夜雨聆风
夜雨聆风
上一篇我们把问题压回到了最基础的层面:
单智能体 串行 并行
那一篇解决的是一个很重要的问题:
工作流到底该怎么走。
但当系统继续往前做,你很快会发现,光有“流程结构”还不够。
因为复杂系统真正难的,往往不是先走哪一步。
而是:
谁负责判断下一步 谁负责复查结果 谁应该被当成独立能力复用
这时,你会反复遇到 3 种更进阶的设计模式:
Loop Coordinator Agent as Tool
它们不是上一篇的替代品。
更准确地说,它们是建立在上一篇之上的一层“控制结构”。
上一篇讲的是路径。
这一篇讲的是调度、纠错和能力封装。
先记住一个判断:进阶模式解决的不是“能不能做”,而是“怎么更稳地做”
很多团队第一次接触高级 Agent 设计模式时,很容易误以为:
“终于可以开始做真正的多智能体系统了。”
这句话听起来很对。
但从工程角度看,它其实很危险。
因为这些模式真正解决的,并不是“把系统做得更炫”。
它们解决的是三个很具体的问题:
第一轮结果不够稳定,怎么让系统自己复查 任务本身不固定,怎么让系统动态拆分和调度 某些能力已经成熟,怎么把它们稳定复用,而不是重新塞进一个大 Agent
也就是说,进阶模式的价值,不在“复杂”。
而在让复杂性有组织。
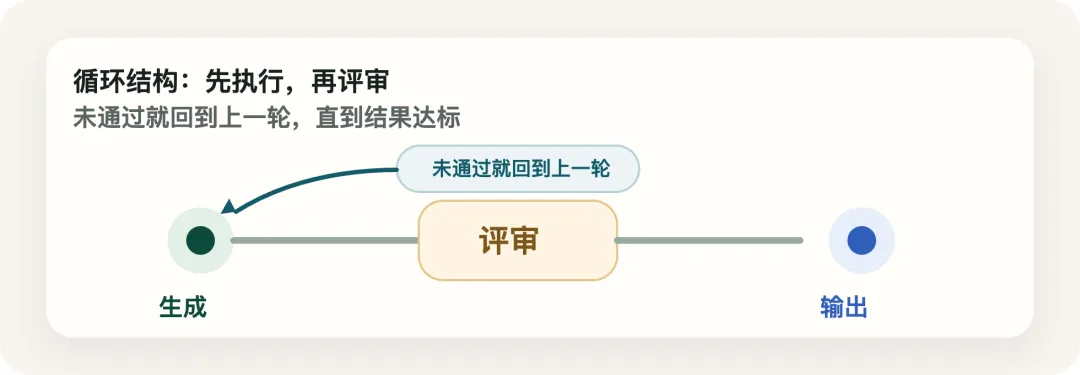
一、Loop:当第一轮结果不够可靠时,让系统自己回头看一眼
Loop 模式最直观的理解,就是:
先做一版,再评一版,不满意就改。
它适合的,不是所有任务。
它特别适合这种场景:
结果质量很重要 第一轮输出经常不够稳 错误不是出在信息缺失,而是出在表达、推理或细节 你愿意多花一点时间,换更高的正确率
比如:
写一份对外方案,先生成,再自检有没有逻辑漏洞 做一段代码,先写,再检查边界条件和异常路径 生成一份分析报告,先出草稿,再看结论和证据是否一致
它的核心不是“多跑一遍”。
而是让系统显式地把“执行”和“评审”分开。
一旦这两个动作分开,很多之前混在一起的问题就会清楚很多:
是不会做 还是做完不会检查 是缺信息 还是缺反馈回路
Loop 最大的优点,是它往往能在不改业务流程的前提下,直接提升输出质量。
但它也有非常现实的代价:
延迟会变高 成本会增加 如果评价标准不清楚,系统会来回打转 如果“批评者”本身判断不稳定,Loop 只会放大混乱
所以,Loop 模式真正有效的前提是:
你得先知道“什么叫好结果”。
如果连评价标准都说不清,只靠让系统反复修改,通常不会越改越好,只会越改越散。
一句话总结:
Loop 适合解决“质量不稳”的问题,不适合掩盖“目标不清”的问题。
二、Coordinator:当任务路径不固定时,需要一个统一的调度者
上一篇讲串行和并行时,有一个默认前提:
流程大致是清楚的。
你知道哪些步骤要发生。
你也知道它们之间的依赖关系。
但现实里有一类任务,不满足这个前提。
它们的问题不是“步骤太多”。
而是“步骤不固定”。
比如一个复杂研究任务。
有时需要:
先搜索资料 再抽取观点 再补缺失证据 最后生成结论
但也有时会变成:
先拆问题 对其中一部分做数据分析 对另一部分做案例研究 发现信息不够,再回去补搜
这时,如果还强行用固定串行链路,系统会很别扭。
因为真正困难的部分已经不是“谁执行”。
而是“谁决定接下来该让谁执行”。
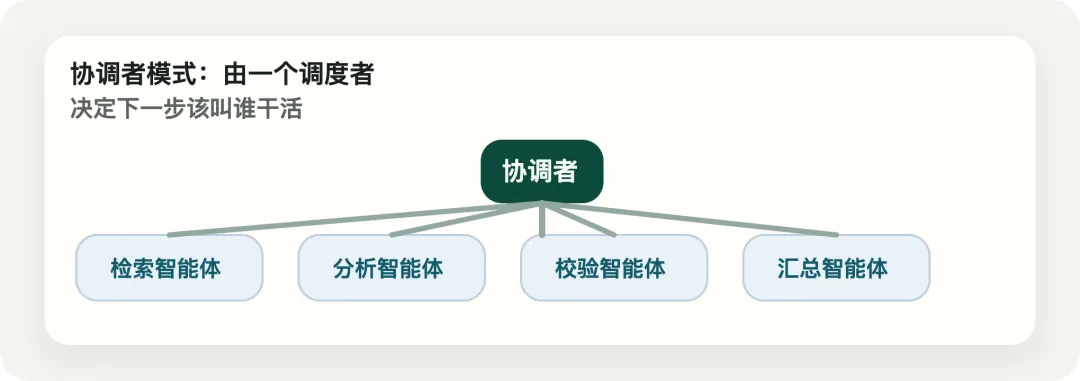
这就是 Coordinator 模式的价值。
它的核心是引入一个中心调度者。
这个调度者不一定亲自做所有事。
它的职责更像:
看当前任务状态 判断还缺什么 选择下一步应该调用哪个子 Agent 在必要时汇总不同 Agent 的输出
Coordinator 最大的好处,是系统开始具备一种“动态组织能力”。
它不再只能跑固定脚本。
而是可以根据任务状态,决定下一步该怎么走。
这对复杂、开放式、多阶段任务非常重要。
但它的代价也很明显:
系统控制逻辑会明显变复杂 中心调度者会变成新的瓶颈 如果 Coordinator 判断不准,整个系统都会被带偏 你需要更清楚地定义每个子 Agent 的边界,否则调度会越来越混乱
很多团队做到这一步时,问题往往不是“没有足够多的 Agent”。
而是:
没有一个足够稳定的调度层。
所以,Coordinator 模式不是“多一个 Agent”那么简单。
它本质上是在系统里引入一个新的控制面。
一句话总结:
当问题的难点变成“怎么动态选择下一步”时,Coordinator 才值得出现。
三、Agent as Tool:把成熟能力封装起来,而不是继续往总控 Agent 身上堆
很多团队做到一定阶段后,会出现一个很典型的问题:
系统里已经有一些能力是稳定的。
比如:
搜索型 Agent SQL 分析 Agent 代码执行 Agent 总结归纳 Agent
这些能力已经有比较稳定的输入输出。
也有自己的上下文和约束。
这时候最差的做法,就是把它们重新塞回一个超级大 Agent 的提示词里。
因为那样做,系统很快会重新回到上一篇讲过的老问题:
职责越来越杂 提示越来越长 边界越来越糊 调试越来越难
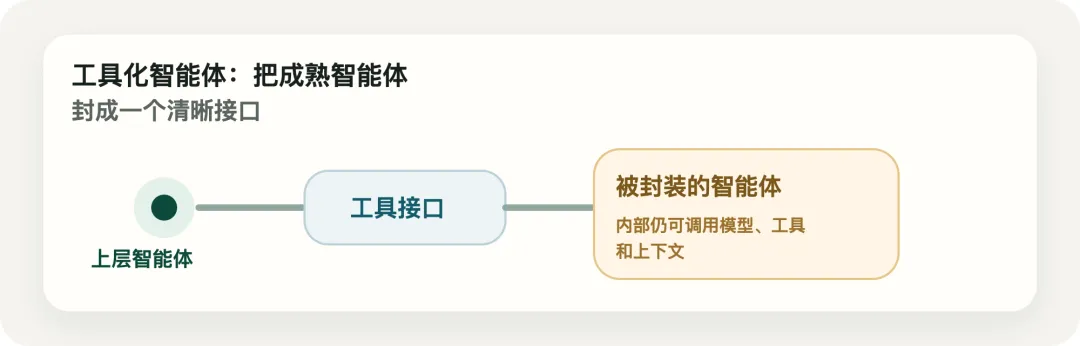
更好的方法,是把这些成熟能力当成“工具”来调用。
也就是:
Agent 不一定总是协作者,它也可以是一个被调用的能力单元。
这就是 Agent as Tool。
它的意思不是“把普通函数换个名字”。
它真正的价值在于:
这个能力本身可能仍然很复杂 它内部可能还会调用模型、工具和上下文 但对上层来说,它暴露的是一个清晰接口
上层不必知道它内部怎么工作。
只需要知道:
什么时候该调用它 输入是什么 输出是什么 失败时怎么处理
这会带来一个非常重要的好处:
系统复杂度开始被“封装”起来,而不是被“扩散”出去。
成熟能力一旦被封成工具,就更容易:
复用 替换 测试 独立优化
但这类模式同样有前提。
不是所有 Agent 都适合被工具化。
如果一个能力的输入输出始终不稳定,边界也不清楚,那它更像一个实验阶段的 Agent,还不适合被封装成工具。
Agent as Tool 最适合的,是那些:
职责已经比较清楚 能力可以重复复用 接口可以被定义清楚
的模块。
一句话总结:
Agent as Tool 解决的是“怎么复用成熟能力”,不是“怎么把所有能力都往工具列表里塞”。
这 3 种模式,和上一篇是什么关系
如果把上一篇和这一篇放在一起看,你会更容易理解它们各自解决什么问题。
上一篇那 3 种模式:
单智能体 串行 并行
更像是在回答:
工作流拓扑该怎么设计。
而今天这 3 种模式:
Loop Coordinator Agent as Tool
更像是在回答:
系统如何纠错、调度和复用能力。
你可以把它们粗略理解成两个维度:
拓扑维度:任务怎么流动 控制维度:任务怎么被评审、调度和封装
所以在真实系统里,它们往往不是二选一关系,而是组合关系。
比如:
一个单智能体里加 Loop,提升质量稳定性 一个串行流程里加入 Coordinator,处理动态分支 一个并行系统里,把某个成熟子 Agent 封成 Tool
真正成熟的 Agent 系统,通常不是靠“更多角色”堆出来的。
而是靠这些结构被清楚地组织起来。
怎么选?给你一个更接近实战的判断顺序
如果你正在做第二阶段的 Agent 系统,可以先按这个顺序判断:
先问自己,现有问题到底出在哪里是结果质量不稳,还是流程路径不固定,还是成熟能力无法复用。
如果问题是结果质量不稳,优先考虑 Loop它最适合解决“第一轮做得出,但做得不够好”的问题。
如果问题是路径不固定,优先考虑 Coordinator它最适合解决“下一步该由谁做”这个问题。
如果问题是能力已经成熟,但系统越来越乱,优先考虑 Agent as Tool它最适合解决“怎么把复杂能力变成清晰接口”。
最后再问一句这个复杂度,真的值得引入吗?
这句话仍然很重要。
因为并不是每个系统都必须长成“高级 Agent 架构”。
很多系统做到最后,真正高效的部分,依然是:
少量清晰的 Agent 稳定的输入输出 有边界的控制逻辑
而不是一个什么都想做的超级编排器。
最后收一句
上一篇我们讲的是:
不要一上来就多智能体。
今天这篇其实是在把这句话再往前推进一步:
当你真的需要更复杂的系统时,也不要一上来就把复杂度摊平。
先问清楚,你缺的到底是什么:
是复查能力 是调度能力 还是复用能力
缺什么,就补什么。
而不是默认“高级系统”一定长得更复杂。
真正好的 Agent 设计,不是组件越多越强。
而是每一层复杂度,都有明确的理由。