论。
这两个是不同的问题。一个是"语言理解",一个是"任务执行"。
所以,我选择的指标是:结论准确率。
具体来说:我准备 50 ~ 100 个真实样本,每个都有人工标注过的标准答案("这一条应该判定为 X,理由是……")。然后每次模型改动后,让它对这些样本作答,看有多少比例与标准答案一致。
为什么准确率比 BPB 更适合?
1. 直接衡量任务能力:审阅的核心就是"根据规则给出准确的判断和理由",准确率直接测这个。 2. 快速反馈:50 ~ 100 条样本,几分钟跑完,就能知道这一轮改动有没有帮助。 3. 防止过拟合:每条样本既要判断、又要理由、还要证据位置,光靠"背题"是混不过去的。 4. 和最终结果有传导链:准确率高 → 报告与人工审阅一致性高 → 返工率低 → 真正的价值。
这就是我的"val_bpb"。
自动研究能力有一个复利结构
我最后说一件很重要但很少被提的事:
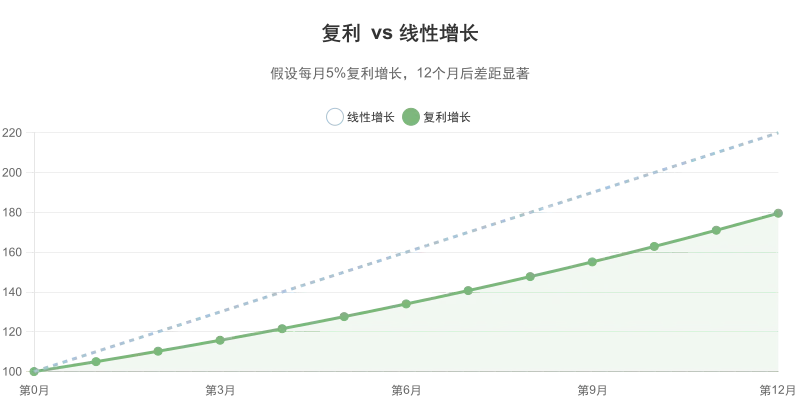
这类能力的价值,会随着时间变大,不是保持不变。
每一轮实验留下的有效改动,会成为下一轮的基础。有效改动越多,模型越强,下一轮实验能探索的方向越好。
这不是线性增长,而是复利。
这意味着:
• 越早建立这套闭环,积累的有效改动越多,积累的优势越大; • 越晚进入,想追上来的成本越高。
这不像买算力:算力这东西,买晚了顶多贵一点。
自动研究能力的复利结构更像代码库里的架构质量:越晚开始认真做,后面填坑的成本越不成比例。
过去,模型研究是手工作坊的模式:人提出猜想 → 改代码 → 跑实验 → 看日志 → 记结果 → 再想下一步。这个流程并不神秘,但高度依赖人的注意力,人一疲惫,研究就停了。
自动研究把这件事变成了一条可以后台持续运转的流水线。
人的角色从"每次亲自上手",变成了"设计规则,让系统自己跑"。
这是一个质变,不是量变。
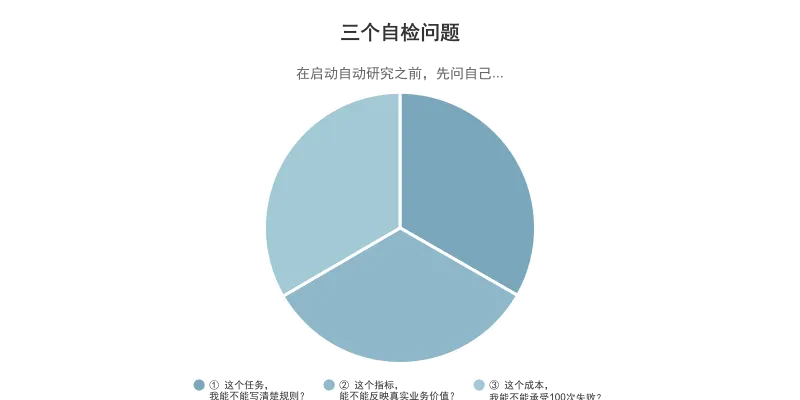
给做 AI 应用的人的三个自检问题
如果你也在做某个垂直场景的 AI 产品,特别是那种需要持续提升模型在复杂任务上的能力的产品,我觉得有三个问题值得认真想一下。
问题 ①:你的场景里,有没有一个"val_bpb"?
不是五个指标,不是一个 dashboard,而是那一个——能在合理时间窗口里稳定反馈、能自动判断好坏、和你真正关心的最终结果有传导关系的那一个。 如果没有,你的模型改善工作就很可能是漫无方向的碰运气。
问题 ②:你的改善流程,是手工作坊还是闭环?
如果每次模型改善都依赖某个人突然想到一个点子,然后推动一次专项实验,这件事的上限就是那个人的时间和注意力。 这不是在批评人,而是在说:这种模式不可持续,也没有复利。
问题 ③:你有没有办法把技术指标翻译成最终价值?
这是最难的一步。它不是一个纯技术问题,也不是一个纯产品问题,它需要你同时理解技术传导机制和价值链条。 大多数"AI 产品"在向团队解释清楚"我们为什么要继续投入"时,讲不清楚这一步。
这轮实验给我的最大收获,不是某个具体的训练技巧,而是:
它给了我一个把"持续改善"做成产品能力的完整思路。
最后一句
这个项目不是终点。它是一个最小可行版本,一个雏形,很多能力还没有。
但它做成了一件其他很多同类项目没有做成的事:
让"AI 自主推进研究"这件事,第一次有了一个真实可运转、可测量、可复现的产品形态。
它不是在训练一个更大的模型,而是在把"AI 如何推进自身研究"这件事,变成了一个可以持续运行的产品流程。
这比"loss 又低了一点"大得多。