夜雨聆风
夜雨聆风链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
https://www.mizhushare.com/docs/
在日常的数据分析工作中,我们常常需要将庞杂的原始数据按照某个维度进行“浓缩”,比如计算不同部门的平均工资、统计不同地区的销售总额。
SPSS中的【汇总】功能正是为此而生。该功能能够将数据按照指定的分组变量进行归类,并计算每个组内的统计量,从而生成一个更简洁、更易于分析的汇总数据集。
数据汇总:
数据汇总,也称为数据聚合(Aggregate),是指根据一个或多个分类变量(分界变量)对数据进行分组,然后对每组内的数值型变量计算指定的统计量(如平均值、总和、最大值等)。主要用于:
数据降维:将成千上万条原始记录压缩为几十条或几百条汇总记录,便于观察宏观趋势。 分组统计:快速获取不同组别的关键指标,以便进行横向对比分析。

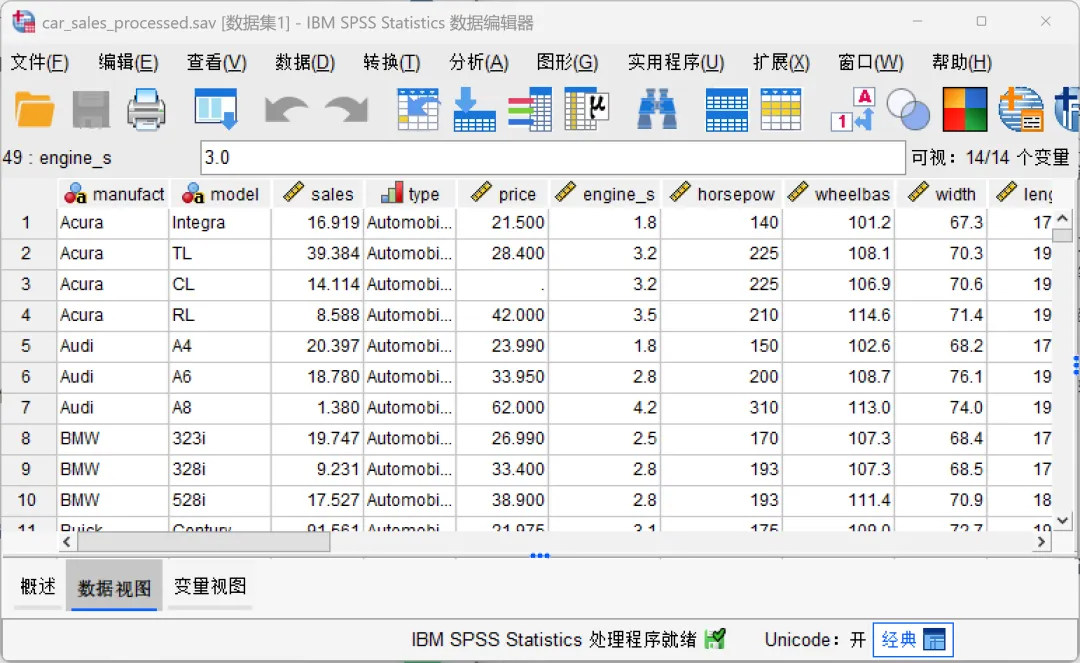
点击顶部菜单栏的【数据→汇总】,在打开的对话框中进行相应设置。
主对话框:
分界变量:数据分组的分类依据(支持数值型或字符串型变量),系统将根据这些变量的值,将原始个案划分到不同的组中。若选择了多个变量,系统将按照变量顺序进行层级分组,每个分界变量值的唯一组合定义了一个组。在生成新的汇总数据文件时,所有分界变量都会保留其原有的名称、类型及字典信息(如值标签)。
汇总变量:需要计算统计指标的源数值变量。通过将源变量与特定的汇总函数相结合,系统会计算出新的统计值,并生成对应的新汇总变量。
名称与标签:系统默认会为新生成的汇总变量分配标准化的名称。在「汇总变量」列表中选择目标变量,单击「名称和标签」按钮,可以设置新的变量名称以及添加一个描述性的变量标签。
个案数:自动计算并返回每个分组内包含的原始记录数量。常用于了解样本分布情况,是加权分析或评估数据代表性的基础指标。
保存:SPSS提供了三种保存汇总结果的方式。
①、将汇总变量添加到活动数据集:基于汇总函数的新变量将被添加到当前数据集中。数据文件本身不会被聚合,具有相同分界变量值的每个个案将获得相同的聚合变量值。
②、创建只包含汇总变量的新数据集:将汇总数据保存到当前会话中的一个新数据集中。该数据集包括定义汇总个案的分界变量以及所有由汇总函数定义的汇总变量。当前数据集不受影响。
③、创建只包含汇总变量的新数据文件:将汇总数据保存到一个外部数据文件中。该文件包括定义汇总个案的分界变量以及所有由汇总函数定义的汇总变量。当前数据集不受影响。
用于大型数据集的选项:对于非常大的数据文件,对已预排序的数据进行汇总操作会更高效。
①、文件已按分界变量进行排序:如果数据已经按分组变量的值排序,该选项可以使过程运行得更快并使用更少的内存。需谨慎使用该选项。
②、汇总前对文件进行排序:在极少数情况下,对于大型数据文件,可能需要在汇总之前先按分界变量的值对数据文件进行排序。除非遇到内存或性能问题,否则不建议勾选该选项。
汇总函数:
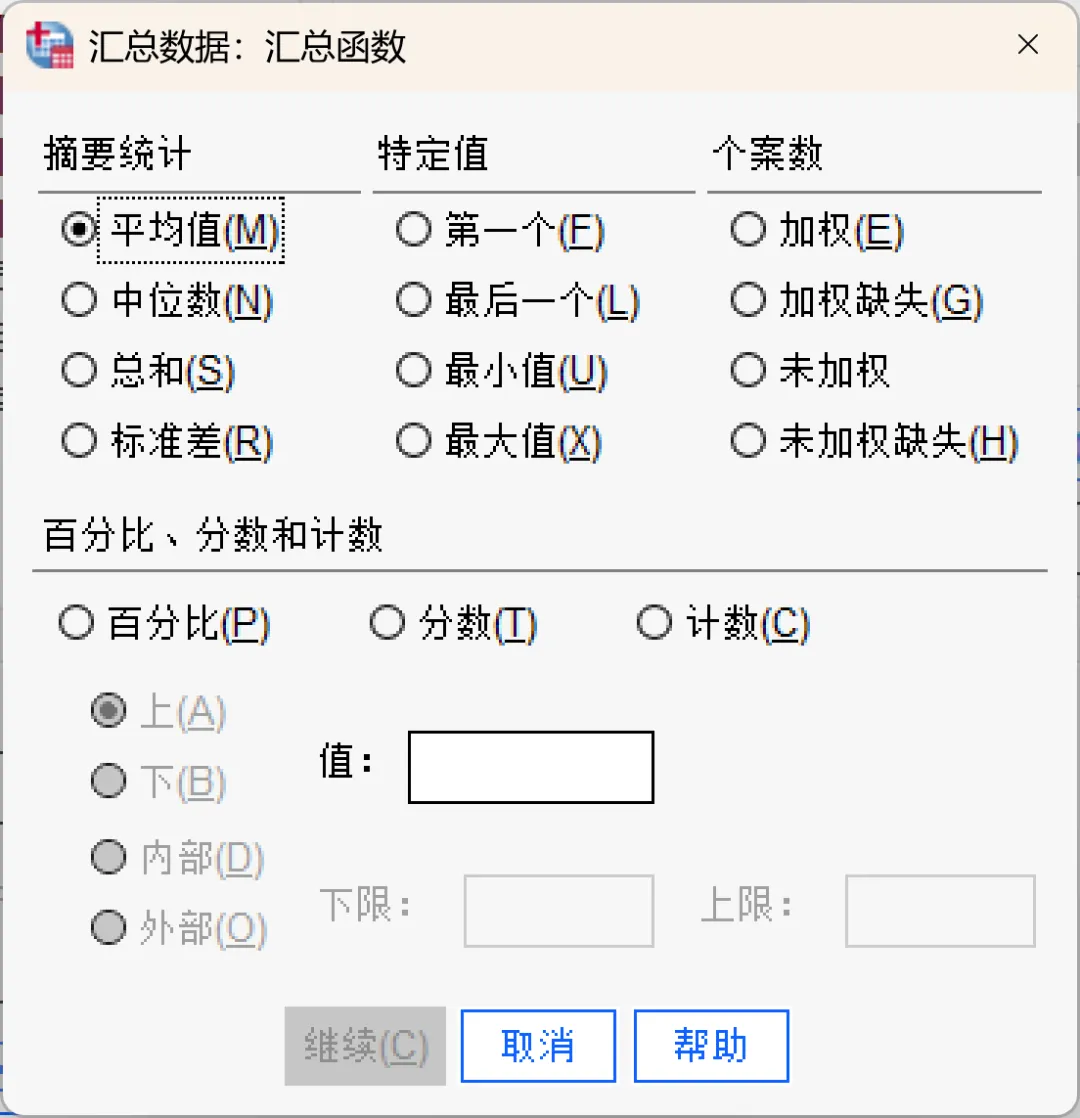
在「汇总变量」列表中,选择希望为其指定不同函数的变量,单击「函数」按钮。在「汇总函数」对话框中选择所需的函数,所选函数将被分配给「汇总变量」列表中选定的变量。可用的汇总函数包括:
数值变量的汇总函数:包括均值、中位数、标准差和总和;
个案数量:包括未加权个案数、加权个案数、非缺失个案数和缺失个案数;
高于或低于指定值的数值比例:包括百分比、分数或个数;
处于指定范围之内或之外的数值比例:包括百分比、分数或个数。
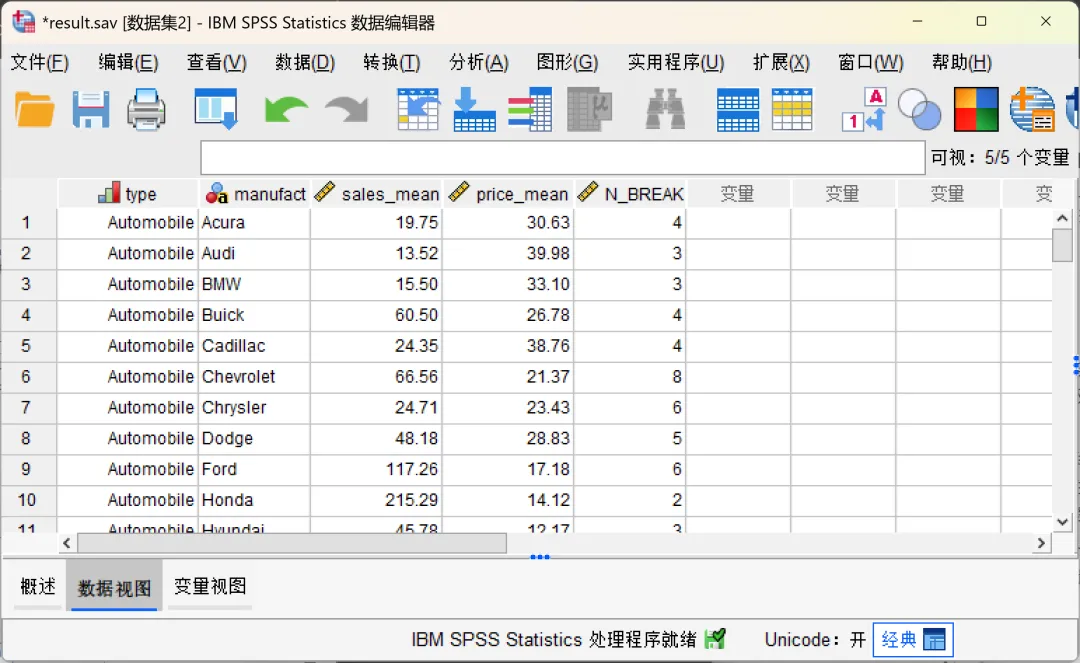
设置完成,点击确定,SPSS将执行汇总操作。打开保存的只包含汇总变量的新数据文件,在该文件中,数据结构清晰明了:
分组标识(前两列):展示了两个分界变量的所有唯一组合,明确了每一行数据所属的具体类别。
统计结果(中间两列):显示了对应汇总变量的计算结果。由于本次操作仅选择了平均值函数,因此这里呈现的是各组数据的算术平均数。
样本规模(最后一列):自动生成的个案数,直观地反映了每个分组中包含的原始记录数量,便于评估各组样本的代表性。