 夜雨聆风
夜雨聆风▴ 欢迎关注 AGI4US,获取更多智能体方法论、案例与产品更新

图刚传上去,链接还没发给客户,页面底下先冒出一句话:“可能由AI生成”。
你盯着屏幕,心里先冒出两个念头。
一个是:平台是不是误判了?
另一个更扎心:如果它真看出来了,那我手里这张图、这段视频、这条音频,到底还算不算“我的东西”?
很多人以为,问题在平台太敏感。
问题不在这里。
问题在于,平台今天给你贴这张标签,背后已经不是单一的图像识别,而是一整套正在成形的内容安检系统:元数据标识、数字水印、内容溯源、模型痕迹检测、用户声明、平台风控联动。
它不像一把锤子。
它更像机场安检。你以为它只扫行李,其实它同时看证件、看轨迹、看异常行为,还会抽检。
让平台敢贴“可能由AI生成”的,不是某个神奇算法,而是多线索叠加后的风险判断。

把这张图翻成大白话,其实就四步。
先读文件头,再扫内容痕迹,再看你有没有主动声明,最后才给出“已标识”“可能由AI生成”“疑似生成合成内容”这类分级提示。
所以,就算你现在不看图,也该记住一个判断:平台不是在猜你有没有用 AI,它是在判断自己该不该为这条内容承担额外风险。
你看到的是一句提示,平台看到的是一串痕迹
当一张图或一段视频被上传,平台通常不会只问一个问题:它是不是 AI 做的?
平台更关心的是:我能不能拿到足够多的证据,证明这东西存在生成合成的概率,或者至少值得提醒用户提高警惕。
这套判断链路,通常有几层。
有些痕迹藏在文件头里。
比如生成工具写进文件里的元数据、导出标记、内容来源字段、生产者信息、内容编号。国内监管把这类东西叫隐式标识。它不一定肉眼可见,但平台一旦读到,系统就很容易触发提示。
有些痕迹干脆摆在台面上。
比如图里角落残留的水印、视频首尾提示、音频开头的语音标识、交互界面上的“AI生成”声明。这类属于显式标识。
还有一类更隐蔽,也更容易误伤。
那就是模型生成时留下的统计痕迹:纹理分布不自然、压缩模式异常、局部边缘过度平滑、手部和文字区域的生成伪影、音视频时间一致性异常,甚至是某些模型家族在频域里留下的习惯性噪声。
这时候,平台未必能百分之百追到是哪一款模型,但已经足够把它归入“疑似”。
更关键的是,平台并不只看文件本身。
它还会看上传者有没有主动声明、内容是否在别的平台已被标识、是否带有前序传播平台写回的标识字段,甚至会结合账号历史行为做风控判断。
也就是说,你看到的是一行文案,平台跑的是一个组合拳。
这不是平台多事,是监管已经把路修到这里了
如果把时间拨回两三年前,很多平台对 AI 生成内容的态度还停留在“出了事再删”。
现在不一样了。
监管已经从“事后处置”,走向“生成即标识、传播再标识、平台要留痕”。

这张图该看的,不是版式,而是三条线正在并轨:
- 中国
:把“显式标识 + 隐式标识 + 平台补标”写进了规制逻辑。 - 欧盟
:把“机器可读、可检测、尽可能稳健可靠”写进了透明义务。 - 产业标准
:死磕另一件事——怎么让内容来源和修改链路,在跨平台流转时不至于一洗就没。
在中国,2025 年发布、2025 年 9 月 1 日施行的《人工智能生成合成内容标识办法》,把逻辑写得很直白。
生成服务提供者要加标识,传播平台也要核验标识。
如果文件元数据里已经明确写了它是生成合成内容,平台应当直接做显著提示。
如果元数据里没查到,但用户自己声明了,平台也要提示。
更狠的一条在后面:就算元数据没有、用户也没说,只要平台识别出显式标识或者其他生成合成痕迹,也可以把它识别为疑似生成内容,并加上“可能由AI生成”之类的提示。
这正是很多人上传后看到那行字的现实来源。
在欧盟,AI Act 第 50 条把要求压到“可检测、可机器读取”这一层。
提供生成音频、图像、视频、文本的 AI 系统,需要尽可能让输出带有机器可读且可检测的标记,并强调技术方案要有效、可互操作、稳健、可靠。
这意味着,监管已经不满足于“页面上写一句话”,而是要推动一种能跨平台流转、能被程序读取的内容来源基础设施。
而在产业标准层面,C2PA / Content Credentials 这条线,本质上是在做一件更长期的事:给媒体建立可验证的“出生证明”和“修改记录”。
Content Credentials 官网把这件事说得很直接:它要让好人有办法证明内容的来源、创作方式和编辑历史,而不是把所有判断都丢给事后检测器。
所以别把那句提示看成平台一时兴起。
它背后是监管、标准、平台治理和商业风控一起拧成的一根绳。
以前平台问的是“这条内容能不能发”。现在平台问的是“这条内容是谁做的、怎么做的、我该不该提醒别人”。
“AI指纹识别”到底在识别什么
“AI 指纹识别”这个词被说得很玄,好像平台有一台显微镜,扫一下就能追到是哪家模型、哪个账号、哪一分钟出的图。
现实没那么神。
但它也绝对不是玄学。

这张图如果只看一眼,很容易以为是“四选一”。
其实恰恰相反。
能落地的系统,往往是四层一起上:
- 显式水印
:肉眼能看见,监管友好,平台也好处理;但短板明显,裁剪、重构图、局部修补后就可能被干掉。 - 元数据与内容凭证
:可以写进文件头、容器信息或者签名清单里。C2PA 这类方案强调“谁在什么时候,对这个文件做过什么操作”,重点是可验证和可追溯。 - 鲁棒数字水印
:把标记嵌进像素、频域、音频频谱或视频时序结构里,尽量扛住压缩、转码、截图和轻度编辑;难点不在“埋进去”,而在“埋进去以后还不明显影响内容质量”。 - 模型痕迹检测
:不依赖创作者主动配合,也不要求原始文件自带签名,而是直接从内容统计特征判断“这像不像 AI 生成的”;这一层正在快速演进,但天生更像概率工具,不像铁案工具。
公开方案里,Google DeepMind 的 SynthID 是一个很典型的例子。
它做的不是“看完再猜”,而是在生成阶段就把额外信息埋进 token 分布、图像像素或者视频帧里。官方自己也说得很诚实:SynthID 不是银弹,它只是更可靠识别体系里的一块砖。
另一条线是 Meta 的 Stable Signature / Video Seal 这类鲁棒水印方案。思路也很直接:把看不见的标识嵌进图像或视频里,再尽量扛住转码、压缩和常见编辑动作。
这就解释了一个现实:
有标识,先认标识。 没标识,看有没有来源凭证。 凭证没了,再看内容层面的可疑痕迹。 用户自己声明了,再把声明写回传播链。
这更接近今天行业里“AI 指纹识别”的真实样子。
为什么这套技术,会突然和产权保护绑在一起
很多人听到“水印”“溯源”“指纹”,第一反应是监管更严了。
这话没错,但只说了一半。
另一半更值钱:它正在变成数字产权保护的新底座。
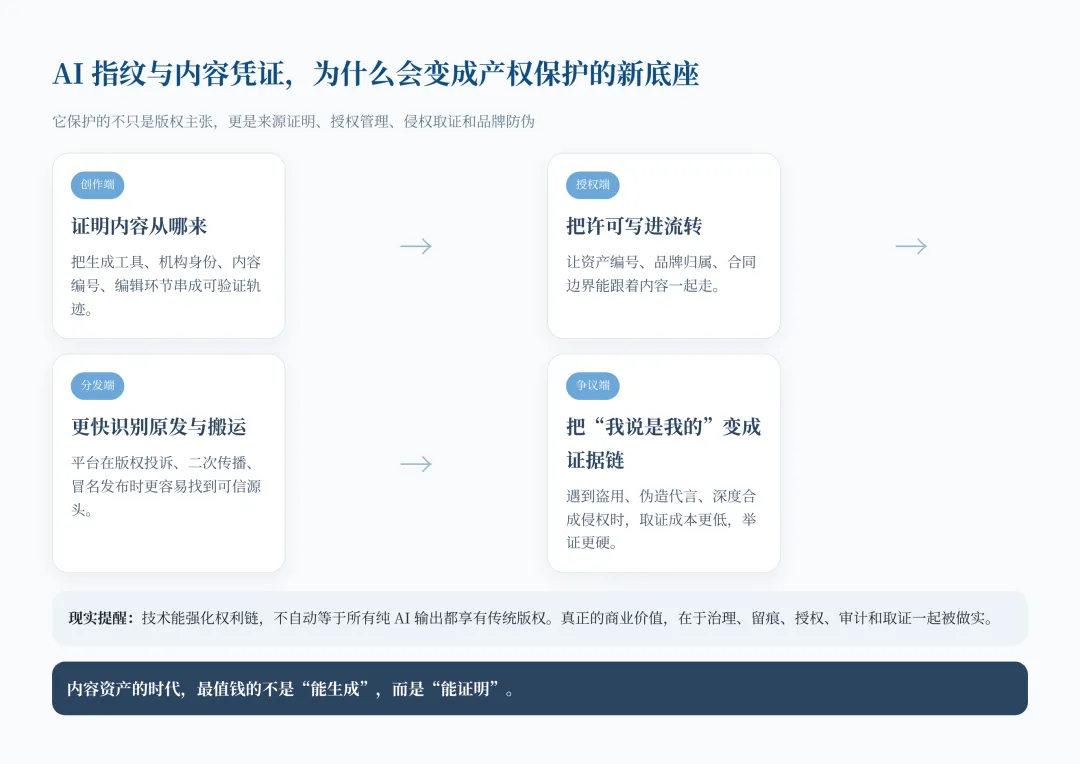
把这张图拆开,其实就是一句话:内容值不值钱,越来越取决于你能不能证明“它从哪来、谁动过、谁有权拿去卖”。
过去内容被搬运,创作者最痛苦的,不只是被偷。
是你明明知道东西是你做的,却很难拿出一条低成本、跨平台、可验证的证据链。
聊天记录不够硬。
PSD 源文件不一定愿意给。
对方改个尺寸、换个压缩格式、重新导一遍,你的取证成本立刻飙升。
如果媒体文件里天然带着来源声明、签名凭证、编辑轨迹和平台传播标识,情况就变了。
它至少能在几个环节上给权利人加护城河:
- 创作端
:能证明内容从哪个工具、哪个机构、哪个流程出来。 - 授权端
:能把许可范围、品牌归属、内容编号绑定到资产流转上。 - 分发端
:平台更容易识别“原发”和“二传”,版权投诉时不再只靠嘴说。 - 争议端
:一旦发生盗用、冒名、恶意深度合成、伪造代言,带溯源信息的文件会比一张孤零零的截图更像证据。
但冷水也得提前泼。
技术能保护“权利链”,不自动等于各国法律都会把纯 AI 输出认定成传统版权作品。
美国版权局 2025 年继续强调,纯 AI 自动生成的输出,若缺乏足够的人类作者性,版权保护空间依然很窄。
中国这边的司法实践则更看重“人到底有没有干活”。
北京互联网法院在 AI 文生图典型案例里明确过一条很关键的线:如果创作者在提示词选择、参数设置、反复筛选、审美判断和最终定稿上有足够的人类智力投入,作品获得著作权保护的空间会更大。
换句话说,美国更警惕“纯自动生成也想拿版权”,中国实践里则更强调“有人类实质选择与表达控制,就别把工具智能化当成一票否决”。
所以聪明的公司,不会只押注“版权”两个字。
它们会把这套技术同时用于品牌资产管理、合规留痕、合同履约、侵权取证和内容供应链审计。
这就从“法务成本”变成了“经营能力”。
那它能不能被绕过
能。
而且已经有人在绕。

把这张图再讲得落地一点,你就会发现:不同技术,死法完全不一样。
如果对手面对的是脆弱的显式水印,办法很多。
裁剪、重绘、局部修补、超分、二次压缩、重新录屏、翻拍屏幕,都可能让可见标识消失或者大幅减弱。
如果对手针对的是文件元数据,那就更简单了。
很多转码、社交平台另存、截图导出,本来就会把文件头信息洗掉。
鲁棒水印更难杀,但也不是铜墙铁壁。
强压缩、几何变换、噪声注入、再生成式后处理,都会拉低检出率。
学界这些年讨论得很多的对抗路线,核心也就两件事:要么把嵌入信号洗淡,要么逼检测器把假样本当真样本。
所以 Google DeepMind 在讲 SynthID 时,才会反复强调它不是银弹;Meta 在做 Video Seal 这类方案时,也会把“robustness under codecs and edits”当成核心指标,而不是把“绝不可能被绕过”当宣传口号。
而模型痕迹检测这条线,本身就存在误报与漏报的拉扯。
照片被多次美化、CG 和 AI 风格接近、老图反复压缩,都会把边界搅浑。
所以这个行业的答案,从来不是“能不能 100% 防绕过”。
而是:能不能把绕过成本抬高,把批量伪造的收益打低,把平台提示、取证和追责做得更顺。
这也是为什么主流方案越来越像“组合防线”:
显式标识负责提醒公众 隐式标识负责机器识别 内容凭证负责来源证明 平台风控负责传播处置 法规与合同负责处罚和追责
单点会被打穿。
体系更难被一把梭。
为什么你会被标成“可能由AI生成”,而不是“确定由AI生成”
这里面最有意思,也最容易被忽略的,就是那个词:可能。
平台用这个词,不只是为了留余地。
它本质上是在承认一件事:当前大量检测仍然是风险判断,不是司法鉴定。
平台可能读到了生成标识。
也可能没读到标识,但捕捉到了某些生成痕迹。
还可能是你自己点过“包含 AI 生成内容”,或者它从上游平台接收到了传播标记。
在中国现行规则里,这种“元数据没确认,但存在生成痕迹或用户声明”的场景,本来就允许平台做“可能为生成合成内容”或“疑似生成合成内容”的提示。
这不是羞辱你。
这是平台在给自己降风险,也是在给公众补知情权。
而从治理视角看,这个词反而说明系统还算克制。
因为真正负责任的平台,不会在证据不足的时候装作自己无所不能。
这行提示,未来会越来越常见
真正的拐点,不在模型能力继续暴涨。
而在于媒体世界正在从“默认信任内容本身”,切到“默认追问内容来历”。
今天被追问的是 AI 图。
明天会是 AI 音频、合成视频、数字人直播切片、自动生成的新闻摘要,甚至是被局部重写过的公开文本。
平台会越来越像海关。
没有单据的货,不一定当场没收。
但一定会被拦下来多看两眼。
如果你是普通创作者,这意味着一件事:以后做内容,不能只管生成,还要管来源、声明和留痕。
如果你是品牌方、媒体机构、MCN、律师事务所、教育机构,这意味着更硬的一件事:AI 内容治理不会停在“发不发”,而会深入到资产台账、证据链、授权链和供应链审计。
资料依据
中国:《人工智能生成合成内容标识办法》;欧盟:《AI Act》第 50 条;C2PA / Content Credentials 官网;Google DeepMind《SynthID》公开说明;Meta 公开的 Stable Signature / Video Seal 资料;美国版权局《Copyright and Artificial Intelligence》相关部分;北京互联网法院涉人工智能典型案例。
你现在最该担心的,也许不是平台给你的内容贴了一张“可能由AI生成”的标签。
而是当所有平台都开始追问“这东西从哪来、谁做的、改了什么”的时候,你的团队手里,居然还没有一套像样的内容留痕机制。
再直白一点。
明天回去别急着开会。
先做两件事:
第一,把你们所有对外发布内容的生成来源、编辑动作、授权状态拉一张表。 第二,规定以后所有 AI 参与生成的图片、视频、音频,必须保留原始导出文件和版本记录。
做不到这两件事,你今天嫌弃的是一行提示,明天填的就是整条证据链的坑。
如果你关心的不只是“哪个模型更强”,而是“怎样把 AI 做进业务、做成系统、做出可持续回报”,欢迎关注 Agi4us。
我们会持续分享 Agent 工程化落地、自动化工作流设计、企业级权限与审计治理、以及从试点走向规模化部署的方法论与案例。下一轮 AI 的赢家,不一定是最会喊口号的人,而更可能是最早把 AI 变成生产能力的人。
继续了解 AGI4US
欢迎在微信内搜索并进入 AGI4US 公众号主页,查看更多智能体方法论、案例与产品更新。
—— AGI4US 工作室设计:agi4us.C.A · agi4us.C.D
