 夜雨聆风
夜雨聆风Transformer 架构
上一期我们讲到,
2017 年那篇 Attention Is All You Need,
最重要的,不只是提出了“注意力”这个想法。
更重要的是,
它把这套想法真正搭成了一整套能跑起来的机器。
这套机器,就是:
Transformer。
如果说上一期我们讲的是一种“脑回路”,
那这一期要讲的,就是:
这套脑回路,最后是怎么变成一台工业级机器的。
为什么这个问题值得讲?
因为今天很多主流 AI 产品背后,
你都能看到 Transformer 的影子。
ChatGPT 也好,
翻译模型也好,
文生图、语音、视频里的很多系统也好,
它们虽然长得不一样,
但很多骨架,都是从这里长出来的。
所以今天这篇,我们想回答的问题是:
Transformer 到底厉害在哪,为什么它后来成了 AI 世界的“通用底盘”?
先别急着想架构图,先想一个翻译团队
如果你要翻译一句外语,
最笨的办法是什么?
大概是一个字一个字往后挪。
看到第一个词,想一下。
看到第二个词,再想一下。
一直拖到最后,
再勉强把整句意思拼出来。
这就是以前很多序列模型的味道:
能做,
但吃力,
而且慢。
Transformer 的思路更像什么?
更像一个特别高效的翻译团队。
这个团队里,
有人负责先把原文整体看懂。
有人负责一边参考前面的输出,一边组织下一句该怎么说。
还有几个人,
会同时从不同角度盯重点:
谁和谁有关 这句话重点落在哪 这个词更像在指前面的哪个东西
也就是说,
Transformer 不是只多了一个新零件。
它更像是把“怎么理解一句话”这件事,
重新组织了一遍。
翻译团队比喻图
这套机器最外面,其实还是熟悉的“编码器-解码器”
很多人第一次看 Transformer 架构图,会被里面的箭头和模块吓到。
但如果先把最外层骨架拎出来,
它其实没有那么难。
最经典的 Transformer,可以先粗略分成两部分:
- 编码器(Encoder)
- 解码器(Decoder)
你可以先把编码器理解成:
负责把原文真正看明白的人。
比如一句英文进来:
它不会急着立刻翻中文。
它先要搞清楚:
这句话在说什么 哪些词彼此相关 这段信息的重点在哪里
而解码器则更像:
负责把理解过的内容,一点点组织成输出的人。
如果编码器像“读懂题目”,
那解码器就像“开始写答案”。
所以 Transformer 虽然内部很新,
但最外层这件事,
依然很符合直觉:
先理解输入,再生成输出。
编码器解码器分工图
编码器到底在干嘛?本质上是在做“高质量理解”
编码器不是简单把句子读一遍。
它干的事情更像是:
把一句话里的每个词,都变成一个更聪明的表示。
比如词还是那个词,
但它不再只是字典里的孤立词条。
它会带上上下文。
“bank” 这个词,
在“river bank”里和在“bank account”里,
编码器最后得到的内部表示,就不该一样。
为什么能做到?
因为上一期讲过的 Self-Attention,
会让每个词在理解自己时,
都去参考句子里其他相关的词。
于是编码器做出来的东西,
不再是“单词本身”,
而更像:
放进上下文之后,这个词在这里真正意味着什么。
这一步非常关键。
因为后面不管是翻译、总结、问答,
你都得先把输入理解得足够像样,
后面的输出才有可能靠谱。
那解码器呢?它像一个一边看资料、一边往下写的人
如果编码器负责“看懂”,
那解码器负责的就是“往下说”。
但它不是乱说。
它得同时看两边:
一边看编码器已经理解好的输入内容,
一边看自己前面已经写出了什么。
这有点像你在做翻译时的状态。
你手边放着原文。
你已经写出了前半句中文。
接下来写下一句时,
你既不能脱离原文,
也不能忘了自己前面刚写过什么。
所以解码器本质上像一个边写边回看的系统:
回看输入,确保没跑题 回看已输出内容,确保语气和逻辑接得上
这也是为什么,它不像“吐字机”。
它更像一个在不断参考上下文的写作者。
可如果全靠注意力,AI 怎么知道顺序?
这里有一个很容易忽略、但特别关键的问题。
Attention 很会抓重点。
可它有一个天然短板:
它本身并不自带顺序感。
什么意思?
如果你把一句话里的词全都摊开,
光靠“谁和谁相关”,
模型不一定知道谁在前,谁在后。
但语言里,顺序往往非常重要。
“狗咬人”和“人咬狗”,
词差不多,
顺序一变,意思就翻了。
所以 Transformer 里还得补一件事:
告诉模型位置。
这就是所谓的:
位置编码(Positional Encoding)。
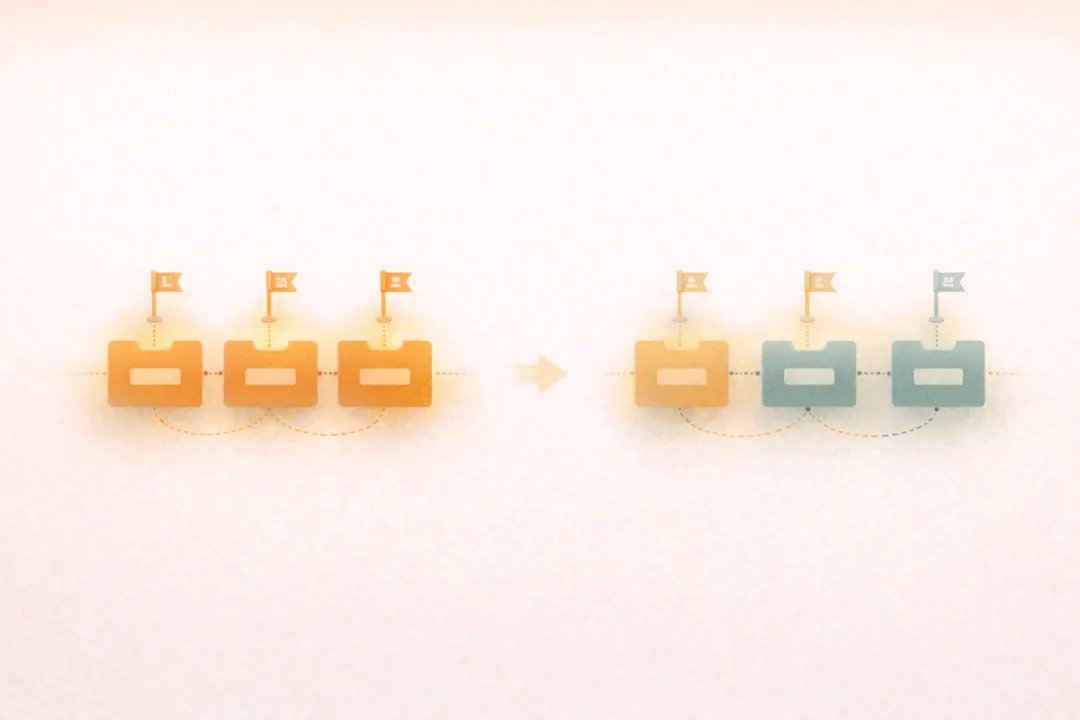
位置编码示意图
你可以把它理解成给每个词发一个“座位号”。
这样模型在看全局关系时,
才不至于把整句话看成一堆无序的词块。
它不仅知道“谁和谁有关”,
还知道:
谁先出现,谁后出现。
这一步看起来像小修补。
其实非常关键。
因为它等于是把“顺序”这件事重新塞回了一个靠全局注意力运作的系统里。
多头注意力,听起来很玄,其实像“几个人同时从不同角度读同一句话”
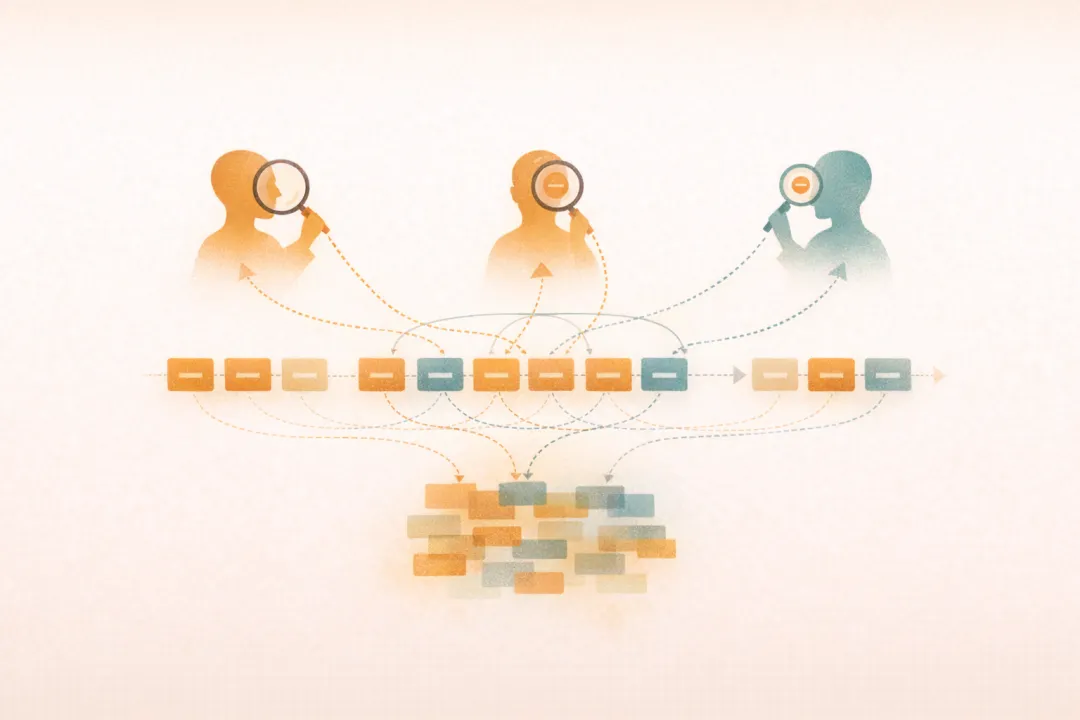
接下来是 Transformer 里另一个很有名的词:
多头注意力(Multi-Head Attention)。
第一次听这个词,
很多人会有点懵。
其实你可以先把它理解成一个很生活化的画面:
不是一个人盯着一句话看。
而是几个人同时从不同角度看同一句话。
多头注意力示意图
比如有人更关注:
主语和动词的关系 代词到底指谁 哪些词在语义上更接近 哪些部分是整句重点
如果只有一个注意力头,
它可能会把很多关系都挤在一起看。
而多头注意力的好处,就是:
让模型可以并行地看多种关系。
你可以把它想成一支配合很好的分析团队。
每个人都盯不同角度。
最后再把这些观察拼起来,
形成更完整的理解。
这就是为什么 Transformer 不只是“会看重点”。
它是:
能从多个角度同时看重点。
所以 Transformer 真正厉害的地方,不是一个模块,而是整套配合
讲到这里,你会发现,
Transformer 的厉害,
并不只来自某一个孤立零件。
不是说:
“哦,它里面有注意力,所以赢了。”
更准确地说,是这几件事第一次被组合得特别顺:
用编码器先把输入理解清楚 用解码器一边参考输入一边组织输出 用位置编码把顺序感补回来 用多头注意力从多个角度同时抓关系
这些东西拼在一起,
模型就同时拥有了几种以前很难兼得的能力:
看得全 抓得准 跑得快 更容易并行训练
这就是为什么,Transformer 常常会被看成一种“平台级发明”。
它不是只解一道题。
它像是把很多 AI 任务都能复用的一套工程骨架,
一下子搭出来了。
为什么很多人会把它叫作 AI 界的“工业革命”?
因为在它之前,
很多模型更像手工作坊。
某一类任务,
配一套专门的模型思路。
图片有图片那套。
文本有文本那套。
长序列还有长序列那套补丁。
而 Transformer 带来的变化是:
大家突然发现,原来有一套更通用的底层架构,可以大规模复用。
这很像工业革命带来的变化。
不是某一台机器变强了。
而是整套生产方式被改写了。
一旦底盘足够强,
后面很多产品形态都会跟着爆发。
所以从 Transformer 往后看,
你会看到一连串熟悉的名字:
BERT、GPT、T5、各种多模态模型……
它们彼此不完全一样。
但很多都是在 Transformer 这块底盘上继续改、继续放大、继续训练。
这就是它真正可怕的地方。
它不只是自己成功。
它还特别适合被继承。
如果今天只记一句话,我希望你记住这个
如果说 Attention 教会了 AI “该看哪里”,
那 Transformer 做的,就是把这种能力真正组织成了一整套高效、可扩展、能大规模训练的系统。
所以它厉害,不只是因为聪明。
更因为:
它聪明得足够工程化。
这也是为什么,
今天这么多 AI 产品虽然表面长得不一样,
但往里拆,常常还能拆到 Transformer 的影子。
不过,故事讲到这里,
还差一个自然的问题。
Transformer 这台机器有了。
那接下来,人们是怎么把它喂大、喂强,
最后一路喂到 GPT 和大语言模型那一步的?
下一篇,我们就来讲:
如果你把整个互联网的文字都喂给一个 AI,会发生什么。
也就是 GPT 那套“暴力美学”的故事。
